基礎力を伸ばす絶好の機会
年が明けて早2ヶ月が過ぎようとしていますが、2005年という1年間を振り返ってみると、技術的には大きなパラダイムシフトがない、言ってみれば「凪(なぎ)の一年」だったように感じます(注1)。今年も、今のところ目立ったパラダイムシフトの兆しは感じられませんので、凪はもうしばらく続くのではないでしょうか。
2005年が凪の1年だったことに起因するかどうかは計りかねますが、この1年で雑誌/書籍やWebサイトなどの各種メディアでは、上流工程や開発方法論、プロジェクトマネジメントといった要素技術ではない「広い視点」からのテーマや、非常にベーシックな技術テーマを取り上げることが多かったようです。凪の時期は新技術を学ぶことに追い立てられずに済みますし、何よりメディアにはベーシックな学習題材があふれています。この時期に基本スキルに磨きをかけない手はありません。
さて、今回解説する「DBをボトルネックにしないアプリケーション開発」というテーマも、この凪の1 年にならった非常にベーシックなテーマと言えます。とはいえ、世にリリースされる多くのシステムでは、DBがパフォーマンス上のボトルネックになるケースが少なくないようです。つまり、DBのパフォーマンスとは、技術論的には非常にベーシックであるにもかかわらず、多くの場合において「うまくやれていない」のです。
DBはなぜ重要なのか
DBは、業務システムの中核を担う存在です。DB マガジンにしても、DB 専門誌としてすでに6年以上も刊行を続けているそうですから、DBに関しては語るべき話題が豊富にあり、その需要もあるわけです。DBが「ずっと重要であり続けている」のは間違いありません。ドッグイヤー(はたまたラットイヤー)などと称されるこの業界では、これはすごいことです。RDBMSというものが(今のところは)この業界におけるワンアンドオンリーな存在だということがよく分かります。
しかし、DBがシステムのボトルネックになるケースが多いのも事実です。今回はその原因と対策を解説していきますが、まずはDBがなぜ重要なのか、また、DBはどのような特性を持っているのかをここで確認しておきましょう。
DBは業務システムの中核
そもそも業務システムでは、業務に必要な情報(データ)を抽出したり、業務の記録を記録したりすることが要件の大部分を占めています。つまり、DBのI/O処理が業務システムのほとんどを担っているといっても過言ではないのです(図1)。皆さんが現在携わっている、あるいは過去に携わった開発プロジェクトを思い返してみてください。データの参照および記録にまったく関係のない処理はおそらくほとんどないと思います。
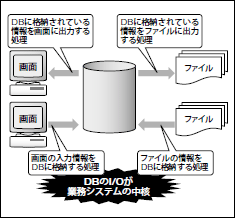
図1 DBは業務システムの中核
DBは情報を集約している
また、DBは業務に必要な情報を集約的に保持していることに価値があります。逆に、DBにデータを分散して保持させることは困難だとも言えます。
もちろん、現在リリースされているRDBMS製品は、パーティションやレプリケーションといったデータを物理的に分散させる機能を提供しています。しかし、DBの利用者から見ると、論理的には一元管理されているものとしてデータにアクセスしたいものです。例えば、「顧客マスタ」データが物理的にはマシンAとマシンBに分散配置されているとしても、「顧客マスタ」を扱うプログラムはマシンAとマシンB両方のデータを透過的に扱いたいはずです(図2)。
一方、処理プロセスは比較的分散が容易なものです(注2)。つまり、ある処理プロセスがマシン Aで動いてもマシンBで動いても、利用者にとっては別段問題ないわけです(図3)。
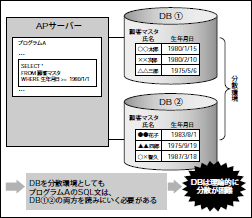
図2 DBは分散させるのが困難
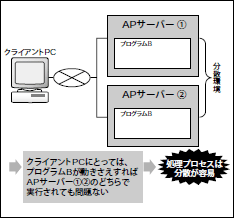
図3 処理プロセスは分散が容易
DBがボトルネックになるケース
いかがでしょうか。DBは理論的に分散できない存在であるにもかかわらず、業務システムの中核を担わなければならない、という二重の両立困難な要件を課せられた存在であることがお分かりいただけたと思います。そりゃあ、ボトルネックにもなりやすいというものです。
では、具体的にどのようなケースにおいて、DBがボトルネックになってしまうのでしょうか。以降では、DBがボトルネックになるケースを大きく3つに分類し、それぞれについて、その発生原因や背景について解説していきます。
なお、それぞれのケースに対する対策および解決の方法は、さらにその次の節にて解説します。
次節を読むと不安な気持ちだけが煽られてしまうかもしれませんが、どうぞ我慢して先へ読み進めてください。ちゃんと解決方法が記されていますので......。
ケース①:データ量増大によるパフォーマンス悪化
まずはシステム稼動後に、DBに格納するデータ量が徐々に増大していき、パフォーマンスが悪化していってしまうケースです(図 4)。このケースは最悪の場合、パフォーマンスが悪くなるどころか、ディスク容量が不足してしまうことになります。本番稼動後のシステムにおいて、DBサーバーのディスク容量不足が発生するとそれ以降、データの記録ができなくなってしまうわけですから、システムを利用して業務を行なっている現場は大混乱になります。ディスク容量不足に至らないにせよ、パフォーマンスの悪化は、少なくとも業務の現場に支障をきたしかねません。
また、このケースでは個別のプログラムやSQL文を多少直す程度の対策では解決を望めないことがほとんどですので、ハードウェア増強などによる抜本的な対応が必要となります。計画外の急なリソース増強は、システムの利用者にとっても運用者にとっても頭の痛いものですので、避けられるなら避けたいものでしょう。つまり、問題発生後の対処ではなく、事前の予測/対策が重要だと言えます。
また、このケースでは、システムをリリースした本番稼動直後は順調に動作し、しばらくしてから問題が発生することがほとんどです。そのため、開発プロジェクトで本番データ環境あるいはそれに相当する環境でしっかりテストを実施しても気づきにくいという、やっかいな問題もはらんでいます。
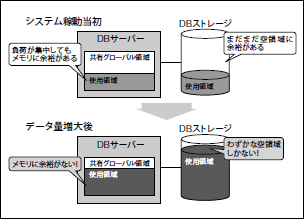
図4 格納データ量の増大に伴いパフォーマンスが悪化するケース
ケース②:DBクライアントがメモリを使い果たす
DBサーバーから見てクライアントに当たるノード(多くの場合APサーバー)のメモリが枯渇してしまうケースです。一見するとAPサーバー側の問題であり、DBがボトルネックとは思えないかもしれません。しかし、このケースもDBがボトルネックになっていると見るべきです。
具体例を挙げて説明しましょう。APサーバーから発行されるSQL文が、あるテーブルの全件を抽出するSELECT文だとしましょう。そのテーブルが100万件のレコードを有している場合、プログラムの実装(注3)によっては、APサーバーが100万レコード相当のメモリを消費することになってしまいます(図5)。
このようなSQL文がたかだか数回(場合によってはたったの1回)実行されるだけで、APサーバーのメモリは枯渇し、並行して実行されているほかのプロセスについても、パフォーマンスが低下してしまいます。ひどくなると、APサーバーがダウンするかもしれません。
このケースが発生する背景には2つの要因があります。1つは、設計ドキュメントの記述レベルです。昨今の設計ドキュメントには、「あるSELECT文を実行するプログラムがカーソルを使って処理するのか、あるいは一括でメモリに読み込むのか」という細かい実装方法までは記述しないことが大半でしょう。つまり、しっかり設計ドキュメントが作成され、それが適切にレビューされていたとしても、この問題を設計段階で発見することは困難だと言えます(注4)。
もう1つは、テスト実施時のデータ量が本番環境よりも少ないことです。ほとんどの場合、テスト実施段階では、実稼動環境でのデータ量よりも非常に少ないテストデータしか用意できません。データ件数が少ない環境では問題のあるSELECT文が発行されても、抽出されるデータがたいした件数にならず、メモリを過度に消費することはありません。
本番同等のデータ量でテストを実施できるのは、せいぜいリリース直前のテスト工程になってからでしょう(注5)。この段階になってから問題が発覚すると、スケジュール的には大事件です。改修作業と再テスト実施の工数を考えると、徹夜作業の連続は必至でしょう。
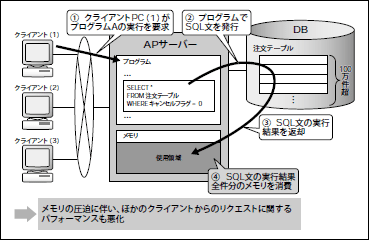
図5 DBクライアント(ここではAPサーバー)のメモリが枯渇するケース
ケース③:SQL文の実行がそもそも遅い
最後のケースは、前の2つに比べると非常にシンプルな問題で、「そもそもSQL文の書き方が悪く、実行すると遅い」というものです(図6)。
しかしながら、プロジェクト後半に実施するパフォーマンスチューニング作業では、この対策に大半の労力が費やされるのもまた事実です。むしろ、今回のテーマである「DBがボトルネックにならないアプリケーション」を構築するためには、このケースの解決こそが最重要ポイントと言えるのです。
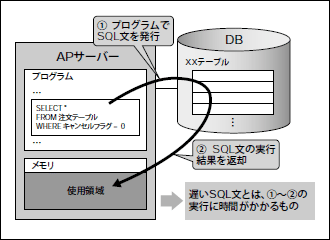
図6 SQL文の実行が遅いケース
●速いSQL文と遅いSQL文の違い
遅いSQL文は、どうして遅いのでしょうか。原因もシンプルなら、その答えもまたシンプルです。SQL文実行時のアクセスパスが適切でないからです。
SELECT文が発行されてからその結果が返されるまでに、RDBMSは実にさまざまな処理を行なっています。誌面に限りがありますのでごく簡単に解説しますが、大枠では図7のような処理が行なわれます。ここで問題になるのは、「②アクセスパス決定」の部分です。アクセスパスを決定するとは、「あるSELECT文の実行結果を抽出するまでに、どのようにして、またどの順番でデータにアクセスしていくか」をRDBMSが決めることです。具体的には、以下のようなことを決定しています。アクセスパス決定の例として、図8も併せてご覧ください。
- データアクセスの開始点となるリソース(テーブルまたはインデックス)の決定
- 開始点の次にアクセスするリソースの決定
- 開始点と次点の結合に関するアルゴリズムの決定
- 以降、アクセスする必要がある全リソースに達するまでの結合順序、およびアルゴリズムの決定
なお、RDBMSのアクセスパス決定ロジックは、カーナビにたとえると理解しやすいと思います(コラム「RDBMSとカーナビは似ている?」を参照)。
大雑把ではありますが、テーブルではなくインデックスにアクセスし、なおかつ読み込むレコードの件数が少なく済むのが「速いSQL文」になり、逆にインデックスが使われなかったり、読み込むレコードの件数が多かったりすると「遅いSQL文」になります。

図7 SQL文が発行されてから結果が戻されるまでの処理の流れ
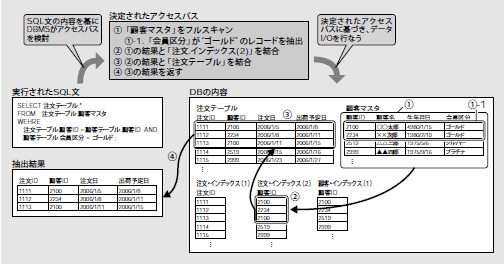
図8 アクセスパス決定の例
●速いSQL文を作るのは難しい
さて、かなり端折ってもこれだけ説明が必要なことからも想像されると思いますが、RDBMSは実は裏で高度で複雑な処理を行なっています。コラムに記したカーナビの「ルート検索」と同じく、RDBMSのアクセスパス決定もやはり芸術作品の粋に達していると感じるほどです(注6)。
そして、速いSQL文を書くためには、複雑なアクセスパス決定の理論を分かった上で、適切なパスを通るSQL文を考えなければなりません。これには、それなりの知識と経験を必要とします。
しかし、SQLの文法は良くも悪くも非常に直感的で分かりやすいので、仕様どおりの結果を得るSQL文であれば、裏で動く難しいアクセスパスの決定ロジックを意識することなく、簡単に書けてしまいます。
そのため、仕様どおりに動きはするものの遅いSQL文がすぐに作成されるという状況が生まれるのです。
●テスト段階では遅いSQL文を発見しにくい
さらには、ケース②でも挙げた「テスト環境は本番よりもデータ量が少ない」という要因も、このケースを回避しにくいものにしています。アクセスパスが適切でない遅いSQLも、データ量が少ないとせいぜいマイクロ秒単位の遅れにしかならないため、体感できるレベルの遅さにはならず、発見が遅れてしまいます。システムの本番稼動後になるまで発覚しないことすら、ままあります(図9)。

図9 データ件数の少ないテスト段階では遅いSQL文が浮かび上がらない
●SQL文の多さが困難に拍車をかける
このケースを回避しにくい背景には、アプリケーションが発行するSQL文の数の多さもあります。
100画面と10本のパッチプログラムから構成される中規模システムを例に、作成されるSQL文の数を考えてみましょう。1つの画面を表示するのに、平均3種類のSQL文が発行され、画面に配置されたボタンやリンクの押下などによって、平均5種類のSQL文が発行されるとします。また、バッチプログラム1本あたり、平均10種類のSQL文が発行されるとします。 試算してみると、このシステムで作成されるSQL文は合計900種類にもなります(図10)。
一般的には、プロジェクトが佳境の時期に短期間の「パフォーマンスチューニング工程」が用意されていることが多いと思います。しかし、その短期間で900本という大量のSQL文から、埋もれている遅いSQL文を探し出して1つずつチューニングするという、あたかも"森に隠れている木を探す(注7)"かのような途方もない作業を完遂するのは、土台無理な話というものです。

図10 中規模システムでのSQL文の本数を試算
DBをボトルネックにさせないアプリケーション開発とは
お待たせいたしました。ここからは先に挙げたDBがボトルネックになるケース①~③の対処方法を解説します。お気づきの方もいると思いますが、ケース①とケース②・③は、大きく性質が異なります。当然、その対策方法も変わってきます。
ケース①は、システムに対するデータ量の増加予測などの「キャパシティプランニングの問題」と言えます。プログラムやSQL文の出来の良し悪しにいくらこだわったところで、ケース①の問題は発生し得ます。一方、ケース②・③は、「個々のプログラムやSQL文などの出来の良し悪しに関する問題」と言えます。キャパシティプランニングをどんなに正しく行なったところで、プログラムやSQL文の出来が悪ければケース②・③の問題は発生します。
ケース①の対策:キャパシティプランニング
①の対策を一言で述べると、「キャパシティプランニングをしっかり行なうこと」に尽きます。
これを読んで、「ああ、キャパプラね。たしか要件定義書のキングファイルにそんなものがあったような気がするけど、開発工程が始まってからは誰も読んでないなぁ。メンテナンスもされていないみたいだし......」なんて思う人はいませんか。そんなプロジェクトこそ、リリース後にケース①の問題が発生してしまう可能性がありますので要注意です。
せっかく行なったキャパシティプランニングの結果を「キングファイルの肥やし」としないために、そして何よりケース①の問題を発生させないためにも、キャパシティプランニングをなぜ行なうか(why)を認識した上で、いつ(when)、誰が(who)、何を行ない(what)、そしてそれを後工程でどのように活用していくのか(how)を、しっかり理解することが大切です(注8)。
なお、ここで論じるキャパシティプランニングは、DBに関する領域、とりわけケース①の解決に直結するポイントである「データ量」に絞って解説します。実際のキャパシティプランニングでは、DB以外の要素(アクセスが集中する時間帯やトランザクション量など)も検討する必要があります。
COLUMN RDBMSとカーナビは似ている!?
RDBMSにおけるアクセスパス決定ロジックは、カーナビのルート検索のようなものです。目的地を設定(SQL文を発行)すると、到達するまでに通るべき道筋(アクセスパス)を決めてくれます。
またOracleの場合、ヒント句を用いてアクセスパスを強制的に指定することも可能です。カーナビで言えば、目的地に到達するまでの道筋に対して経由地(特定の交差点など)を指定する機能といったところでしょうか(図A)。
余談ですが、最近のカーナビは非常に賢いですね。ソフトウェア技術者の視点で見ると、芸術作品の粋に達していると思うのは筆者だけでしょうか。
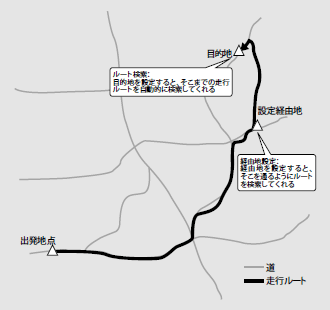
図A カーナビのルート検索と経由地設定機能
キャパシティプランニングの目的と活用方法
まずは、データ量に関するキャパシティプランニングを行なう目的(why)と活用方法(how)について考えてみましょう(図11)。
1つ目の目的として、顧客と開発者の双方が「システムで扱うデータのボリューム感についての共通認識を持つ」ことが挙げられます。顧客と共通認識を持つことによって、後の工程で論点を合わせることができるようになります。例えば、ハードウェアスペックを見積もる際に、「このぐらいのデータ量を扱うシステムなのだから、このぐらいのスペックは必要ですよね」といった具合に、共通見解に基づいた建設的な議論が可能になります。
2つ目に、キャパシティプランニングの結果は、後の開発工程でプログラムやSQL文のパフォーマンスを考慮する際の基礎データとして利用できることがあります。「顧客の合意を得られたデータ量予測に関する具体的な値」は、本番稼動後にシステムが保持するデータ量の傾向を想定する上で唯一無二の存在ですので、これを有効活用しない手はありません。
例えば、テーブルの物理設計で非正規化を検討する際に、データ量の多いテーブルが保持する属性を、データ量の少ないテーブルの派生属性としたり(図12)、データ量が多いテーブルを、テーブルフルスキャン(注9)を絶対に避けなければいけないテーブルとして規定したりできます。こうした事前対策を施しておけば、パフォーマンスチューニング工程を"森に隠れている木を探す"かのような途方もない作業とせずに済むのです。
3つ目の目的は、開発工程やシステム稼動直後といった「短期的な視点」ではなく、稼動数年後という「長期的な視点(注10)」でのデータ量を予測することです。長期的な視点でデータ量を予測する理由は単純明快で、ハードウェアを正しく見積もるためです。
ここで注意すべきなのが、キャパシティプランニングを行なったからといって、ケース①の問題が絶対に起こらないわけではないという点です。キャパシティプランニングは「システムでどんな機能を使うと、どのようにデータが登録されるのか」という設計的な側面と、「業務のボリュームと、長期的視点に基づくその増加曲線の予測」という業務的な側面の 2点を"仮定"します。そして、ハードウェア見積もりは、この"仮定"を前提条件として行ないます。
ハードウェア見積もりが"仮定"を前提としている以上、キャパシティプランニングの成果物は「なぜそのように仮定したのか」という点を論拠することが重要です。そして、以降の工程では、この仮定にブレが出ていないかを継続的にチェックすることが重要と言えます。
しかし、ケース①の問題が発生するプロジェクトの成果物では、"仮定"に基づく結果であるハードウェアスペックだけが突然語られることが多いようです。そのようなプロジェクトでは、前提条件である設計的側面や業務的側面に変動があっても、それを察知できません。その結果、キャパシティプランニングを行なっているにもかかわらず、ケース①の問題が発生してしまうのです。
なお、設計的側面と業務的側面の想定がブレていないかをチェックするのは、開発工程だけではなく、本番稼動後も重要になります。運用計画においても、この点を重視する必要があります。
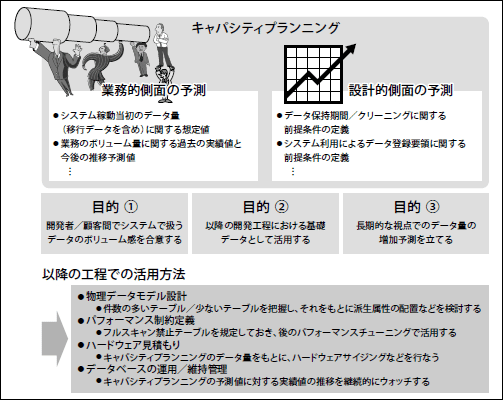
図11 キャパシティプランニングの目的と活用方法
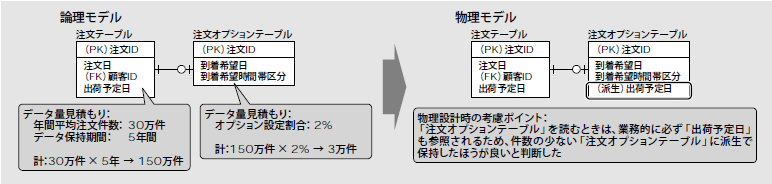
図12 データ量の多いテーブルが保持する属性をデータ量の少ないテーブルの派生属性にする
キャパシティプランニングではいつ誰が何を行なうべきか
次に、先に挙げた目的を達成するために、キャパシティプランニングはいつ(when)、誰(who)が行ない、具体的には何を(what)すべきかを解説しましょう。
まず「いつ」行なうかですが、例えば、ハードウェアの見積もりは要件定義フェーズの成果物として求められることが多いので、キャパシティプランニングはそれより前に実施します。また、テーブルの物理設計のインプットとしても利用することから、最低でも基本設計フェーズ中には行なっておくべきです。
次に「何を」すべきかですが、図11の「以降の工程での活用方法」に挙げた作業で利用できる成果物を作成する必要があります。キャパシティプランニングに関する成果物の目次例を図 13に示します。
最後に誰(who)が行なうかですが、担当者には図 13のような成果物を作成できる能力が必要です。さらに、必須ではありませんが、以降の工程でキャパシティプランニングの結果を直接活用する人、例えば「テーブルの物理設計」「ハードウェア見積もり」「パフォーマンスチューニング」「DBの運用/維持管理」などの作業に携わる人のほうが、より適任でしょう。
具体的に言うと、図13のような成果物を作成するためには、当該システムが利用される業務の背景を知っており、業務要件の大枠を理解できている必要があります。さらに、概念データモデルや論理データモデルも理解していなければなりません。これらの知識を備えている人であれば、顧客と"業務の言葉"でコミュニケーションしつつ、業務要件からシステムでデータをどう保持するかを読み取って、キャパシティを正しく見積もることができるでしょう。
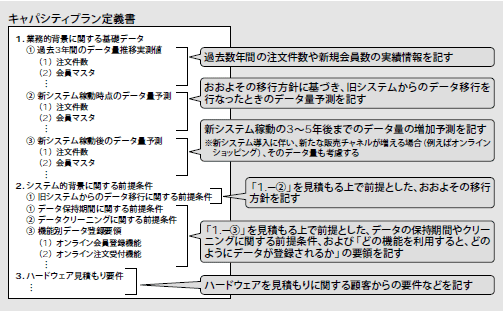
図13 キャパシティプランニングに関する成果物の目次例
ケース②・③の対策: DB専任担当者の配置
続いて、ケース②「DBクライアントがメモリを使い果たす」と、ケース③「SQL文の実行がそもそも遅い」に関する対策を紹介しましょう。
ケース②・③の対策では、「個々のプログラムやSQL文を、適切なパフォーマンスが出るように実装する」という地道な作業を、ただひたすらに積み上げることが求められます。しかし、先に述べたとおり、「テスト実施時のデータ量の少なさ」「設計ドキュメントをレビューしても発見できない」「速いSQL文を書くには知識と経験を要する」などが原因や背景にあるため、単純には対策が打てません。また、プログラムやSQL文の多さが"木が森に隠れる"状況を生むため、パフォーマンスチューニング工程でまとめて対策を打つのも妥当ではありません。
ケース②・③の解決を図るには、図14に示した因果関係の根本要因に対して解決策を打つ必要があります。これを行なうのが、「DB専任担当者(注11)」という役割です。それでは、DB専任担当者の役割について、詳しく見ていきましょう。
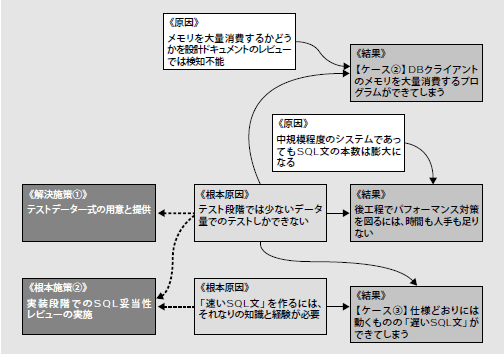
図14 ケース②・③の因果関係
DB専任担当者の役割①:テストデータ一式の作成と提供
DB専任担当者が果たすべき役割の1つが、テストデータ一式を作成し、それをプログラム開発者に提供することです。これにより、プログラム開発者は、提供されたテストデータ一式を用いてテストを実施できるようになります(図 15)。
ここで重要なのが、どのようなテストデータを用意すべきか、という点です。図14からも分かるように、ここでテストデータ一式を作成するのは、「メモリを大量に消費するプログラム」や「遅い SQL文」を検知するためです。
これらを検知するためのテストデータである以上、それなりの量を用意する必要があります。前述のキャパシティプランニングで「どのテーブルのデータ量がどの程度か」を見積もっているはずですので、実稼動環境に近い傾向のデータ量を用意できると良いでしょう。とはいえ、基幹系システムともなれば、実業務では100万件を軽く超えるデータ量を扱いますので、これと同等の件数を用意するのはさすがに難しいと思います。そのため、遅い SQL文の"遅さ"が体感できる程度の件数として、おおよそ2~3万件を用意するのが妥当です。
また、当然ですがこのテストデータ一式は、プログラムが仕様どおりに動くかどうかを検証するためにも使われます。DB専任当者は、データモデルの構造を理解し、実際にシステムに登録され得る形式でテストデータを作成する必要があります。
なお、このテストデータ一式をいつ、誰が作るかについては、キャパシティプランニングを担当した人がそのままDB専任担当者の役割を引き受けて、基本設計工程(実装工程が始まる前)でテストデータ一式を作成するのが良いでしょう。
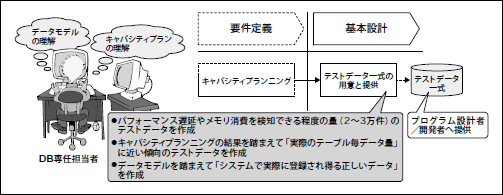
図15 テストデータ一式の作成と提供
DB専任担当者の役割②:SQL文の妥当性をレビューする
DB専任担当者の役割にはもう1つ、「プログラム開発者が作成したSQL文をレビューして、実行計画が適切かどうか、大量の結果を返すSQLではないかどうかを確認する」ことがあります。
この確認作業は、後のパフォーマンスチューニング工程でまとめて行なうのではなく、実装の真っ最中に実施する点がポイントです(図16)。たとえ適当な量のテストデータをプログラム開発者に提供していても、そもそも速いSQL文を書くには知識と経験を要するわけですから、遅いSQL文を完全になくすことはできません。そこで、DB専任担当者はSQLのパフォーマンスに関するアドバイザとして、実装作業中のプログラム開発者に対し、作成されたSQL文の妥当性レビューを行ないます。
レビューでは、見直しが必要な「不合格SQL文」と、問題のない「合格 SQL文」に分類します。ここでも、先のキャパシティプランニングの結果が役立ちます。「データ量が多く、フルスキャンを絶対に回避すべきテーブル」(以下、フルスキャン禁止テーブル)とそうではないテーブルが判明していれば、フルスキャン禁止テーブルにアクセスするSQL文を見つけて重点的にレビューすることができます。フルスキャン禁止テーブルかどうかの境界線上(注12)にあるテーブルにアクセスするSQL文でフルスキャンが発生している場合には、「システムでどのような操作を行なうと実行されるSQLなのか」「その画面の業務的な実行頻度はどの程度か」をプログラム設計者や顧客にヒアリングし、実行頻度が高い場合には不合格SQL文に分類します。
次に、DB専任担当者は不合格SQL文に対する対策を検討します。まずは、プログラムの設計者および開発者と、SQL文やプログラムを見直すことでパフォーマンスの向上が望めないかどうかを相談します。SQL文やプログラムの見直しでも回避できないとなった場合、DB専任担当者はインデックスの見直しを検討します。
ここで重要なのが、インデックス設計はDB専任担当者が担当すべきという点です。筆者が以前関わったプロジェクトでは、実装フェーズに入る前の物理データモデル設計時にインデックス設計も併せて行なっていました。そのプロジェクトでは、プログラム開発者には「インデックスが使われるように実装をすること」を告知しただけで、プロジェクト後半のパフォーマンスチューニング工程まで実行計画の検証は特に行なわれませんでした。その結果、パフォーマンスチューニング工程で、あるSQL文のパフォーマンス向上のためにインデックスを見直したら別の SQL文のアクセスパスが悪くなってしまうという、あっちを立てたらこっちが立たない状態となり、パフォーマンスチューニング工程はものの見事に泥沼にはまってしまったのです。
筆者は、インデックス設計について「使われることを予測してあらかじめ設計する」アプローチよりも、「実際に作られた膨大なSQL文に合わせて設計していく」アプローチのほうが適当であると考えます。このアプローチでインデックス設計を担当できるのは、DB専任担当者だけでしょう。
DB専任担当者は、このような「実装の真っ最中に適切なパフォーマンスが得られることを検証しながらシステムを構築する」手法を確立するためのキーパーソンなのです。
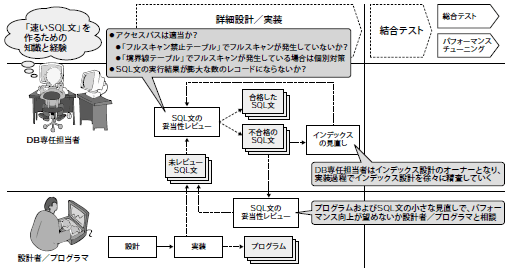
図16 実装段階でのSQL文と妥当性レビュー
おわりに
最終回のテーマ「DBをボトルネックにさせないアプリケーション」についての説明は以上です。根深い問題のため、非常に駆け足になってしまいましたが、開発の現場を助けるきっかけになれば幸いです。
2005年5月号より、アプリケーション開発に携わる方の現場ですぐに使えて長く役立つ記事を目指し、毎号テーマを変えつつ執筆してきましたが、いかがでしたでしょうか。筆者らにとって連載中のこの1年は、とても長かったようにも短かったようにも感じます。毎号ハラハラ(この最終回の原稿も......)させてしまった編集部の皆様、そして何よりご愛読いただいた読者の皆様には、語りつくせぬ感謝の気持ちでいっぱいです。本当にありがとうございました。また、お会いましょう!!
- 注1:インパクトの大きい新技術が登場しないという意味では凪だったかもしれませんが、筆者は大時化プロジェクトにハマってしまいましたので、決して穏やかな1 年ではありませんでした......。
- 注2:もちろんプロセスの分散においても、「セッションの管理」「フェイルオーバー」などの問題を解決しなければなりませんが、今回のテーマから外れた議論になりますので、ここでは割愛します。
- 注3:カーソルを移動しながらカレントレコード(およびその前後程度のレコード)のみをメモリにロードするような実装ならば問題ありませんが、SELECT文の結果をごっそりメモリに展開するような実装だと、この問題が発生します。
- 注4:短絡的に考えれば、設計ドキュメントを「カーソルを使って読み込むのか、一括で読み込むのか」という詳細レベルまで記述するようにすれば良い、と考えがちですが、昨今の短納期/低予算な開発プロジェクトでは、そう簡単にいかないのが実情です。そこまで詳細な記述を設計ドキュメントに求めると、物量的に作成する時間も暇もありませんし、作成後のメンテナンスもままならなくなってしまいます。
- 注5:本番同等のデータ量でのテストを実施できないままリリースを迎えざるを得ない、強行軍スケジュールのプロジェクトもあるでしょう。
- 注6:特に、昨今のコストベースエンジンの進化には目を見張るものがあります。何しろ、一昔前までは「コストベースエンジンは使い物にならない」が通説だったものです。
- 注7:"木を隠すには森"をネガティブな意味に言い換えているだけです。深い意味はないのであしからず......。
- 注8:一般的な 5W1Hのうち、どこで(where)の議論が抜けていますが、当然「開発プロジェクトの現場で」行なうものですので省略しました。
- 注9:インデックスを使わずにテーブル全体を読み込むアクセス方法。基本的には、データ量の多いテーブルをフルスキャンすると「遅い SQL文」になってしまいます。
- 注10:長期的な視点とはいえ、10~ 20年というスパンではさすがに長すぎます。多くの場合、10年後の予測は現実味がありません。3年から 5年くらいが妥当と言えるでしょう。
- 注11:「DB管理者(DBA)」と呼んでも差し支えありませんが、 DBAというと「運用段階に入ってからのバックアップ/リカバリやスキーマ管理を行なう役割」を発想してしまいそうなので、ここでは別の役割名を付けました。
- 注12:導入するハードウェアのスペックなどにもよりますが、おおよそ 1万件~10万件程度のテーブルだと思ってください。
石川智久(いしかわともひさ)
元々はテーブル設計が得意分野だったが、より概念的な方向に興味を持ちはじめ、アナリシスパターン的な世界へ徐々に移行中。一方で、アーキテクトとしてプロジェクトに参加する機会も増え、自分が「アーキテクト」なのか「モデラー」なのか分からなくなっている。中堅SIerを経て、2002年より現職。
高橋英一郎(たかはしえいいちろう)
JavaによるWebアプリケーション開発一筋で生計を立てている。現職では商用J2EE Webアプリケーションフレームワークの開発に従事。いかにして楽に Webアプリケーションを構築するか、日夜頭を悩ませている。
山本啓二(やまもとけいじ)
関東在住の阪神ファン兼コンサルタント。日本シリーズ観戦成績が、3年越しで4連敗となりました。ロッテの強さは本物ですね。でも、今年4勝して5割に戻す予定です。著書に『プログラマの「本懐」』(日経BP社刊)