一口にXML-DBと言っても、さまざまな製品が開発/販売されている。そこで、TX1 V2の適用シーンを説明する前に、その機能的な特長を整理しておくことにしよう。はじめに、TX1がXML-DBとして備えている基本的な機能を紹介する。その次に、強力な業務ソリューションの実現を支援するTX1独自の機能を説明したい。
XML-DBとしての基本機能
階層構造を持つデータに強い
業務システムなどでは、DBとしてリレーショナルデータベース(以下、RDB)が広く使用されている。ただし、表形式でデータを管理するRDBでは、階層構造を持つデータ(人事情報や部品表など)を効率良く扱うことが難しいという問題がある。不可能ではないが、そのデータベース設計やデータ操作には、非常に高度なスキルが要求されてしまう。
このRDBが苦手な階層構造の表現をデータ構造の基本とするのが、XMLである。TX1は、XMLデータの管理に特化したXML-DB製品として、XMLデータの扱いに適した機構を備えている。そのため、TX1では階層構造を持つデータを扱うことが容易だ。
ウェルフォームドXMLに対応
また、TX1では格納するXMLデータの構造を必ずしも定義しておかなくても良い。XMLデータの構造はスキーマ(注1)によって規定できるが、XMLデータにはスキーマが必須というわけではない。RDBで扱う表形式のデータはスキーマ定義がないと、構造がないデータとなり意味をなさなくなってしまうが、XMLデータではそれ自体に構造とデータが記述されているため、タグ付けの規則に則っていれば(つまりウェルフォームドであれば)、スキーマを定義しなくても意味のあるデータとして扱えるからだ。
このようなスキーマを定義しないXMLデータは「ウェルフォームドXML」と呼ばれる。ウェルフォームドXML対応のXML-DBはスキーマの制約を受けないので扱いやすい、というメリットがある。
標準問い合わせ言語XQueryに対応
TX1は、XML-DBのための標準問い合わせ言語であるXQueryに対応している。XML-DBがXQueryに対応していれば、エンジニアは検索言語としてXQueryを覚えていれば良く、各製品に固有の問い合わせ方法を学ぶ必要がない。RDBにとってのSQLと同様、XML-DBには必須の機能であると言えよう。
オートインデックスで性能を確保
一般にXML-DBでも、RDBと同じように処理を高速化するためにインデックス(索引)が使用される。インデックスの設定を手動で行なう場合には、データベース製品についての詳しい知識を持った上で、検索性能と更新性能の両方のバランスを考慮しなければならないので、使いこなすには相応のスキルが必要になってしまう。
TX1はオートインデックス(自動インデックス作成)機能を備えており、TX1の扱いに習熟していなくても、高い性能を引き出すことができる。
TX1 V2特有の強力な機能
高速検索を実現する2つの機構
TX1には、データ検索の高速化を実現する独自技術として、データ構造を自動抽出する「スキーマアナライザ」と、問い合わせを最適化する「クエリオプティマイザ」が実装されている(図1)。
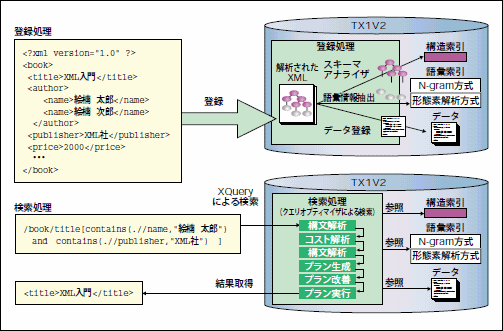
図1:登録処理/検索処理に見るTX1 V2のアーキテクチャ概要
スキーマアナライザは、高性能のオートインデックス技術で、登録されたXMLデータから構造情報を自動的に抽出し、それをもとに「構造索引」と呼ばれるインデックスを作成する。この技術により、スキーマの制約を受けないウェルフォームドXMLを自由に登録できるという高い柔軟性はそのままに、高速な検索性能を実現する。
クエリオプティマイザは、複雑なXQueryによる検索を高速化するための技術で、与えられた検索条件からTX1内部で最適な検索プランを生成し、検索を実行する。複雑なXQueryはXML-DB内部の検索機構を意識して書かないと性能が出なくなってしまうことが多いが、この技術により、エンジニアにTX1内部の検索機構を意識させることなく検索を高速化する。
図2は、複雑な階層構造を持つ特許公報8年分300万件をXMLデータとしてTX1に登録し、検索した例である。このデータの容量は100GBにも及ぶが、図2からは複雑な検索条件で問い合わせを行なってもTX1が十分な性能を出しているのが分かるだろう。
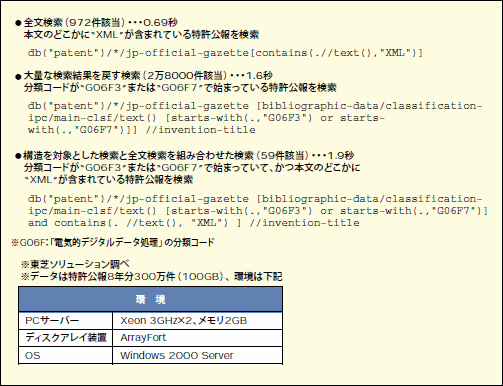
図2: XMLデータ化された特許文献への問い合わせに見るTX1の検索性能
用途別に全文検索方式を使い分け
TX1には、強力な全文検索機能も備わっている。全文検索機能とは、全文書から指定された単語を含む文を取り出すもので、そのアルゴリズムとして「N-gram方式」と「形態素解析方式」が知られている。TX1は最初のバージョン(V1)からN-gram方式を採用しているが、V2ではさらに形態素解析方式による検索も可能になった(図1)。
N-gram方式は、単語の意味とは無関係に文のつながりをN文字ずつ区切った文字列を索引として利用する方式である。一方、形態素解析方式は解析用の辞書を用いて、文を"意味を持つ最小単位の言葉(形態素)"に分解し、それらの文字列を索引として利用する方式だ。
両者の違いを、単純化した例を使って説明しよう。2文字ずつ区切るN-gram方式では、「東京都の駅」を「東京」「京都」「都の」「の駅」に分解して索引を作る。それに対し、形態素解析方式では辞書を用いて「東京」「都」「の」「駅」と分解して索引を作る。この場合、「京都」で検索したときに、N-gram方式では「東京都の駅」が検索にかかるが、形態素解析方式では検索にかからないことになる。
京都を条件にして検索したときに「東京都の駅」が該当する例は意味を考えるとおかしいように思えるが、必ずしも単語として意味を持つ文字列だけで検索するとは限らない。例えば、製品の型番などを部分一致で検索したい場合などがある。検索の重要な要件である「検索漏れをなくしたい」という要求には、N-gram方式が適している。一方の形態素解析方式は、索引が形態素で構成されているため、検索者の意図に近い文章を探す場合などに適している。
このように、2つの方式の違いを理解した上で全文検索機能を適所に用いれば、検索の精度を高くすることが可能だ。TX1V2では、どちらの方式でも内部的に「語彙索引」と呼ばれるインデックスを作ることで高速な検索性能を実現している。索引方式を設定しておけば、N-gram方式にはN-gram方式用の、形態素解析方式には形態素解析方式用の語彙索引が、XMLデータ登録時に自動で作成される。
他DBやNotesとのデータ連携も可能に
TX1は、XML-DBを使用するWebアプリケーションの開発を支援する機能として、「XWeb」というフレームワークを標準で提供している。XWebを用いれば、HTMLページやスタイルシートの作成と簡単な設定だけで、TX1に格納されたデータを利用するJava EEベースのWebアプリケーションを短期間で開発できる。
さらに、V2では多様なデータソースとの連携機能が追加されている。このデータ連携機能は、企業内にあるRDB、LotusNotesといったさまざまなデータソースからデータを収集し、XML形式に変換してTX1に格納する。この機能を用いれば、企業内に散在するデータを活用するシステムを容易に構築することが可能だ。
活用パターンに見るTX1 V2の適用
TX1 V2の機能的特長を確認したところで、次にこれを企業システムに効果的に活用するパターンとして、以下の例を紹介しよう。
- 活用パターン①:半定型文書の閲覧と活用
- 活用パターン②:Webアプリケーション開発の効率化
- 活用パターン③:企業内データの統合
いずれもRDBでは実現が難しく、XML-DBであるTX1 V2が力を発揮する分野だ。ここでは各パターンについて、具体的な例を挙げながら説明していく。
活用パターン①:半定型文書の閲覧と活用
XML-DBの活用が最も期待される領域の1つがオフィスでの半定型文書の処理である。半定型の文書とは、RDBで管理されるテーブルほど定型的(データ項目が固定)ではないが、何らかのデータ構造に従って処理を行なえる程度には規定されている文書のことである。最初に紹介するTX1の活用パターンは、この半定型文書の一元管理を目指すシステムである。
図3は、金融商品を扱う会社で使用されることを想定した業務マニュアル閲覧システムのイメージである。このシステムでは、金融商品の商品情報データを元に作成した商品説明マニュアルなどの業務マニュアルをXMLデータ化し、TX1のデータベースに格納。本社の各業務部門によって登録された各種商品情報データに販売時の注意事項や販売手順を付けることで作成される商品説明マニュアルなどは、全国の支社や代理店からWebブラウザを使って参照可能にする。また、顧客企業に合わせて商品情報データから作成する商品説明書を、自動組版システムを使って印刷する機能も加えた。
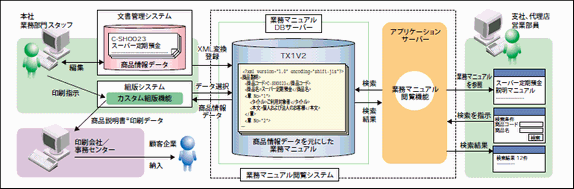
図3:業務マニュアル閲覧システム
(※法人向け金融商品説明書など、特定用途のためにカスタマイズされている)
この業務マニュアル閲覧システムは、次のような特徴を持つことになる。
半定型文書の処理
業務マニュアルを管理する際に問題となるのが保守作業だ。例えば商品説明マニュアルの場合、新商品の開発や商品内容の改訂に伴って商品情報データの新規作成/更新や販売手順などに変更があるたび、それらを反映させなければならない。
こうしたマニュアル類はWord文書として作成されているケースもある。しかし、すべての商品説明と販売手順を記載した新しいWord文書をただ単に配布したのでは、変更された商品内容や販売時の注意点、販売手順の確認に手間がかかり、営業担当者らに大きな負担をかけてしまう。必然的に、現場からは「変更された箇所だけをまとめて見たい」という要求が挙がるだろう。
図3の業務マニュアル閲覧システムは、マニュアルをXML化することで、これらの問題を解決することを意図している。
商品説明マニュアルは図4のように、階層構造として表現できる。その中では見出しや項目などが繰り返し現われるのだが、それぞれの階層の深さは異なる上、任意の階層に販売時の注意点を記述する必要があり、さらに場合に応じて表や図も含まれる。このように一定しない項目や階層構造を持つ半定型文書をRDBで扱うのは難しい。このシステムでは、ウェルフォームドXMLに対応したTX1を採用することで項目の追加/変更といった編集の自由度を高くしながら、「変更された注意点」などの条件に該当する項目だけの参照も実現する。
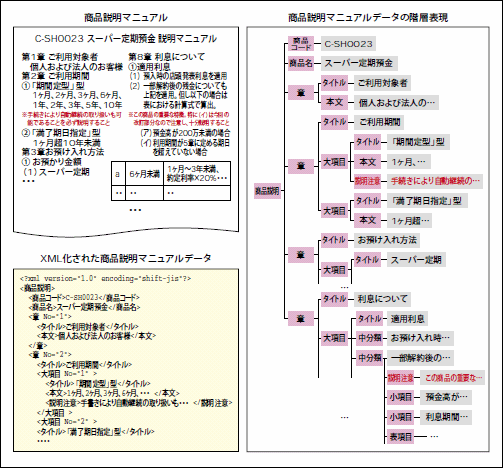
図4:XML化した商品説明マニュアルの階層構造
1つのXMLデータをさまざまな用途で利用
また、このシステムの要件には、商品内容の変更が発生するたび、顧客企業に改訂内容を印刷物で伝えることも含めている。そのため、商品情報データを改訂した場合には、修正した商品説明書を印刷して顧客企業に郵送する必要がある。しかし、印刷業者とのやり取りや文書校正にも多くの時間と労力を費やさねばならず、商品説明書の改訂作業が商品情報データの改訂頻度に追いつかないことも予想される。
そこで業務マニュアル閲覧システムでは、TX1にXMLデータとして格納されている商品情報データを元にしたデータの印刷に、XMLデータに対応した組版システムを利用。これにより、手間やコストを削減し、顧客企業に合わせた商品説明書の作成/印刷も可能にする。全国の支社や代理店には、XSLT(注2)の構造変換を使ってXMLデータをHTMLに変換し、Webページで商品説明マニュアルを公開できる。
高度な日本語全文検索
業務マニュアルはサイズが大きく複雑な文書である上、数多くの金融商品ごとに用意され、それぞれに関連するマニュアルがあるため、管理する文書はかなりの数になる。実際の業務では、その中から特定の単語や文を含む項目やマニュアルを探し出す機能が必要になる。さらに、該当する文書全体ではなく、見たい項目だけを取り出せることが重要である。
このシステムでは、そのためにTX1の全文検索機能を使用し、複雑な構造を持つ大量のマニュアルデータ検索を高速化している。また、検索漏れをなくしたい場合にはN-gram方式を、文の単位で探したい場合には形態素解析方式を使うことで、取り出したい文書/項目の特性に合わせた効率的な検索も実現できる。
活用パターン②:Webアプリケーション開発の効率化
Webアプリケーション開発の生産性を高めることも、XML-DBに期待されている効果の1つである。XMLを扱う標準技術には、XMLデータを変換してHTMLを生成するXSLTや、XMLデータに最適な問い合わせ言語XQueryなどがあるが、これらを使うことでXML-DBを用いたWebアプリケーションを簡単に構築することができる。先に紹介したTX1のXWebフレームワークは、これらの技術とJava Servletを組み合わせて、TX1を使用したWebアプリケーションの開発を効率化してくれる。ここでは、2つ目のTX1活用パターンとして、XWebを使用したJava EEベースのシステムを見てみよう。
図5は、「あるメーカーが製品の品質管理のために開発する」ことを想定したシステムのイメージである。このシステムには、製品に対して日々寄せられるさまざまな問い合わせや要望、クレームといった情報が集約され、ユーザーはWebブラウザで品質に関わるこれらの情報を管理/共有できることを目指している。
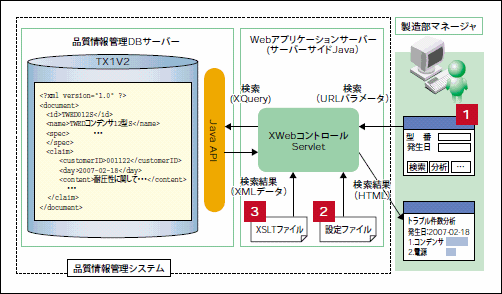
図5:XWebを利用して開発した品質情報管理システム
XWebでコーディングレスに開発
このシステムは、XWebを利用して構築されたものと想定している。XWebでは、アプリケーション画面に当たるHTMLページと、TX1から取り出したXMLデータをHTMLに変換するルールを定義したXSLTファイル、それらを結び付ける設定ファイルを用意するだけで、Webアプリケーションを構築できる。その手順は以下のとおりだ。
- 検索画面の作成
XWebが提供しているServletにURLパラメータを使用した検索リクエストを発行できるアプリケーション画面をHTMLで作成。 - XWeb用設定ファイルの記述
TX1への接続情報や、Servletが発行するXQueryの生成の設定、URLパラメータとXQueryの紐付け、検索結果をHTMLに変換するXSLTファイルなどをXWeb用設定ファイルに記述。 - HTML変換用XSLTファイル作成
検索結果としてTX1から取得したXMLデータを、Webブラウザで表示できるHTMLに変換するためのXSLTファイルを作成。
データ検索では、TX1の高度な全文検索機能や高速な検索性能を利用できる。このようにXWebを用いると、TX1を活かしたWebアプリケーションを比較的小さな手間と時間で開発できるのである。
活用パターン③:企業内データの統合
XMLは半定型の文書はもちろんのこと、定型/非定型データまで表現できる記述力を持っている。この性質を活かせば、企業内に散在しているさまざまなデータを1箇所に集めてXMLで表現し共有する、といったことも可能だ。ここで紹介する3つ目の活用パターンは、企業内に散在するさまざまなデータソースが持つ情報をTX1に集約し、統合的に扱うシステムである。
図6は、法人向けの事務機器販売会社において既存の販売管理システムとサポート情報を載せたグループウェアの情報を統合し、製品に関する情報を横断的に検索できることを目指したシステムをイメージしたものだ。事務機器の販売情報やサポートに関する情報を複数のシステムから集めてXMLデータに変換してTX1に格納し、顧客に関する情報を統一的に参照可能にしている。営業部門などはこのシステムを用いて、担当の顧客についてのさまざまな情報を一覧することができる。
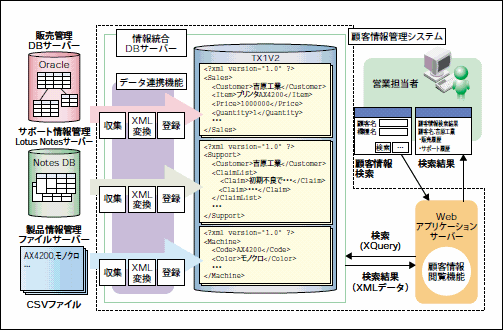
図6:データ連携機能を利用した顧客情報管理システム
データ連携機能による情報の集約
この会社では、顧客に対する事務機器の販売情報を、Oracleを使用した販売管理システムで管理している。また、販売後の問い合わせ対応や障害対応などのサポートに関する情報はLotus Notesで管理している。製品に関するデータは、ファイルサーバーで管理されている。これらの情報をXML化してTX1に集約すれば、「顧客の声を販売時の提案に活かす」といったことも可能になるだろう。
図6のシステムでは、これをTX1 V2で追加されたデータ連携機能で実現している。この機能を使えば、①データソースからのデータ収集、②収集したデータのXML形式への変換、③TX1 V2へのデータ登録、というETL(注3)処理も容易だ。データソースとデータ変換の方法はGUIツールで設定でき、データ収集のタイミングを指定すれば、これらの一連の処理を自動で行なってくれる。
データ集約のためのデータベースは、さまざまなXMLデータが混在する大規模なものになるが、TX1では異なる構造を持つXMLデータを大量に格納し、XQueryを用いて高速に検索することが可能である。V2から追加されたデータ連携機能により、TX1が情報統合用のデータベースとして利用されるケースも今後増えるだろう。
おわりに
本稿では、TX1 V2の機能的な特長とその活用方法を見てきた。V1から備えていたXML-DBとしての基本機能/性能はそのままに、V2では形態素解析による高精度な全文検索とさまざまなデータソースとのデータ連携機能を追加し、最近企業システムで特に注目されるソリューションの実現に、TX1は大きく貢献してくれる製品だというのが、筆者の感想である。
本稿が、自社あるいは顧客企業にある膨大な情報データを有効に活用するシステムを企画する際の参考になれば幸いである。
- 稼動環境
- Windows 2000 Server(SP4)、Windows Server 2003 (SP1、R2、x64 Edition、同R2)、Solaris 9 12/02以降(64ビット)、Solaris 10(64ビット)
- 開発環境
- Windows:Java(JDK/JRE 1.4.2、同5.0)、Visual C++ 6.0(SP6)/.NET2003/2005 x64、Visual Basic 6.0(SP6)/.NET 2003Solaris:Java(JDK/JRE 1.4.2、同5.0)
- 価格
- Windows版:1CPUライセンス450万円~ Solaris版:1CPUライセンス675万円~ (ともに税抜き)
- 問い合わせ先
- 東芝ソリューション株式会社