XML-DBとは何か
データベースとは、そもそもデータを格納し操作する仕組みのことを言う。「大量のデータから効率良く目的のデータを検索したい」。そんな目的から生まれたものだ。そのため、XMLデータベース(以下、XML-DB)を簡単に説明すれば、「大量のXMLデータを格納し、効率良く操作できる仕組み」ということになる。
XML-DBもリレーショナルデータベース(以下、RDB)もデータを格納し操作する点では同じだが、異なるのは扱うデータの構造だ。
RDBに格納するデータは「リレーショナルデータ」と呼ばれる表形式のデータになる。これに対して、XMLデータのデータ構造は「階層型」である。
XMLデータは、データの要素を「タグ」という記法で記述し、その要素を入れ子にすることで階層構造を表現できる。タグを見るとHTMLと同じように見えるが、HTMLは使用できるタグが決まっているのに対し、XMLは自由にタグを設定し使うことができるという違いがある。
階層構造で表現できるものには、WordやPowerPointのアウトラインで示されるドキュメントの構造や、会社の組織図、オブジェクト指向言語のクラス階層など、さまざまなものがある。自由にタグを設定し、階層構造を表現できるXMLは、これらのデータを表現するのに向いている。リレーショナルデータでは、このような階層構造を表現するのは難しい。XML-DBは、このXMLデータの階層構造を活かした形で格納できるデータベースなのである。
XML-DBの2つのタイプ
XML-DBには大きく分けて「ネイティブ型」と「ハイブリッド型」の2つのタイプがある。ネイティブ型はXMLデータを扱うことに特化したもので、ハイブリッド型はRDBにXMLデータを扱う機能を追加し、2つの機能を統合したものだ。
しかし、この2つのタイプの違いはこれだけではない。ネイティブ型は、特に大量のXMLデータを格納し、高速に検索したいという要件に向いた構造を持っている。今日ではテラバイト級のデータを扱えるネイティブ型の製品も登場している。また、インデックスを自動で設定するなど、エンジニアを悩ませずに気軽に扱えるという利点もある。
一方のハイブリッド型は、主にRDBのデータを使うが、XMLデータも併せて使いたい場面にその威力を発揮する。RDBと同様に検索と更新のバランスを考えながらインデックスを設定する必要があるが、その分トランザクション処理が多いシステムにも向いていると言えるだろう。
この2つのタイプは使用する目的に応じて利用するため、どちらが優れているのかは一概に言えるものではない。
XML-DBで管理するデータ
XML-DBを説明するにあたり、取り扱うデータが必要だ。今回は、XMLデータとして企業の各部門の「週報」を取り上げることにする。このデータを用いて活動報告を管理することを想定して解説を進める。
まずはそのデータを見ていただきたい。図1-A、図1-Bに示したのは、週報の構造をXMLで表現したものだ。図1-A は営業部門、図1-BはSE部門の週報になる。
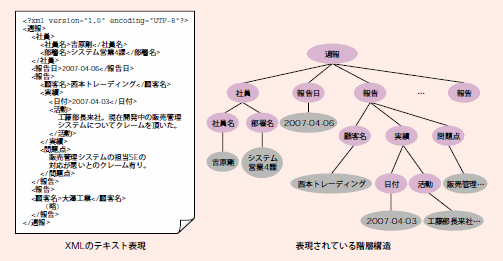
図1-A:営業の週報データ
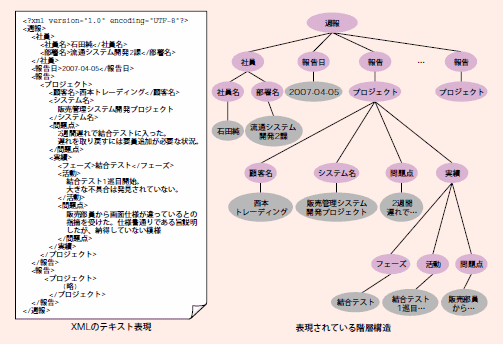
図1-B:SEの週報データ
週報は言うまでもなく、その週に行なった活動について報告するものだ。多くの場合、顧客やプロジェクトなどの項目に活動を分類して書くので、階層構造になることが多い。各自が提出する週報はそれぞれ小さな情報に過ぎないが、横断的に企業内すべての部門の週報を集めれば、会社全体の現状を把握するのに役立つ。
例えば、複数の営業所での活動を取り出して集計することにより、全社的な営業活動の状況をリアルタイムで知ることが可能になる。また、同じ顧客を担当する営業とSEなどほかの部門からのレポートをいっしょに参照できれば、会社全体にどのような問題点があるのかを早い段階で関係者と共有することが可能になる。これらを実現するには、週報データをデータベースで一元管理する必要がある。
一般的に週報のフォーマットは、各部門において局所最適になるように決められているため、部門ごとに異なる報告項目を持つことが多い。図1-A、図1-Bの週報データを見比べてほしい。同じ週報データだが、営業とSEの週報は異なった構造になっている。
図1-Aの営業の週報は基本的には顧客単位で記述しているのに対し、図1-BのSEの週報にはプロジェクト単位で活動を記述している。また、図1-Bではプロジェクトをさらに部門固有の要素であるフェーズごとに分けて進捗状況が記述されている。さらにそれぞれの階層で問題点も記述されている。
このような構造のバリエーションを持ったデータをどのように一元化するかが、全社の週報を活かすためのカギになる。
半定型文書とRDBの限界
部門ごとに異なる報告項目を一元管理する場合によく行なわれるのが、自由なテキストで記述できる「その他」のような項目を設けて、部門ごとに使い方を決めるやり方だ。これにより、同じ部門内であれば必要なメッセージがどこにどのように書かれているかを理解できる。
しかし、このやり方では部門外から「その他」に何が入っているか分からないために情報を取り出すことができず、部門間をまたがる自動処理は非常に難しい。かといって「その他」ではなく自動処理で情報を取り出せるような項目を設けても、RDBのスキーマ設計が問題となる。
単純に考えれば、社内のすべての部門でどんな報告書のニーズがあるかを把握し、それをすべて表現できるスキーマを作れば良いのだが、それは現実的に不可能に近い。「その他」であればテキスト型のカラムを1つ用意すれば良いが、膨大な量の項目を洗い出して、それぞれについてデータ型やサイズなどを決めなくてはならないからだ。
週報データのようにおおよその構造は同じだが、細かくいろいろ変わるデータのことを「半定型文書」と言う。RDBでは、半定型文書の処理は難しいのだ。実は、この難問をクリアするための仕組みがXML-DBなのである。その理由は以降で解説する。
IBMのDB2 9はRDBの機能にXMLデータを扱う機能「pureXML」が追加された、ハイブリッド型データベースである。内部にXML-DBを持ち、XML型というデータ型を使用することでXMLデータをネイティブに扱うことができる。
本パートでは、このデータベース製品の最新バージョン「DB2 9」の開発者向け無償版「DB2 Express-C V9.1 for Windows」(以下、DB2 Express)を用いて、XML-DBの基本的な使い方や操作について解説する(注1)。特定製品に縛られないXML-DBの使い方を理解できるように、ネイティブ型とハイブリッド型の違いについても触れながら解説していく。
XML-DBを扱うための操作ステップ
XML-DBの操作には、大きく分けて次のステップがある。
- データベースを作成する
- スキーマを定義する(オプション)
- XMLデータを登録する
- XMLデータを検索する
- インデックスを作成する(オプション)
- XMLデータを更新する
- プログラムから呼び出す
各操作ステップにおける細かい操作は製品によって異なるが、上記操作の流れはどのXML-DBでもほぼ共通である。「オプション」とあるものは、XML-DB製品によっては不要になるステップだ。
これら操作ステップを見ていただくと、RDBと共通するところが多いことに気づくだろう。異なるのは省略しても良いオプションの操作ステップがあるところだ。XML-DBでは、このオプションの操作をしなくても実用的なシステムを構築できる点が特徴である。特に、スキーマの定義をせずに使えるデータベースというのは、RDBの常識から考えるとあり得ないものだ。
ここまで分かれば、あとは実践するだけ。早速、この流れに沿ってXML-DBを使ってみることにしよう。
STEP1 データベースを作成する
XML-DBを使うためには、最初にデータベースの作成が必要だ。多くの製品ではGUI のツールが用意されており、容易にデータベースを作成できる。
画面1 にDB2 Expressのデータベース作成時の画面を示す。画面1 でデータベース名と物理的なストレージ作成場所を指定するだけでXMLデータを格納するデータベースを作成できる。そのほかの設定項目はデフォルトのままでも問題ないが、必要であればストレージの追加などの設定も可能である。
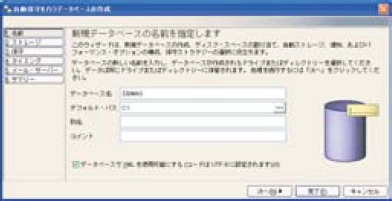
画面1:データベースの作成
ほかのXML-DB製品でもデータベースの作成方法は基本的に同じであるが、中にはインストールをすれば自動的にデータベースを作成する製品もある。
データベースを作成すれば、そこにXMLデータを登録できるようになる。
STEP2 スキーマを定義する(オプション)
次にデータベースのスキーマ定義を行なう。XML-DBでのスキーマは、XML SchemaやRELAX NG、DTDなどで定義したデータ構造のことを指す。RDBでは、スキーマ定義なしにはデータを格納できないが、XML-DBでは製品によって必ずしも定義しなくても良い場合もある。RDBに慣れたエンジニアが最初に驚くのが、スキーマを定義しなくても良いという点だ。
XMLはスキーマを設定することによって、XMLデータの持つ項目や意味をコンピュータに伝え高度な自動処理を可能にする。しかし、スキーマを必ず持つようにすると、XMLの持つ自由度が失われてしまう。そのため、あえてスキーマを定義しないケースもあるわけだ。このスキーマを持たないXMLのことを「well-formed XML」と言う。
XML-DBには、スキーマを定義してそれに適合するXMLのみを格納できるタイプと、スキーマを定義せず任意の構造を持つwell-formed XMLを格納できるタイプの2つがある。また、well-formed XML対応のデータベースでもXMLのスキーマ定義を設定することにより、登録されるXMLデータの妥当性検証ができる製品もある。DB2 9は、well-formed XML対応だが妥当性検証も可能なタイプの製品だ。しかし、DB2 9はハイブリッド型であるためRDBとしてのスキーマが必要になることには注意が必要だ。ここがネイティブ型との大きな違いになる。
DB2 9では、階層構造を持つXMLをXML型のデータとして扱う。つまり、リレーショナルデータ用のテーブルの中にXML型のカラムを作成し、その中でXMLデータを格納する形になる。そのため、XMLデータを格納するテーブルを定義する必要があるのだ。
画面2にXMLデータを扱うテーブルの作成例を示す。XMLデータ用のテーブル作成の手順は、RDBのテーブル作成と同様にテーブル名を指定してカラムを定義し、あとはXML型のカラムを定義するだけだ。
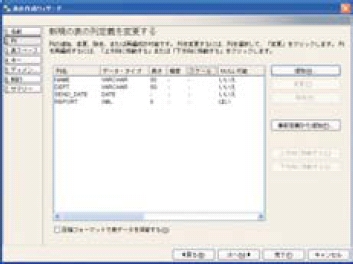
STEP3 XMLデータを登録する
ほとんどのXML-DBには、XMLデータを登録するためにそれぞれ製品固有のコマンドベースのツールやAPIが用意されている。多くの場合、コンソールからコマンドラインでXMLデータのファイルを指定してインポートできる。
画面3 は、DB2 9でXMLファイルを登録した画面である。画面上部の「IMPORTFROM C:weekly_reports.del...」となっているのがそれだ。どのXML-DB製品にもこのコマンドに相当するものが用意されており、通常は登録したいデータを持つXMLファイルを指定する。
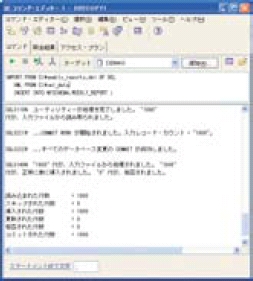
画面3:IMPORTユーティリティを使用したXMLデータの登録
インポートが成功すると、XMLデータが構造解析され、ツリー形式に変換して表示される。これによりデータベースに登録が完了したことを視覚的に確認できる。画面4にGUIツールから登録されたXMLデータの一部をツリー形式で表示した例を示す。
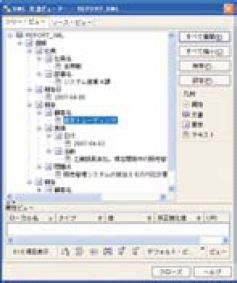
画面4:登録したXMLデータのツリービュー
ここで注意してほしいのは、DB2 9がハイブリッド型であるため、インポート手順がほかのXML-DBとは異なるという点だ。つまり、IMPORTコマンドが指定するファイルは、拡張子「.xml」のXMLファイルではなく、リレーショナルデータを登録するためのインポートファイルなのである。
インポートファイルの中身をLIST1に示す。CSVファイルのように区切られたデータファイルによって、画面2のテーブル定義と対応した値が記述されていることを確認してほしい。
LIST1:インポートファイルの内容
"吉原剛", "システム営業第4課", "2007-04-06", "<XDS FIL='週報_吉原.xml' />"
"小泉隆久", "システム営業第4課", "2007-04-06", "<XDS FIL='週報_小泉.xml' />"
"高田博史", "システム営業第5課", "2007-04-06", "<XDS FIL='週報_高田.xml' />"
...
"石田純", "流通システム開発第2課", "2007-04-06", "<XDS FIL='週報_石田.xml' />"
インポート先のテーブルにXML型カラムが存在する場合、XML型カラムに対応する値に
なお今回の例では、1000件のレコードがインポートされ、1レコードごとに1つのXMLファイルが登録されている。
STEP4 XMLデータを検索する
RDBに標準のクエリ言語SQLがあるのと同様に、XML-DBにも標準のクエリ言語XQueryがある。
XQueryが正式に標準になったのは最近であるが、ほとんどのXML-DB製品はXQueryのドラフト段階から準拠している。XQueryを使用することにより、階層構造を持つXMLデータから条件を指定してデータを取り出すことができる。RDBを扱うためにSQLが必須であるように、XML-DBを使う技術者にはXQueryの習得は必要不可欠だと言えよう。
XQueryの特徴は、XPathと呼ばれるXMLのノードを指定する表現式と、「FLWOR構文」と呼ばれる条件の表現式によってXMLデータを参照して結果を返す点にある。XPathは"/"を用いて階層中の要素の位置を指定するが、FLWOR構文は、"for"、"let"、"where"、"order by"、"return"を使って検索指示を行なう。
これらが実際にどのように使われるのかを以降で見てみよう。
条件を指定せずにXQueryを使う場合
LIST2は、STEP3で登録された1000件の週報データから「社員名」と「顧客名」をセットで取得するXQueryである。
LIST2:条件を指定しないXQuery
1:XQUERY
2:for $report in db2-fn:xmlcolumn("MYSCHEMA.WEEKLY_REPORT.REPORT")
3:return <社員別顧客名リスト>{$report/週報/社員/社員名,
$report/週報/報告//顧客名}</社員別顧客名リスト>;
1行目の「XQUERY」は、以降にXQueryが続くことを示すキーワードであり、DB2 9でXQueryを使用する場合に必須となるものである。XQueryを記述する際は、アルファベットの大文字/小文字が区別される点がSQLと異なるので注意しよう。
2行目にある「for」はFLWOR構文の一部で、検索対象とするXMLデータを指定する。XQueryでは頭文字「$」で変数を表わすことになっており、この例では、変数「$report」は「in」以下で指定される週報のXMLデータを参照している。変数が参照するXMLデータの指定方法は、製品によって異なる。DB2 9では、独自の組み込み関数「db2-fn:xmlcolumn」を使用し、表スキーマ名/テーブル名/カラム名を指定することで参照するXMLデータを特定している。
3行目の「return」もFLWOR構文の一部で、処理の結果となるXMLを返却することを示すものだ。「return」に続いて現われる「社員別顧客名リスト」タグは元のXMLデータにはないものだが、このタグは処理結果の前後に付加される。こうすることで、XQueryでは結果セットのXMLデータを自由に加工できる。
続いて"{ }"で囲まれた中に「$report」から始まるXPath表現が2つ並んでいる。最初の「$report/週報/社員/社員名」は、「/週報/社員/社員名」の要素を指定している。XPathでは"//"で示されるワイルドカードが使用でき、2 つ目のように「$report/週報/報告//顧客名」と指定すれば、「/週報/報告」要素以下にあるすべての「顧客名」要素を指定できる。
この検索を実行した結果がLIST3だ。
LIST3:条件を指定しないXQueryの結果
<社員別顧客名リスト>
<社員名>吉原剛</社員名>
<顧客名>西本トレーディング</顧客名>
<顧客名>大澤工業</顧客名>
</社員別顧客名リスト>
<社員別顧客名リスト>
<社員名>石田純</社員名>
<顧客名>西本トレーディング</顧客名>
</社員別顧客名リスト>
<社員別顧客名リスト>
...
LIST2の「for」で指定された変数による参照は、指定されたXMLデータ全件に対して繰り返し行なわれる。この検索式を実行すると、
- 「$report」が1000件の週報を繰り返し参照する
- それぞれの週報に対して「/週報/社員/社員名」の要素と「/週報/報告」要素以下にある「顧客名」要素を取得する
その結果、LIST3にある「社員別顧客名リスト」で囲まれた結果が得られるのである。
図1-Aには「/週報/報告/顧客名」、図1-Bには「/週報/報告/プロジェクト/顧客名」とあり、異なる位置に「顧客名」がある。LIST2のようにXPathのワイルドカードを利用してデータを指定することにより、この両方のデータを取り出していることに注意していただきたい。このようにXQueryを使えば、構造の違いを容易に吸収できるのである。
条件を指定してXQueryを使用する場合
続いて、検索の際に条件を指定する方法を見ていこう。LIST4は、STEP3で登録したデータから、「西本トレーディング」という名の顧客についての報告を抜き出し、「社員名」と「問題点」を取得するXQueryである。
LIST4:条件を指定するXQuery
1:XQUERY
2:for $report in db2-fn:xmlcolumn("MYSCHEMA.WEEKLY_REPORT.REPORT")/週報/報告
3:let $dept := $report/../社員/部署名
4:let $name := $report/../社員/社員名
5:where $report//顧客名='西本トレーディング'
6:return <顧客別問題点>{$dept, $name, $report//問題点}</顧客別問題点> ;
1行目はLIST1と同様である。2行目もLIST1と同様に検索対象を指定しているが、ここではXPath「/週報/報告」で要素を指定しており、「$report」を使用することにより直接「報告」要素にアクセスしている。
3行目と4行目にある「let」はFLWOR構文の1 つで、変数にXMLデータへの参照を設定する。XPathの「..」は親要素を表わすが、「$report/..」は「報告」の親要素、「週報」を指す。この2行で「$dept」が「/週報/社員/部署名」を、「$name」が「/週報/社員/社員名」を参照している。
5行目の「where」はFLWOR構文のうち条件指定を行なうものである。「$report」が参照するXMLデータから、「顧客名」が「西本トレーディング」であるデータのみを結果セットに含めるよう絞り込んでいる。既述したように図1-Aと図1-Bでは「顧客名」の位置が異なっているが、XPathのワイルドカードを使用することで、構造の違いを吸収して検索条件を指定できるのである。
この検索を実行した結果をLIST5に示す。LIST4の6行目「return」以下の構文により条件指定で絞り込まれた結果セットから変数を使用して「部署名」「社員名」を取得し、XPathのワイルドカードを使用することにより「問題点」のデータを取得している。
LIST5:条件を指定するXQueryの結果
<顧客別問題点>
<部署名>システム営業4課</部署名>
<社員名>吉原剛</社員名>
<問題点>販売管理システムの担当SEの対応が悪いとのクレーム有り。</問題点>
</顧客別問題点>
<顧客別問題点>
<部署名>流通システム開発2課</部署名>
<社員名>石田純</社員名>
<問題点>
2週間遅れで結合テストに入った。
遅れを取り戻すには要員追加が必要な状況。
</問題点>
<問題点>
販売部員から画面仕様が違っているとの指摘を受けた。
仕様書通りである旨説明したが、納得していない模様
</問題点>
</顧客別問題点>
なお、LIST4では使っていないが、"order by"を使用してソートキーとなる要素を指定することで、検索結果を並べ替えることもできる。
STEP5 インデックスを作成する(オプション)
RDBと同様に、XML-DBでも検索を高速化するためにインデックスを利用するが、このステップはオプションである。
その理由は、インデックスを自動で作成する「フルオートインデックス」という機能を持つ製品があるためだ。インデックスは、多く設定すればその分検索は速くなるが、データ更新に負担がかかる。これはXMLDBもRDBと同じである。インデックスを適切に設定できれば、検索と更新の性能を両立できるが、そのためには使用するXML-DB製品について詳しい知識が必要になる。手軽に高速な検索を実現したいのならばフルオートインデックス機能を持った製品を選択し、更新を重視するならば手動で設定する製品を選ぶと良い。
なお、DB2 9は手動でインデックスを設定するタイプの製品だ。GUIの管理ツール上から容易にインデックスを作成できる。インデックスはXPathを指定して作成するが、ワイルドカードを指定することもできる。
画面5では、STEP4で条件指定に使用された「/週報/報告//顧客名」を指定してインデックスを作成している。
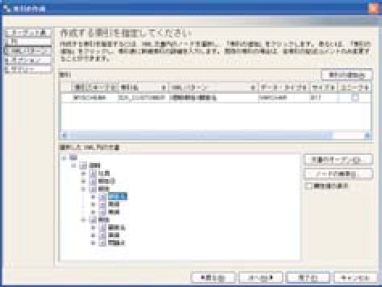
画面5:インデックスの作成
STEP6 XMLデータを更新する
データベース内のデータ更新において重要になるのは、更新の手段と範囲、そして更新時のトランザクションである。
XML-DBの更新手段としては、XQueryの拡張仕様「XQuery Update Facility」が標準言語として現在策定中であるが、各社の製品がこの仕様に準拠しているわけではない。そのため、各製品の更新機能の実装は異なっており、その方法は独自関数、ストアドプロシージャなど千差万別だ。また更新の単位も、個々のノード単位、登録したXMLデータ単位というように異なる。これらは製品の方式によってさまざまだ。さらに更新時にロックされる範囲についてもノード単位とXMLデータ単位があるが、現状ではXMLデータ単位でロックされる製品が多いようだ。
DB2 9では、XMLデータの更新をSQLの"UPDATE"文で実現している。ただし、XML型のカラムに格納されたXMLデータを丸ごと上書きする仕様となっている。格納されているXMLデータ内にある特定の要素の値のみを更新/削除したり、格納されたXMLデータへタグを挿入したりする機能はストアドプロシージャによって提供されている。
STEP7 プログラムから使う
RDBと同様、XML-DBを単体で使うことはほとんどない。通常は、XML-DBサーバーが提供するJavaやC#などのAPIを介してアプリケーションブログラムからアクセスする。
図2にJavaベースのWebアプリケーションを構築するときの基本的な構成例を示す。Webブラウザへの表示はHTMLによって行なわれ、Webブラウザからの操作はWebアプリケーションサーバー上のサーブレットプログラムからJava APIを呼び出して行なわれる。
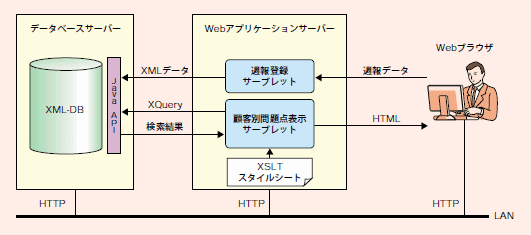
図2:システム構成例
システム構成全体ではRDBとXML-DBには大きな違いはない。違いがあるとすればAPIを介してデータベースとやり取りされるデータが、リレーショナルデータかXMLデータかという点と、問い合わせに用いるのがSQLかXQueryかという点に過ぎない。
XQueryを利用した場合、これにより得られたXMLデータの処理はDOM(注2)やSAX(注3)のライブラリを使って行なわれる。そして処理されたXMLデータは、XSLTを使用してHTMLに変換することによりWebブラウザで表示可能になる。
また、Java言語からアクセスするためのAPIとして、「XQJ」と呼ばれるXQuery言語をサポートするために考案された標準APIが現在策定中であるが、RDBでのJDBCほど一般的ではなく、製品独自のAPIが使われているのが現状だ。DB2 9などのハイブリッド型の製品であれば、RDBがベースになっているためJDBCドライバが使用可能である。さらに、SQLを使用してRDBにアクセスする場合とまったく同じ方法でXQueryを扱うこともできる。
LIST6にJavaのプログラムからXQueryでXML-DBにアクセスする例を示す。
LIST6:XQueryを発行するJavaプログラム
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
public class db2sample{
public static void main( String[] args ){
String xQuery =
"XQUERY "
+ "for $report in db2-fn:xmlcolumn(
'MYSCHEMA.WEEKLY_REPORT.REPORT')/週報/報告"
+ "let $name := $report/../社員/社員名"
+ "where $report/../社員/部署名='システム営業4課' "
+ "return "
+ "<顧客別問題点一覧>{ $report/顧客名,
$report//問題点, $name }</顧客別問題点一覧> ";
try{
Class.forName("com.ibm.db2.jcc.DB2Driver");
Connection conn =
DriverManager.getConnection(
"jdbc:db2://localhost:50000/DBMAG", "db2admin", "db2admin");
ResultSet rs= conn.createStatement().executeQuery(xQuery);
while (rs.next()){
System.out.println(rs.getString(1));
}
conn.close();
}catch(Exception ex){
ex.printStackTrace();
}
}
}
おわりに
本稿では、7つのステップ操作に沿って、DB2 9 Expressを例にXML-DBの基本機能と、その操作方法を紹介してきた。XML-DBは、いままでRDBができなかったことを可能にする新しいデータベースであるが、RDBについてよく知っている読者の皆さんなら、それほど戸惑うことはなかっただろう。
本稿をきっかけに、ぜひXML-DBに触れてみてほしい。
- 注1:各操作はWindows XP上で実行している。
- 注2:DOM(Document Object Model)は、アプリケーションがXMLを解析/操作するために使用する標準APIの1つ。XMLをツリー構造として扱い、XML全体を解析してメモリ上に保存する。そのため多くのメモリを消費するが、XMLの構造を自由にたどることができる。また要素を追加/削除できるため、XMLデータの構造を大きく変更したい場合に向いている。
- 注3:SAX(Simlile API for XML)はDOMと並ぶXMLを解析/操作するために使用する標準API。SAXはXML文書を先頭から読み、XML構造を認識するとそのたびにアプリケーションに伝達する。DOMに比べてメモリ消費量が少なく解析速度が速いという特徴があるが、XMLの構造を自由にたどれず、要素の変更ができないため、複雑な処理は難しい。