"教科書に載っていない"モデリング作法とは
これまでに筆者は、データモデリングに関する数多くの書籍や雑誌/Webの記事を読んできました。それらから得た知識は、確かに実践の中で活かされてきましたが、実際のプロジェクトでDB設計を担当するとなると「記事には載っていない何か」が現場では必要になったのです。世の中にある、多くのモデリングに関する書籍や記事には「モデリングそのもの」に関する情報は多く掲載されています。
それは例えば、正規化理論やモデリング手法といった"モデリング理論"的なものであったり、ある特定の業種でモデリングを行なう際に気を付けるべきポイントやコツ、いわば「特定業種のモデリングTIPS集」であったり、モデリングで頻繁に直面する問題に対する解法、すなわち「モデリングパターン集」のようなものでした。 そして、"記事に載っていない、現場で必要な知識"とは、実際の開発プロジェクトの全体工程の中で「DB設計がどのように絡んでくるのか?」「どの工程でどのようなことを実施するのか?」という点にあると感じました(図1)。
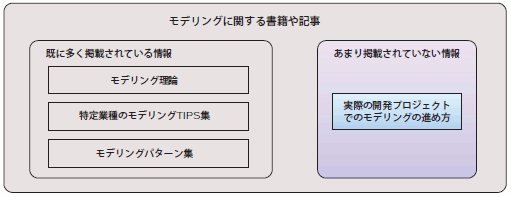
図1 モデリングに関する記事の種類と本稿の位置付け
そのため、本稿は「開発プロジェクトの工程全体の中におけるデータモデリング」に焦点を当てます。また、先の「モデリング理論」「特定業種のモデリングTIPS」「モデリングパターン集」の解説は最低限に留めます。とはいえ、モデリングを実践する際にはこれらの知識も必要になってきますので、まずはそうした知識を学ぶのに適した書籍を紹介します(カコミ記事参照)。本稿は、これらの書籍を「副読本」として活用しながら読み進めて行くとより効果的ですので、ぜひ目を通してみてください。
データモデリングの工程
それではまず、データモデリングがどのような工程を経て実施されていくか見てみましょう。データモデリングの工程をまとめた図3をベースに解説を進めていきます。各フェーズの詳細はこの後で1つずつ解説しますので、まずは全体の流れをザッと見ていきましょう。
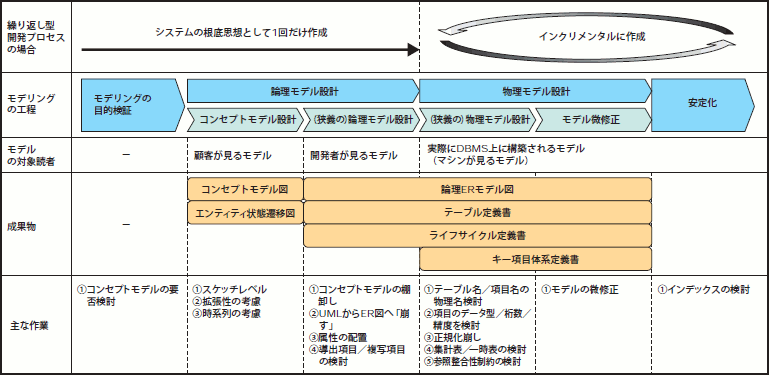
図3 データモデリングの工程[拡大]
まず、データモデリングを行なう前に、その開発プロジェクトで何のためにモデリングを行なうかを整理するために「モデリングの目的検証」を行ないます。その後、実際のモデリング工程に着手します。パート1でも軽く触れましたが、データモデルには人が読んで理解するための「論理モデル」と、実際にデータベースとして構築される「物理モデル」があり、それぞれの設計を「論理モデル設計」「物理モデル設計」と呼びます。
論理モデル設計をさらに細かくフェーズ分けすると、「コンセプトモデル(概念モデル)設計フェーズ」(図4)と「(狭義の)論理モデル設計フェーズ」(図5)に分かれ、物理モデルは「(狭義の)物理モデル設計フェーズ」(図6)と「モデル微修正フェーズ」に分けられます。
こうしてデータモデルは「安定化フェーズ」となり、最終的にアプリケーションの完成と共にリリースされるというわけです。なお、昨今はRUP(注2)や、XP(注3)に代表されるアジャイル系プロセスを採用し、インクリメンタルな開発スタイル(注4)をとる開発プロジェクトも増えてきましたので、繰り返し型のプロセスにおけるモデリングの工程についても解説しておきましょう。
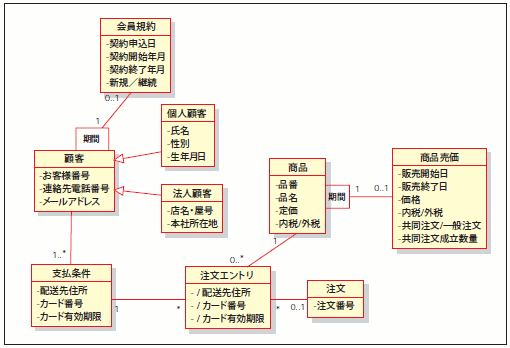
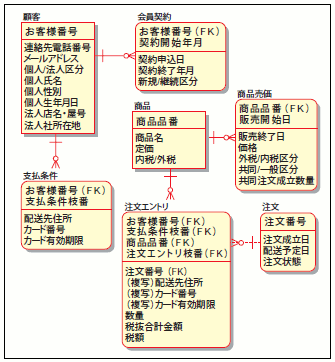
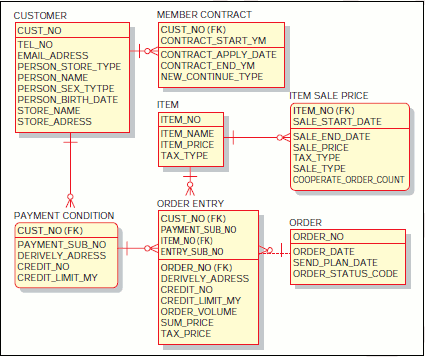
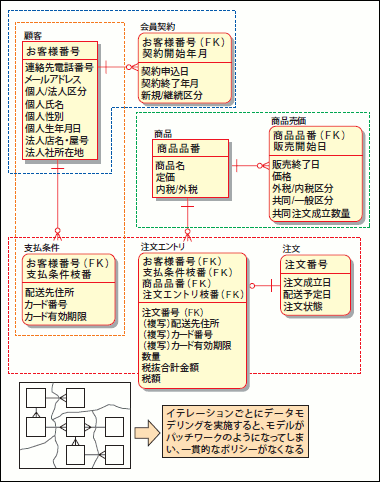
繰り返し型の開発プロセスとはいえ、イテレーションごとにデータモデルをイチから設計するわけではありません(注5)。「(狭義の)論理モデル設計」までは、システムの開発スコープ全体をカバーする「カタい」モデルまで 設計しておくのが、一般的と言えます。当然、これには理由があります。例えば、「商品メニュー」(図7)というエンティティを考えてみてください。これらのエンティティは新規に取り扱う商品を登録する「新規取扱商品登録」機能でも利用されますし、「注文」機能でも利用されます。また「セール情報設定」といった機能でも利用されるエンティティになります。
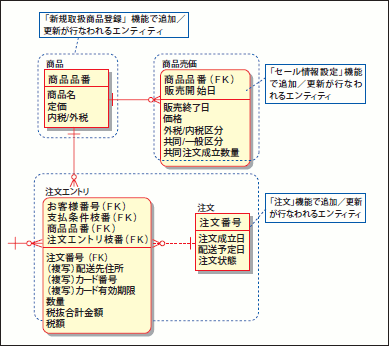
図7 商品メニューとその周辺のER図
このように、1つのエンティティは複数の機能から利用されるのが常です。このため、機能ごとにイテレーションを分けてリリースするとはいえ、そのたびに商品メニュー周辺のデータモデルを見直すわけにはいかないのです。もし、そうしてしまうと、ツギハギだらけでポリシーの欠如した、拡張性もへったくれもないデータモデルができてしまうでしょう(図8)。そのためデータモデルは、そのシステムの根底の思想を示す「堅固なもの」として設計される必要があると言えます。
DB設計の成果物
次に、データモデリングの各工程で作成される成果物とその位置付けを見ていきます。なお、これらの成果物定義は、あくまで筆者の推奨する成果物です。実際にはプロジェクトの特性に合わせて、これら以外に作成する成果物や、作成しない成果物もあるかもしれません。これらを「基準」としてアレンジすると良いでしょう。
コンセプトモデル図
UMLのクラス図で作成するコンセプトモデルを表現した成果物です。実際の開発プロジェクトでは、(狭義の)論理設計に工程が移っても、コンセプトが揺らぐ(=コンセプトモデルに変更が必要になる)局面が多々あります。そのため、開発プロジェクト終了後もコンセプトモデル図が必要となるかどうかを顧客と検討し、最終成果物とするかどうか、位置付けを定義する必要があります。
コンセプトモデルが、当該開発プロジェクトにおけるコンセプトを整理するためだけに作成されるのであれば、これを最終成果物とせずにメンテナンス対象としないほうが工数を抑えられるでしょう。ですがもし、当該開発プロジェクトが「第1次開発」的な位置付けであり、以降も第2次、第3次......とコンセプトを再整理しながら進めていく計画の場合や「企業レベルでデータモデルを整理する」ようなEA的な目的がある場合、コンセプトモデルをメンテナンス対象ドキュメントとして、最終成果物と位置付けるのが良いでしょう。いずれにせよ、メンテナンス対象とするからには工数を費やす必要があり、コストが発生することを顧客に理解してもらいながら、位置付けを整理する必要があります。
エンティティ状態遷移図
クラス図は静的な側面をとらえるための図なので、動的な側面は表現できません。そのため、注文や契約といった「状態」を有する「ライフサイクルが重要になってくるエンティティ」の位置付けを正しく整理するために、UMLのステートマシン図などを用いて動的側面を表現するドキュメントが必要となります(注6)(図9)。
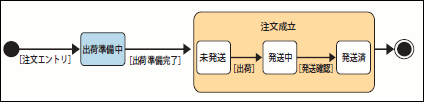
図9 ステートマシン図による動的側面の表現
論理ERモデル図
(狭義の)論理モデル設計で作成され、物理モデル設計での属性追加などに伴い、メンテナンスされる成果物です。エンティティ名や属性名などを日本語で記し、また「実際にDBMS上に参照整合性制約を定義するかどうか?」を考慮しない「論理的/意味的な関連」が記された"人が見るための"ER図です。論理ERモデル図は、アプリケーションの設計過程で"おそらく最もよく参照されるドキュメント"になりますので、読みやすさには十分気を配って作成したほうが良いでしょう。
テーブル定義書
(狭義の)論理モデル設計で作成され、物理モデル設計で「物理名」「データ型」「桁数」「精度」などの項目を記します。一般的には、図10のようなフォーマットで作成します。属性説明には、その属性の位置付けや「どのような値を格納するのか?」といった情報を記します。また、後に解説する「導出項目」や「複写項目」の場合、導出や複写のルールを記しておきましょう。
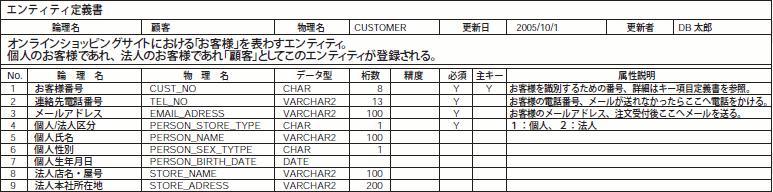
図10 エンティティ定義書の例[拡大]
ライフサイクル定義書
(狭義の)論理モデル設計~物理モデル設計の過程で徐々に精査する成果物です。このドキュメントでは、エンティティが発生してから破棄されるまでに、どのような編集が行なわれるかを記述します。具体的には、INSERT/UPDATE/DELETEの契機と、契機ごとの編集要領やルールをまとめます。すなわち、データベースの編集処理を、「機能」の軸ではなく、「エンティティ」を軸としてまとめたドキュメントになります(図11)。
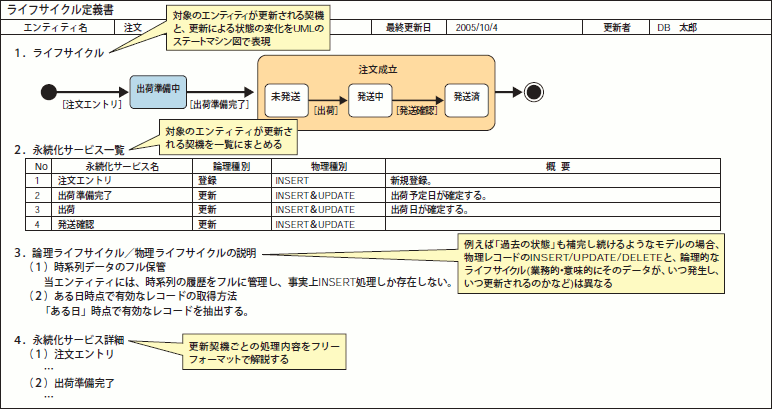
図11 ライフサイクル定義書の例
この成果物は、ソフトウェアアーキテクチャに多層アーキテクチャを採用し、レイヤ(層)ごとに設計/実装チームを編成する場合において特に有効に機能します(図12)。
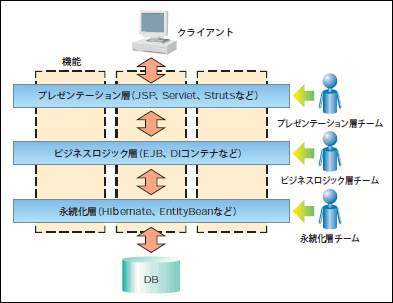
図12 多層アーキテクチャとレイヤ別チーム編成
ライフサイクル定義書がまとめてあると、ビジネスロジック層の開発者へ公開する「データベース永続化サービス」に、どのようなものがあるのかを示すことができます。また、永続化層の開発者はライフサイクル定義書を見ながら、アプリケーションの設計/実装を行なえると いうわけです。
キー項目体系定義書
物理モデル設計の成果物です。エンティティの主キー項目や、「XXコード」といった属性の採番体系を記したドキュメントで、図13のようなフォーマットで作成します。
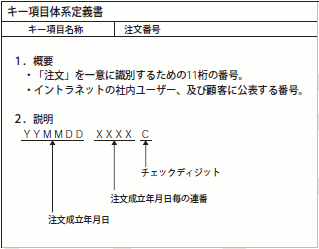
図13 キー項目体系定義書
モデリングの目的検証
それでは、開発プロジェクトで何のためにモデリングを行なうかを検討する「モデリングの目的検証」について見ていきましょう。「データモデリングの目的なんて、構築するシステムのデータベースを設計するために決まってるじゃないか」という声が聞こえてきそうです。確かにそれも目的の1つです。しかし、果たしてそれが目的のすべてでしょうか。筆者は、データモデリングにはもう1つ大きな目的があると思っています。
それは、「構築するシステムのDB設計」よりも広い視野に立ち「将来も見据えた最適なデータモデルを検討する」というものです。「構築するシステムのDB設計」という目的は、言ってしまえば「今見えているシステム要件に応えられるモデルを設計できさえすれば、目的を達成できている」ということになります。すなわち、ユーザーにとって興味があるのは、「要件を満たしたシステムを構築してくれること」であり、システムの内部にあるデータモデルがどのような形であろうと、それにはあまり興味がありません(図14)。
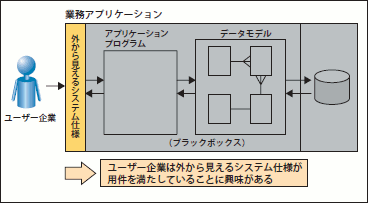
図14 ユーザー企業はシステムの中身に興味がない
一方、「将来も見据えた最適なデータモデルを検討する」という目的は、「データモデルを検討すること自体が目的」になります。すなわち、顧客自身が「ウチの会社にとって、商品とは何なのか? 契約とは何なのか?」といったことを検討し、納得のいくデータモデルを設計できることが目的なのです。言い換えると、「ユーザーがデータモデルそのものに興味がある」ということになります(図15)。
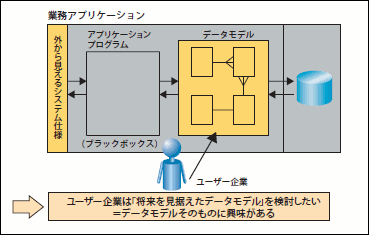
図15 ユーザー企業がデータモデルに興味がある
この「ユーザーにとって興味があるデータモデル」のことを「コンセプトモデル(概念モデル)」と呼びます。個々の開発プロジェクトでは、「このプロジェクトにおけるデータモデリングの目的は何なのか」(=コンセプトモデルが必要かどうか)を検討し、顧客と合意を得たうえで、モデリングに着手します。では次に、コンセプトモデルが必要となる開発プロジェクトとは、どのようなプロジェクトなのか見ていきましょう。
システムの新規構築や全面刷新
コンセプトモデルが必要となる開発プロジェクトとは、多くの場合、新規事業に伴う初期システム構築や、レガシーシステムの全面刷新といったケースになります(注7)。このような開発プロジェクトでは、現行システムのデータモデルや仕様にあまりとらわれずに、ゼロベースで設計を行なうといったイメージになります(新規事業の場合、「現行のシステム」は存在すらしないので当然ですね)。
顧客は、多くの場合「今のシステムの悪いところは是正したい」というボンヤリとした意思を持っていながらも、「具体的にどのようなシステムを構築すれば良いのか」という明確な意思を持っていません。あるいは、「現行モデルだと対応できず、考え方を変えなければいけない箇所」を具体的にイメージできていたとしても、「では、データモデルをどのようにすれば良いか」というレベルまでは詳細化できていません(図16)。
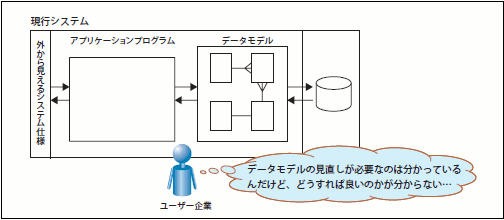
図16 システム刷新プロジェクトに対して顧客が抱いているイメージ
このような"ボンヤリとした要望"を具体的に落とし込んでいったり、「現行システムの考え方を改めなければいけない箇所」の新たな考え方を示したりするためにも、あまり現行の考え方にとらわれずに、顧客と合意しながらコンセプトモデルを検討する必要が出てきます。ところで、「現行の考え方にとらわれない」「ゼロベースからのあるべきモデル検討」とはいえ、移行要件は頭の片隅に考慮しておいたほうが良いでしょう。
具体的には、コンセプトモデルが現行システムと比べて、あまりにかけ離れたモデルになってしまった場合に、移行に関する方針を合意しておいたほうが良いということです。例えば、「一発の移行作業でデータ移行ができるかどうか?」や「移行後のデータメンテ期間中は、運用で回避することができるか?」といったレベルでの「方針」を定めておくといった具合です。
コンセプトモデルの要否判断は慎重に!
「システムの全面刷新」と「稼動中システムの改修」という2種類の開発プロジェクトからコンセプトモデルの検討要否を見てきましたが、実際のところ、これらに明確な「境界線」を見出すのはなかなか難しいことです。言い換えると、ある開発プロジェクトが「全面刷新」なのか「改修」なのかは、判断をつけにくいのです。
例えば、今まではコールセンターでの受注がメインだった企業が、Webによる販売を行なうようになった場合を考えてみましょう。コールセンターで顧客と直接受け答えしながら注文を受ける場合は、「注文」に必要な情報は電話口で聞き出せます。一方、Webサイトの場合、「注文」に関する情報は、注文者である顧客が「自分で入力した情報」に過ぎません。 このような場合に、「注文」という概念が今までの「コールセンターを前提とした定義」で上手くいくのか、あるいはWebの場合の「注文」とエンティティを分ける必要があるのか検討しなければなりません。
検討の結果によっては、「将来も見据えた最適なデータモデル」を顧客と共に検討する必要が出てくるかもしれません。ほかにも、注文された商品をコンビニでも受け渡しできるようになる場合はどうでしょうか。そうなると「注文の発送状態の管理」は従来と変わるかもしれません。あるいは、これによって「注文」という概念が既存の考え方では通用しなくなるかもしれません。さらには、法人からの受注に用いているEDIプロトコルを、新たなものに変更する場合などはいかがでしょうか。
もし、「注文」という概念が既存のEDIプロトコルを前提とした概念である場合、「1つの注文」という概念がこれまでと変わるかもしれません。このように、「注文」という概念がどのように変わるかという点は、個々の開発プロジェクトの現行システムの仕様やデータモデルの構造によります。我々開発者は、プロジェクトの予算や期間、データモデルの変更が周辺システムへ与える影響など、さまざまな要因を検討しながら、データモデリングをどこまで「あるべき姿」に立ち返って実施すべきかどうかを顧客と合意する必要があるのです。
コンセプトモデル設計フェーズ
それではいよいよ、モデリングそのものについての解説です。まずは、コンセプトモデル(概念モデル)設計について解説していきましょう。コンセプトモデルを作成するフェーズは、開発プロセス全体からすると、周辺システムとの役割分担や大まかなシステムアーキテクチャを検討していたり、新システム導入による業務フローの変更点を分析し、システム境界を明確化していたりする、いわば開発プロジェクトにおける最上流のフェーズと言えます。
コンセプトモデルとは、前述のように「顧客にとって興味のあるデータモデル」のことです。もう少し分かりやすく言うと、「ウチの会社にとって、商品とは何なのか? 契約とは何なのか?」といったことを明らかにし、これを顧客と合意するためのものが、コンセプトモデルになります。コンセプトモデル(概念モデル)の作成の仕方にはさまざまな流派がありますが、筆者は「エンティティの抽出を主な目的として、属性はあくまでエンティティの位置付けを分かりやすくするための補足情報に過ぎない」と考えるアプローチが気に入っています(注8)(図17)。
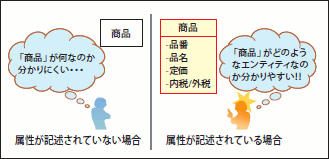
図17 属性はエンティティの位置付けをハッキリさせる
コンセプトモデルは「その場主義」で作成する
コンセプトモデルの設計は、顧客とのセッション形式でホワイトボードや付箋を使いながら、その場でモデリングするスタイルが良いでしょう。これを「その場主義」と呼びます(注9)。
その場主義と相反するやり方を「持ち帰り主義」と呼びます。持ち帰り主義では、顧客から受領したたくさんの資料とにらめっこをしたり、ヒアリングの議事メモをチェックしながら、開発者が"持ち帰って"モデルを作成します。そうして作成したモデルを改めて顧客に提示して、指摘してもらうようなやり方になります。ところが、顧客とのヒアリングで得られる情報は、往々にして「抜け漏れ」や「矛盾」が多く存在するものです。このため、持ち帰り主義では、持ち帰った情報に漏れがあったときに、それ以上モデルを書き進めることができません。また、矛盾に気づかず、モデルを誤った方向へ導いてしまったりします(図18)。
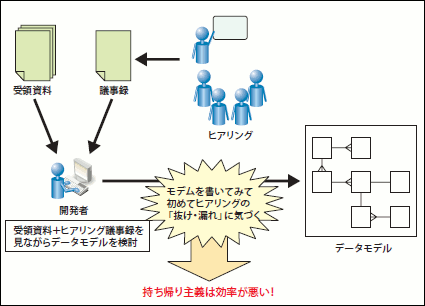
これが持ち帰り主義の欠点です。すなわち、モデリングの生産性や品質を保つことが難しいのです。また、顧客からしても"一緒にモデリングしている感"を得られず、どうしても受動的な態度になってしまいます。一方、その場主義は、ホワイトボードや付箋紙などを使って、ミーティングの"その場で"モデルを作成します。
モデルがその場で作られていくため、抜け漏れや矛盾はその場で発見でき、効率良くモデリングを進めていけますし、顧客も"一緒にモデリングしている感"が得られます。実際のモデリングの現場では、モデリングセッションの場で、その場主義によって作成したモデル(ホワイトボードや付箋紙に書かれたモデル)をモデリングツールなどで電子媒体へ清書し、次回のセッションでその清書を見せて確認するようなやり方が適しているでしょう(図19)。
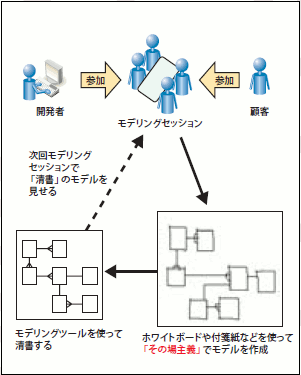
図19 その場主義のモデリングの進め方
コンセプトモデルはUMLで書く
コンセプトモデルの「表記法を何で書くか?」という点に関してもさまざまな流派がありますが、筆者はER図ではなくUMLのクラス図で描くほうが良いと考えています。コンセプトモデルは「その場主義」で顧客と共に作り上げていくものですから、顧客にとって理解しやすいモデルであることが何より大切です。このため、ER図よりもいろいろな表現が可能なUML(クラス図)を勧めるのです。 これは、決して「ER図の表現力が豊かではない」と言っているのではありません。一言で「ER図」と言っても、その表記法にはさまざまなものがあり、コンセプトモデルに適した書き方も確かに存在します。ところが、世に出ているERモデリングツールは、どちらかというと「実装寄り」のツールが多いのです(注10)。
具体的には、関連を書くために外部キーを設定する必要があったり、依存関連と非依存関連を区別して書かなければいけなかったりする点です。モデルをホワイトボードや付箋紙で書くだけで良いのであれば「コンセプトモデルに適したER図の表記法」を用いれば済みますが、いざ清書しようとしたときに実装寄りのツールしかないため、ホワイトボードの内容をそのまま書くのが困難になってしまうのです。
その点UML(クラス図)は、仕様やメタモデル(注11)の厳密さが比較的"ユルい"表記法であり、多くのUMLモデリングツールも柔軟な表現が可能です。このため、UMLの仕様の大枠さえ知っていれば、ホワイトボードの内容をそのまま清書するのも簡単なのです。また、UMLの「継承」や「関連クラス」(図20)といった概念も、コンセプトモデルの表現力を高めるために役立ちます。
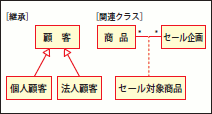
図20 継承/関連クラス
まずはスケッチレベルで
ここまで、コンセプトモデルの目的、「その場主義」で作成すること、UMLで書くことを解説してきました。では、どのような段階を経て、コンセプトモデルを精査していくのでしょうか?はじめに作成されるコンセプトモデルを、「スケッチレベル」と呼びます。スケッチレベルのコンセプトモデルとは、「その場主義」モデリングで、顧客に説明してもらったことを、そのまま正直に"スケッチ"し、開発者/顧客の相互理解を得るためのモデルです。スケッチレベルのモデリングでは「顧客の説明をそのまま正直に描く」という点がポイントです。言い換えると、モデリングの主導を握るのは顧客であり、開発者は"聞き"モードで"顧客の発言をモデル化"することになります。開発者は不明な点を質問したり、描いたモデルを説明したりはしますが、それ以上踏み込んでモデリングセッションの主導を握りません。こうして作られたモデルが「スケッチレベルのコンセプトモデル」であり、以降モデルを精査していくための土台となります。
拡張性を考慮したモデルへ
分析範囲をスケッチレベルでひととおりモデリングし終え、その内容を顧客と合意できたら、次にコンセプトモデルに対する「拡張性の考慮」を施します。拡張性の考慮とは、「将来発生しうる変化」を予測し、その変化が起こったときにもシステムの改修量を最低限に抑えられるようなモデルを検討することです。言い換えると、今の「スケッチレベルのモデル」において「現実に起こりうる業務上の変化」に耐えられないところを発見し、そのモデルを「変更に強いモデル」に精査していくのです(図21)。
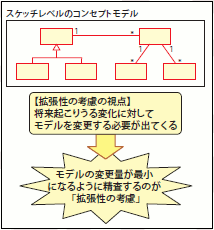
図21 拡張性の考慮とは
ここでまず念頭に置くべきなのは「データモデルを変更すると、相当のシステム改修が必要になる」ということです。すなわち、「将来発生しうる変更」に耐えられるようなモデルを検討することは、将来の拡張容易性に直結するのです。この「拡張性の考慮」で重要になるのが「抽象化」の考え方です。抽象化とは、スケッチレベルにある複数のエンティティに「共通性」を見出し、その共通部分を別の概念(エンティティ)として切り出すことを意味します。
この「抽象化」をモデルで表現するには、大きく分けて2パターンのアプローチが存在します。1つは継承の利用です。継承を利用した抽象化とは、切り出した共通部分を親クラスとして定義し、元々のエンティティのうち共通部分から溢れた概念をサブクラスにするアプローチです(図22)
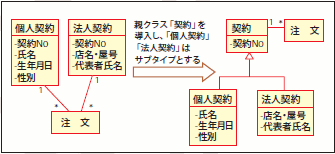
図22 継承を用いた抽象化
2つ目が、「分類エンティティ」を利用するアプローチです。継承アプローチが溢れた概念をサブタイプとするのに対し、「分類エンティティ」では、この「サブタイプごとの相違点」を「分類」として制約をメタ的に表現します。言葉で説明するのはなかなか難しいので、図23をご覧ください。
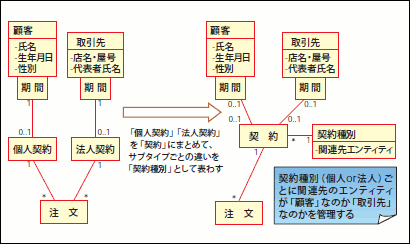
図23 分類エンティティを用いた抽象化
継承アプローチ(図22)では新たに「ファミリー契約」という概念ができたとき、「ファミリー契約」エンティティを追加する必要がありますが、分類エンティティアプローチでは、クラスの数は変化しません。このように、分類エンティティアプローチは、継承アプローチよりも汎用性/拡張性が高い抽象化であると言えます。ただし、分類エンティティアプローチは、「制約をモデルで表現している」に過ぎないので、この制約を実装したアプリケーションのロジックは複雑になりますし、何よりモデルとして、直感的に理解するのが難しくなります(注12)。
ここで何より重要なのが、抽象化はあくまで「顧客が望む拡張性に関する要件」が存在してこそ、行なう意味があるという点です。例えば、新たな「分類」が日常的に追加され、そのたびにシステムを改修するのは業務に支障があるような場合は、多少ロジックが複雑になろうとも、「分類エンティティ」アプローチを採用すべきでしょう。これが「日常的とまではいかないが、年間に数回程度」の頻度であれば、直感的に分かりやすくシンプルな「継承アプローチ」を採用すべきです。「拡張性の考慮」段階では、開発者と顧客の関係が「スケッチレベル」段階と逆転します。
つまり、主導を握るのが開発者にあり、顧客は「聞き」モードにまわるという構図になります。また、拡張性の考慮は、開発者にとっての腕の見せ所であり、最も"モデリング脳"をひねって考えるポイントになります。開発者はスケッチレベルのモデルを見ながら、顧客に「将来的にこのような変化が起こることを、予測する必要がありますか?」と問いかけながら抽象化を「提案」していき、「顧客が望む拡張性」をうまく引き出しながらモデルを精査していく必要があるのです。
時系列を考慮する
スケッチレベルのコンセプトモデルを精査するうえで、拡張性以外にも考慮すべきポイントがあります。それが「時系列の考慮」です。スケッチレベルのモデルは顧客の発言を素直にモデル化していますが、たいていの場合、現在(ある瞬間)のエンティティ間の多重度は明らかになっているものの、時系列の考慮という視点が抜けています。このため、スケッチレベルのモデルを顧客といったん合意できたら、改めて「時系列の考慮」という視点でモデルを評価し、精査する必要があるのです。
時系列の考慮とは、例えば「顧客」と「支払条件」(注13)の関連における「過去」の多重度を検討する際に必要となる視点です。ある顧客にとっての「現在の」支払い条件が1種類に限られたとしても、過去の取引におけるその当時の支払条件を参照する必要がある場合、「先月まで、支払い条件は銀行口座引き落としだった」という事実を保管しておく必要があります。また、来月から支払い条件をクレジットカード払いに変更する」といった「未来」の視点を管理する必要がある場合なども考慮する必要があるでしょう(図24)。

図24 ショッピングサイトのデータモデルにおける時系列の考慮
「時系列の考慮」の具体例をもう少し解説しましょう。例えば、人事データベースの場合、「過去にAさんが所属していた部署や、その当時の役職を管理する必要があるかどうか」といった点や、「次年度の3月に、Aさんの所属が変わることをあらかじめ登録しておきたいかどうか」といった点を検討する必要があります(図25)。
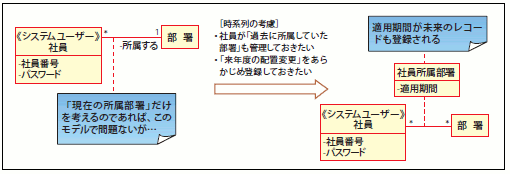
図25 人事のデータモデルにおける時系列の考慮
このように、「過去の履歴」や「未来の予定」といった情報を管理する必要があるのかどうかという点を適切にモデルで表現するのが「時系列の考慮」です。言い換えると、エンティティのライフサイクルを「精緻にモデリング」することが「時系列の考慮」なのです。時系列の考慮では、「限定子」という表記が役に立ちます。図26のように「XX(時系列的な要因)ごとに○○エンティティが1つに定まる」ようなケースには、積極的に限定子を用いると良いでしょう。コンセプトモデルの段階で、この「時系列の考慮」を行なっておくことで、後に解説する論理モデル設計における「主キー項目の検討」や「複写項目の検討」を行ないやすくなります。
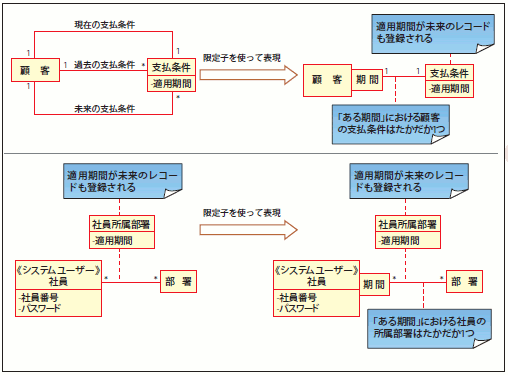
図26 限定子を用いて表現
「ブツ」と「種類」を区別する
コンセプトモデルを書き進めていくと、ある1つのエンティティが「種類」を表わしていたのか「ブツ」を表わしていたのか、ごっちゃになってしまうことがよくあるのです(図27)
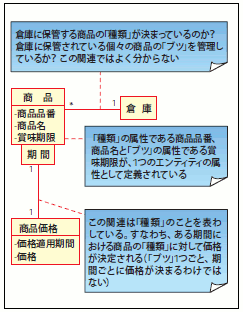
図27 ブツか種類かがごっちゃになっている例
例えば「商品」というエンティティがあるとき、その商品の「ブツ」とは、「1枚のCD」「1冊の本」や「1袋のスナック菓子」のような、具体的な1つのものになります。一方の「種類」は、「商品マスタ」と読んだほうが理解しやすいかもしれません。すなわち、「ISBN(注14)で識別される書籍の種類」や「JANコード(注15)で識別される商品の種類」といったものになります。この、「ブツ」と「種類」をはっきり区別しながらモデリングを進め、「ブツ」なのか「種類」なのかを、ステレオタイプ(注16)などの表記を用いて表現しておくと良いでしょう(図28)。
さらには、モデルの「読みやすさ」を高めるために、「ブツ」と「種類」以外にも、「役割」「トランザクション」などのステレオタイプを用いてエンティティを分類しておくことをお勧めします。
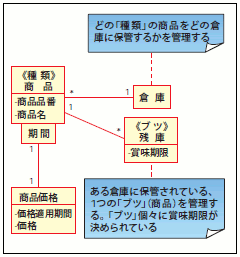
図28 ブツと種類を区別したモデル
論理モデル設計フェーズ
論理モデル設計を行なっているフェーズは、開発プロセス全体でいうと、システムアーキテクチャの検討や、システム境界が明らかになり開発スコープを明確にできた後、これからユースケースなどの手法を使ってシステム要件分析を行なおうとしているタイミングになります。コンセプトレベルのモデルは、顧客とデータモデルを合意するためのものでしたが、これ以降の論理モデルは、開発者が設計を行なうために「見る」ものになります。視点が「開発者向け」に移るため、表記法を見やすさ重視/表現力重視のUMLから、実際に構築されるRDBMSの特性を踏まえたER図へ変えるのもポイントです。
コンセプトモデルの棚卸し
コンセプトモデルの検討は、並行して進められている「システムアーキテクチャ検討」や「開発スコープ(システム境界)の明確化」などと、足並みをそろえながら進めていきます。例えば、システム境界明確化のために業務フロー分析を行なっているチームと、週に一度の相互レビューを実施しながら進めていくような感じになります。しかし、仮にこのような「相互レビュー」を実施していたとしても、業務フローに登場する概念がコンセプトモデルで表現されていない、などの抜け漏れが存在するものです。ですので、コンセプトモデルと業務フローが完成したこのタイミングで、いったん「棚卸」を行なっておくのが良いでしょう。具体的には、コンセプトモデルで表わされた領域に関して、「すべての業務フローが分析されているか」を評価したり、逆に「業務フローで分析した範囲がコンセプトモデルとして分析されているか」を評価したりします。また、開発スコープに含まれない領域をコンセプトモデルとして表現してしまっているかもしれないので、これを認知しておく必要があるでしょうこうして、開発スコープを過不足なくコンセプトモデルとして分析できているのかを「棚卸し」するというわけです。
UMLからER図へ「崩す」
論理モデル設計を行なうにあたって、まずやるべきことは、表記法をUMLからER図へ「崩す」という作業です。この作業では、主に「キー項目の検討」と「継承をER図に崩す」を実施します。
キー項目を検討する
コンセプトモデルではエンティティ間の関連の多重度のみが表現されており、主キーなどの「キー項目」という概念を考慮していません。これをER図に「崩す」ためには、まずキー項目を明確にしていく必要があります。まずは、モデルの中で主要な役割を担うエンティティのキー項目を検討しましょう。キー項目には、「ユーザーが意識するキー項目」(表に出てくるキー項目)と「システムの内部にのみ登場するキー項目」(表に出ないキー項目)が存在します。ユーザーが意識するキー項目とは、ユーザーが検索条件として入力されたり、画面や帳票に出力されたりする「コード」のことです。基本的には、現行の業務でユーザーが意識しているキー項目は、できる限り同じ体系で継続して使い続けたほうが良いと言えます。また、現在システム化されていない領域の場合、「現行の業務で意識しているキー項目」は存在しないので、ユーザーが業務を進めるうえで、長すぎず、かつ覚えやすいキー項目の体系を検討する必要があります。こうして、主要なエンティティのキー項目を検討できたら、次に、1:多の関連における「多」側のエンティティのキー項目を検討していきます。「1:多」関連のキー項目を検討する際には、「依存関連」と「非依存関連」という考え方を知っておく必要があります。依存関連とは「1」側のエンティティの主キーが「多」側のエンティティの主キーの一部となるような関連です。一方、非依存関連とは「1」側のエンティティの主キーが「多」側のエンティティの属性(非主キー項目)に含まれるような関連です(図29)。
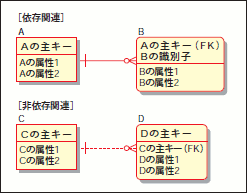
図29 依存関連と非依存関連
これをなぜ「依存関連」と呼ぶのか考えてみましょう。「1」側の主キーが「多」側の主キーの一部ということは、「多」側のエンティティが存在するためには「1」側のエンティティが必ず必要になります。つまり、「多」側のエンティティは「1」側のエンティティに依存しています。このためこれを依存関連と呼ぶのです(非依存関連はこの逆ですね)。
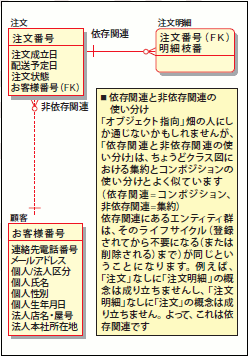
図30 依存関連と非依存関連の使い分け
例として図30をご覧ください。「注文明細」は「注文」なしに成り立たないエンティティですので、依存関連を用います。一方「注文」は「会員」なしに成り立つ概念ですので、非依存関連を用います。コンセプトモデル上の、「多:多」関連についても依存関連/非依存関連の考え方は基本的に同じになります。「多:多」のキー項目を検討する際には、まず「多:多」関連を、2つの「1:多」関連に分解します(図31)。「1:多」関連に分解できてしまえば、あとの理論は同じです。
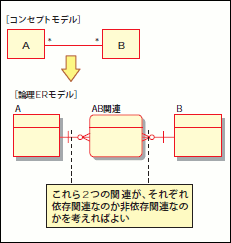
図31 「多:多」関連を2つの「1:多」関連に分解する
-- 継承をER表現に崩す --
コンセプトモデルは表記法がUMLということもあり、継承を利用している箇所も存在するでしょう。この継承の「ER図への崩し方」を解説します。継承をER図に崩すアプローチは、大きく分けて2つあります。1つが「1:0..1」関連を用いてサブクラスを表わすアプローチであり、もう1つが親クラス/サブクラスをひっくるめて1つのテーブルとするアプローチです(図32)。
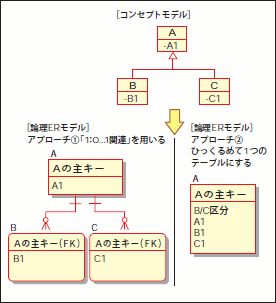
図32 継承をER図へ崩す2つのアプローチ
これらのアプローチを使い分けるための判断要因が「将来サブタイプが増える可能性があるか」という点になります。もし、増える可能性がある場合は、「1:0..1」関連を用いるアプローチを採用すべきでしょう。一方、増える可能性がない場合は、ひっくるめて1つのテーブルとするアプローチを採用すべきと言えます(図33)。
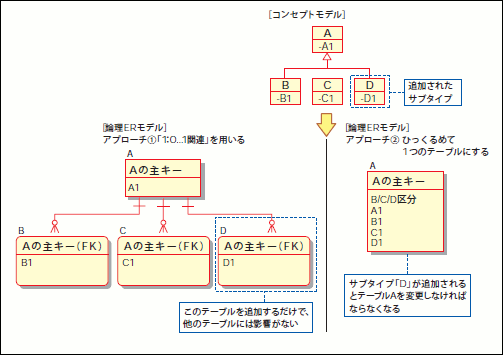
図33 サブタイプが増えた場合......
なお、コンセプトモデルで「分類」を表現するために、「とりあえず継承を使っておいた」ようなモデルに関しては、この考え方を適用する必要はありません。単純に、図34のようにER図へ崩せば良いのです。
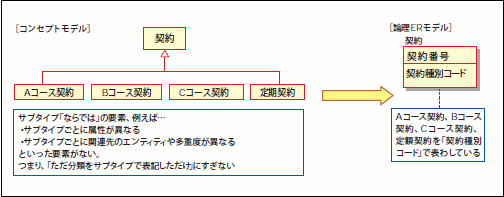
図34 「とりあえず継続」は素直にER図へ崩せば良い
属性を配置する
キー項目の検討と継承をER図へ崩す作業が完了すると、次にエンティティの属性を配置するフェーズへと移ります。現行システムのデータモデルや画面、あるいは帳票などから属性を抽出し、適切なエンティティへ配置していきます。こうして、属性を配置していった結果を、ER図やテーブル定義書に記していきます。本稿の冒頭で「論理モデル設計からは開発者向け」と述べましたが、この「属性配置フェーズ」を経た結果のデータモデルは、最低でも一度は顧客にレビューしてもらうのが良いでしょう(図35)。
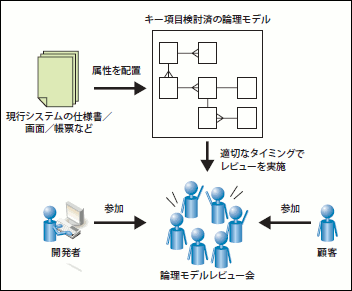
図35 属性抽出フェーズの流れ
導出項目や複写項目の検討
属性の配置がひととおり完了したら、次に導出項目や複写項目といった補完的な属性の検討を行ないます。導出項目とは、ほかの属性から類推することが可能な属性のことです。例えば、図36における注文エンティティの「合計税抜金額」は、注文明細エンティティの「数量」の値×商品価格エンティティの「単価」の総和によって計算可能な項目ですが、これをあえて属性として保持しています。これが導出項目です。
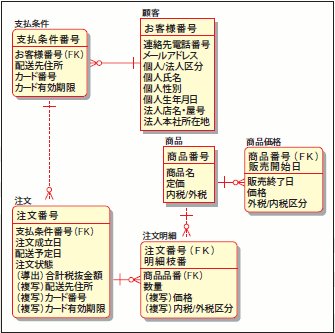
図36 導出項目/複写項目の具体例
導出項目は、その属性が「業務的によく利用される値」であるからこそ定義されます。例えば、前述の「合計税抜金額」では、「1回の注文あたりの合計金額が1万円を超えたら送料無料」や、「1回の注文あたりの合計金額が5000円を超えたらポイント2倍」といった要件があってこそ、「合計税抜金額」を導出項目として保持しておくということになります。一方、複写項目とは、ほかのエンティティが持っている属性の値を、別のエンティティに複写しておく属性のことです。例えば、図36における注文エンティティの「送付先住所」「カード番号」「カード有効期限」が複写項目になります。この複写項目は、コピー元である「支払条件」エンティティから複写した値ではありますが、「支払条件」のカード番号を変更した場合であっても、注文エンティティに保持されている「カード番号」は変更前のカード番号のままという点がミソです(図37)
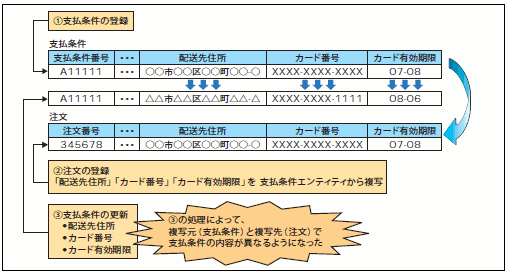
図37 複写元を変更した場合
これは、ある注文に対する支払のカード番号を調べるためには、"複写元を「支払条件」エンティティを参照してはいけない"ということを意味しています。"「注文」エンティティに持たれている「カード番号」こそが、その注文にとってのカード番号である"ということです。このように、複写項目を用いるとデータのアクセスに関して必ず何かしらのルールが生まれます。このため、ライフサイクル定義書やテーブル定義書といった成果物には、複写項目のアクセスに関する注意点などを記しておく必要があります。
物理モデル設計フェーズ
論理モデル設計が完了すると、続けて物理モデル設計フェーズへ移ります。物理モデル設計フェーズでは、主に次のような作業を行なうことで、「開発者が読むための論理モデル」から「実際にDBMS上に実装するための物理モデル」へのデータモデルを精査していきます。
- テーブル名/項目名に物理名(英語名)を定義
- 属性のデータ型/桁数/精度を定義
- パフォーマンスを考慮し「正規化崩し」を実施
- 検索効率を高めるための集計表(注17)の定義
- アプリケーション仕様を加味した一時表(注18)の定義
- 運用要件/移行要件/DBMS製品の特性などを加味した参照整合性の定義
なお、これらの作業は本稿の趣旨である「データモデリング」から少し外れた話になり、また誌面上の余裕もないため、詳細な説明は割愛させていただきます。
モデル微修正フェーズ
開発工程が基本設計に入るころまでには、物理モデル設計がひととおり完成している必要があります。そして、基本設計に伴うデータベース定義の微修正を行なっているのが、この「モデル微修正」フェーズです。基本設計/外部設計は、データモデルを念頭に置きながら、すなわちデータモデルをインプットとしながら設計されます。ですが、画面入出力項目などに関する仕様の検討に伴い、属性の増減や、桁数/精度の見直しがしばしば必要となります。また、パフォーマンスを考慮して、一時表や集計表といったエンティティが追加されるかもしれません。
このフェーズを「微修正」と呼ぶからには、大幅なモデルの見直しは行なわれるべきではありません。もし、このフェーズになって多重度が変更されるようなことがあれば、それはプロジェクトにとって「危険な匂い」と考えるべき重大な問題です(図38)。
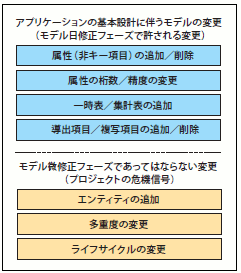
安定化フェーズ
基本設計が完了し、詳細設計/実装を行なっている段階になると、データモデルは「以降あまり変更されてはいけないもの」になります。言い換えると、詳細設計/実装工程へ入っても、データモデルを頻繁に変更しているような開発プロジェクトは「危険信号」が灯っていると言えるでしょう。この安定化フェーズで、データベースに関して行なうべき作業は「アプリケーションから実行されるSQLのパフォーマンスに責任を持つこと」です。特に大量なデータを取り扱う基幹系のシステムでは、インデックスが利かず時間が掛かってしまうSQLが1本存在するだけで、システム全体のパフォーマンスを低下させかねません。
このため、データベースアクセスに関する処理を、専任で設計/実装するチームを編成し、実行されるSQLに適切なパフォーマンスが出ることを担保する体制が必要になります。この専任チームは、実行されうるSQLの実行計画を分析し、適切なアクセスパスが得られるようにインデックスを定義していきます。実際の開発プロジェクトで、このようなチームを編成するのは実はなかなか見られない光景です。ですが、少なくとも実際に筆者が関わったいくつかのプロジェクトでは、このチーム編成でデータベースに関するパフォーマンスを担保してきました(注19)。「必ずこのようなチーム編成を組め」とは言いませんが、ご一考いただければと思います。
おわりに
以上でパート2は終わりです。冒頭でも解説したように、本稿は「開発プロジェクトの工程全体の中におけるデータモデリング」に焦点を絞って解説してきました。かなり駆け足だったとはいえ、開発プロジェクトという長い道のりの中で、データモデリングがどのように進められていくかをご理解いただけたのではないでしょうか。最後に、データモデリングにとって「センス」「経験」「理論」のどれが最も重要か、というお話をしたいと思います。筆者の私見では、1にセンス、2に経験、3が理論という順番になります。
「センスが一番大事」というのは身も蓋もない話ですが、実際のところ、異常にセンスの鋭いエンジニアが存在するのも事実です。センスの鋭い人は、若いうちからさまざまな開発プロジェクトで、DB設計を任されるようになります。言い換えると、データモデリングのセンスさえ持っていれば、さまざまなプロジェクトで重宝される、希少価値の高いエンジニアの地位を確立することができるのです。
もしあなたがデータモデリングの世界に興味を持っているのであれば、DB設計者というキャリアパスを視野に入れることをお勧めします。それは、とても奥深く、面白い世界で、しかもそのスキルは非常に希少価値の高いものです。筆者の担当パートに最後までお付き合いいただき、ありがとうございました。引き続き、パート3以降をお楽しみいただければ幸いです。
- 注2:Rational Unified Process(ラショナル統一プロセス)の略称。「R」を取って「UP」とも称される。
- 注3:eXtreme Programingの略称。
- 注4:設計~リリースを数週間の期間の「イテレーション」に分けて、繰り返しリリースを行なう開発プロセスのこと。
- 注5:少なくとも筆者はそのようなスタイルを見たことがありません。
- 注6:時々、「状態」をサブタイプで表現したようなモデル(例えば「発送前注文」と「発送済み注文」を「注文」のサブタイプとしたようなモデル)を目にしますが、これは推奨しません。「状態」を有するエンティティは「どういった要因で状態が変化するのか?」を整理することが重要になりますが、サブタイプではこの「状態が変化する要因」を整理できません。適材適所な表記法を選択しましょう。
- 注7:昨今、EAやSOAが認知されつつあるため、システム開発を伴わない「標準化基盤の整備」といったプロジェクトも増えているようです。このようなプロジェクトの場合、データモデリングそのものがプロジェクトの最終成果物となり、システムの構築は伴いません。
- 注8:余談ですが、この流派は弊社に在籍している「モデリングの師匠」から学んだアプローチです。
- 注9:「その場主義」「持ち帰り主義」は、先に紹介した渡辺幸三氏の書籍で詳しく解説されています。是非ご一読ください。
- 注10:実際のデータベースとのフォワード/リバースエンジニアリングができることがERモデリングツールの大きな「売り」になりますので、これはいたしかたないことだと思います。
- 注11:メタモデルとは、一言で言うと「定義情報を構造表現したモデル」です。「UMLのクラス図のメタモデル」とは、クラス図の表記法で「書くことができること」をまとめた「仕様」のようなものと考えてください。
- 注12:図22と図23を見比べて直感的に理解しやすいのは、明らかに図22のほうでしょう。
- 注13:ここでいう支払条件とは、注文に対する支払いの方法が「銀行引き落とし」なのか「クレジットカード払い」なのか、といった点や、銀行口座情報やクレジットカード情報などのことです。
- 注14:International Standard Book Numberの略称であり、図書(書籍)を識別するため国際規格。
- 注15:Japanese Article Numberの略称であり、バーコードなどで商品を識別するための規格。
- 注16:UMLでクラスを大まかに分類するための表記法、例えば「ブツ」として区別したクラスに>> ブツ<< というステレオタイプを書いておく。
- 注17:集計表とは例えば「月別商品別売上額集計テーブル」のように集計ロジックを実行すれば導出可能ではあるが、業務的によく参照されるため、保存しておくテーブルのことです。つまり、テーブルまるごとが導出項目というテーブルです。
- 注18:一時表とは、例えば他システムから受領するテキストファイルの内容を、ファイルレイアウトそのままの構造で、テーブルとして保持しておくようなテーブルです。つまり、設計の過程でシステムの「つくり」上の問題で必要になるテーブルのことを指します。
- 注19:このチーム編成で開発プロジェクトを成功させるためには、2つの条件があります。1つ目は多層アーキテクチャを採用し、レイヤごとに担当チームを編成すること。すなわち、データベースのI/O に関する処理の設計/実装は永続化層チームが担当すること。2つ目は、データモデリングの成果物としてテーブル設計書、ライフサイクル定義書がしっかり作られており、データベースにアクセスするためのサービスが、ビジネスロジック層を担当する人たちからも「見えている」環境を作ることです。
石川智久(いしかわともひさ)
中堅SIer を経て、2002 年よりウルシステムズ株式会社に勤務。現在関わっているプロジェクトでは、顧客企業の情報システム部門の中で、開発プロセスの効率改善に関するコンサルティングに従事しているが、自分のコアスキル/得意分野はモデリングの領域だと思っている。あるいは単なる「モデリング好き」かもしれない。ここしばらくは「開発プロセス改善コンサル」や「アーキテクト」の役割が続いており、モデリングがしたくてウズウズしている。