ネイティブXMLデータベースの歴史はXMLの歴史に他ならない。1998年にXMLがW3Cに勧告になると同時に、XMLデータを効率的に扱うためのネイティブXMLデータベースが登場した。続いて定められたXPath、XSLT、Namespaces、XMLSchema、XQueryといったXMLを扱うための主要な標準ができると、それらに対応する機能が追加されてきた。勧告から5年を経て、XMLは広く深くIT業界に普及したのに対し、ネイティブXMLデータベースは、当初期待されたほどには普及しなかった。
ところが、ここへ来てXML利用の本格化、XQueryの標準化の進展、新規ベンダーの参入等を背景に、ネイティブXMLデータベースが再び脚光を浴びるようになってきている。
本稿では、ネイティブXMLデータベースを選定する際に留意すべき点について、筆者等の経験を鑑みて示したい。特に、代表的なネイティブXMLデータベースとして選択した、Sonic XIS, Tamino, EsTerra, NeoCore XMS, Oracle 9i XMLDB, eXistについて、それぞれの特徴と実際に試用して得られた使用感について述べる。ここで、Oracle9iをネイティブXMLデータベースとしてとり上げられているのを不審に思われる読者がいらっしゃるかもしれない。実はOracle9i Release 2 から、提供しているXMLDBはXMLの階層構造をネイティブに扱うための、RDBとは異なる機能である。RDBの雄であるOracleがネイティブ方式を採用している事実が、XMLデータをネイティブに扱うアプローチの優位性を証明していると言える。
ネイティブXMLデータベースとは
ネイティブXMLデータベースは、一言でいうとXMLの特徴を生かした形で蓄積し操作が可能なストレージのことである。最大の特徴である階層構造についての扱いがRDBと異なっているという点が焦点ではあるが、その他の特徴もネイティブXMLストレージの性格を考える上で重要である。
データベースの性格を決めるXMLの特徴
XMLの代表的な特徴には、
- 階層構造
- メタ標準
- 自己記述性
- 関連標準
の4点が挙げられる。これらへの対応がネイティブXMLデータベースの特性に関わる。
(1)階層構造
XMLは、論理的な階層構造をテキストで表現したデータ構造である。元々、マニュアルや報告書などのドキュメントが持っている、章立てのような論理的な階層構造を計算機が扱うことのできるようなドキュメント記述言語SGMLをインターネットでの標準言語として選択、拡張したものである。同じくSGMLから派生したHTMLと同様にタグと呼ばれる記法によって記述される。リスト1に映画についての情報を表現したXMLデータの例
リスト1:XMLデータの例
<?xml version="1.0" encoding="Shift_JIS" ?>
<movies>
<movie>
<title>Star Wars</title>
<categories>Science Fiction</categories>
<director>George Lucas</director>
<cast>
<actor>
<name>Mark Hamill</name>
<role>Luke Skywalker</role>
</actor>
<actor>
<name>Harrison Ford</name>
<role>Han Solo</role>
</actor>
<actor>
<name>Carrie Fisher</name>
<role>Princess Leia</role>
</actor>
</cast>
</movie>
<movie>
<title>Harry Potter and the Sorcerer's Stone</title>
<categories>Fantasy</categories>
<director>Chris Columbus</director>
<cast>
<actor>
<name>Daniel Radcliffe</name>
<role>Harry Potter</role>
</actor>
</cast>
</movie>
</movies>
広く用いられているRDBでは、扱うデータの構造はリレーションと呼ばれる表の形式である。関係データベースを用いてXMLデータを管理するためには二つの方法がある。ひとつはBLOB(オブジェクト)やCLOB (テキスト)として格納する方法であるが、この場合は、せっかく持っている構造情報を利用した検索を行うことができない。もう一つはXMLの要素を表の構造にマッピングする方法であるが、XMLの高い記述力を生かすために複雑な構造を用いれば用いるほど、マッピングが大変になり、検索のパフォーマンスも低下してしまう
(2)メタ標準
HTMLと比較したときのXMLの大きな特徴は、階層構造を定義するためのスキーマが用意されていることである。HTMLに含まれるタグはレイアウトに関わるものに限られるが、XMLではスキーマを用いて利用者が定義できる。スキーマを規定することによって、XMLの要素の持つ意味を計算機に伝えることができ、自動処理を可能にする。この特徴により、標準を定義するための標準、つまりメタ標準として振る舞うので、アプリケーションの種類や業界などに共通な標準フォーマットを定義するのに利用されているのである。スキーマにはいくつかの種類があり、SGML時代から用いられているDTD (Data Type Definition)やW3Cで勧告になっているXML Schema、OASIS標準のRELAX NGなどがある。いずれもXMLの構造に含まれる要素やその構造について制約を与えることができる。リスト2に前述の映画データ
(3)自己記述性
XMLの構造はスキーマによって定義することできるが、XMLのデータ自体は必ずしもスキーマを必要とせず、それだけで意味を表現することができる。RDBのデータはスキーマがなければ、意味のない数値データや文字列データの集合に過ぎないが、XMLでは構造とデータの両方を記述する。このため、XMLデータはスキーマがなくても計算機によって処理できる。スキーマを持ちその制約を満たすことを保証されているXMLデータを検証済み(Valid)XMLと呼ぶ。これに対して、XMLのシンタックスを満たすだけのXMLデータをウェルフォームド(well-formed)XMLと呼ぶ。ウェルフォームドXMLを扱うことができるかも、ネイティブXMLデータベースも重要な性質である。
リスト2:XMLデータの例
<?xml version="1.0" encoding="Shift_JIS"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="movies" type="movies"/>
<xsd:complexType name="movies">
<xsd:sequence>
<xsd:element ref="movie"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="movie">
<xsd:sequence>
<xsd:element ref="title"/>
<xsd:element ref="categories"/>
<xsd:element ref="director"/>
<xsd:element ref="cast"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="cast">
<xsd:sequence>
<xsd:element ref="actor"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="actor">
<xsd:sequence>
<xsd:element ref="name"/>
<xsd:element ref="role"/>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="categories" type="xsd:string"/>
<xsd:element name="director" type="xsd:string"/>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="role" type="xsd:string"/>
</xsd:schema>
(4)関連標準
XMLのデータ構造は、従来にない複雑な構造を表現できるが、その反面、操作はそれまで以上に難しくなる。そのため、XMLを標準として勧告しているW3Cは、XMLを扱うための各種の標準を開発している。例えば、スキーマを記述することのできるXML Schema、XMLの階層構造をオブジェクト指向で表すためのDOM (Document Object Model)、構造の変換を行うためのXSLT (eXtensible Stylesheet Language Transformations)、階層構造の特定の場所を指定するためのXPath、複数のスキーマに対応するための名前空間を規定するNamespaces in XML、XMLを検索するためのXQuery等が代表的な関連標準である。これらの標準とそれに準拠したApache XercesやJAXPなどのJavaのライブラリの存在によって、XMLの利便性は大きく変わってくる。関連標準にどの程度準拠しているかが、ネイティブXMLデータベースの適用範囲に大きな影響を与える。
ネイティブXMLデータベースが普及しなかった理由はいくつかある。主要な要因とそれが現在どのように変化してきているのか見てみよう。
(1)不適切なソリューションへの適用
初期の事例では、XMLの特徴を生かすことのできないソリューションに適用したために、XMLデータベースの欠点ばかり目立つ結果に終わったものが多かった。XMLに対する過度の期待から、既存のデータベース中にレコードあるいはテーブル形式で格納されていたデータをXMLデータにして活用しようとする事例が多く見られた。従来の技術でできていた範囲の処理をわざわざXMLデータベースで行ったわけで、RDBで十分あるいはRDBのほうがパフォーマンスが良いという結果になったのは当然といえよう。微妙なケースとしては、XMLデータが送受信されるXML-EDIのソリューションへの適用がある。この場合、XMLメッセージが交換されるわけだが、結局、企業内ではデータはホストコンピュータやRDBで蓄積されたものを使うということであれば、XMLデータベースを使用する価値はあまりない。
XMLデータだけでシステムが作れない場合が結構あるということにも注意を要する。例えば、電子カタログシステムを作るような場合、カタログ検索はXMLの利用に適しているが、全製品について価格を日々更新したいといった、RDBのほうが適している機能も必要になる。XMLデータベースは検索を高速化する手段は多数用意しているが、更新はあまり高速化できないことが多い。そのため、こうした機能の実現にまでXMLデータベースを使用するのはパフォーマンスの低下を招くことになる。
現在、XMLが広く普及したため、最初からXMLデータを作ることのできるアプリケーションが増えてきている。Microsoft Office 2003などはその代表格である。作成時点からXMLデータであり、活用もXMLデータで行うことが前提になってくれば、わざわざRDBにマッピングすることなく扱うことができるネイティブXMLデータベースの利用の必然性は高くなる。
(2)データベース機能の未成熟
ネイティブXMLデータベースの初期のバージョンでは、基本的なデータベース機能が未成熟といわざるを得ない面が多分にあった。まず、初期のネイティブXMLデータベースでは1G以上のデータを投入するのが難しい、あるいは投入できてもパフォーマンスが極端に低下することが多かった。また、トランザクション機能が不十分でデータの安全性を保てないものなどもあり、試用し評価した結果、本採用を見あわせるといったことが頻発し、ネイティブXMLデータベース全体の地位低下をもたらす結果となった。
現在では、代表的なネイティブXMLデータベースでは、アーキテクチャの全面見直しがなされ、これらの基本機能の性能は大幅に向上している。現在では、数10G以上のデータを扱うことのできるネイティブXMLデータベースは珍しくない。性能も大幅に向上し、チューニング次第では、100tps以上の性能を得ることができる。トランザクション機能についても、代表的なネイティブXMLデータベースはすべて対応している。
(3)利用ノウハウの不足
これまで普及を阻害してきた最大の要因は、ネイティブXMLデータベース利用ノウハウが普及していないことにある。RDBでもネイティブXMLデータベースでも、扱うデータの規模が大きくなると、必要なパフォーマンスを出すためのチューニングが必要になることには違いがない。このためのノウハウがあるかどうかで、開発プロジェクトの成否が分かれることは少なくない。RDBの場合は、ある程度の規模のシステムインテグレータであれば、RDBでのシステム構築の経験が豊富なエンジニアは必ずいる。また、優れた入門書や解説記事を入手することも容易である。これに対し、ネイティブXMLデータベースでは、必要な情報が得られないために、ベンダーの支援を得られなければ目標とする機能の実現ができないようなことが起きていた。
この利用ノウハウの流通の課題は、残念ながら現在も解決されてはいない。解説記事もカタログスペックを比較する程度のものが多く、有用なノウハウは得られない。また、データベースの原理が異なるためベンダーごとに同じ機能を別の名前で呼んでいたり、階層構造を扱うための当たり前の機能を特別な機能であるかのように説明したりするため、非常にわかりにくくなっている。本稿は、筆者等の経験からの活用ノウハウを提供することで、情報不足を少しでも補いネイティブXMLデータベースの有効活用の一助とすることを狙いとしている。
ネイティブXMLデータベースの選定
主要機能
ネイティブXMLデータベースが共通に提供する基本機能について、eXistを例にして説明する。ここでは、前述の
(1)データベース作成
最初にディスク上にデータベースの領域を作成する必要がある。eXistではインストールするとデフォルトのデータベースがひとつ生成される。多くの製品では任意の個数のデータベースを作成することができる。スキーマの利用を前提としている製品の場合には、各データベースにXML Schemaを設定する等の操作が必要になる。eXistはスキーマをサポートしていないので、スキーマの設定の操作は不要である。
(2)XMLデータ登録
作成したデータベースにデータを登録する。図※1に、eXistを用いて
(3)XMLデータを検索
データベースからXMLデータを検索する。図※2に、eXistでHarrison Fordという名前の俳優を検索した結果を示している。findコマンドを用いたXPath検索によって件数のみを取得し、showというコマンドを用いて検索結果を表示している。現在、ネイティブXMLデータベースが提供している検索の手段は、主にXPathによるものとXQueryによるものである。XQueryは2003年12月時点でワーキングドラフトの状態なので、どのドラフトに準拠しているのかは確認が必要である。
(4)インデックスの設定
XMLデータに対してインデックスを定義してパフォーマンスを改善することができる。一般に階層型のデータを探索する場合、上位の階層から順に条件が合致する要素を順にたどる必要があるが、インデックスは本の索引と同様に、値から該当する要素へ直接アクセスする手段を与えるもので、検索の効率化には不可欠なメカニズムである。eXistではデータ登録時に、自動的にインデックスが作成されるため、特に設定する必要はない。逆にすべてのテキストにインデックスが作成されると大量データが投入された場合に遅くなることがあるのでインデックスの対象から除外すべきものを指定する。リスト3はインデックス対象から除くノード(ここではrole)を指定した例である。
インデックスには値インデックス、構造インデックス、全文検索インデックスなどの種類がある。製品によっていろいろな名前で呼ばれるが、基本的な考え方は変わらない。
リスト3:インデックスの対象から除くノードの指定例(eXist)
<index attributes="true" alphanum="true" doctype="movies" default="all">
<exclude path="//role"/>
</index>
リスト4:データの更新指定の記述例(eXist)
eXistのインストール
eXistはオープンソースのネイティブXMLデータベースのひとつである。詳細は各製品の特徴の項で述べるが、ここでは、eXistをWindows環境にインストールする方法について説明しておく。実行環境として、J2SE 1.4.xがインストールされており、PATHおよびJAVA_HOMEが環境変数として設定されていることを前提とする。インストーラは http://exist.sourceforge.net/index.html からダウンロードすることができる。今回は、現在の最新バージョンである eXist-0.9.2-install.jar をダウンロードした。インストールは、ダウンロードしたファイルのアイコンをダブルクリックするか、DOSウィンドウから以下を実行することで行える。
C: java -jar eXist-0.9.2-install.jar
インストール先はデフォルトの設定ではProgram Filesの下になるが、スペースの入らない任意のディレクトリに変更することをおすすめする。その他は「Next」ボタンを押していくだけでインストールは完了する。 eXistにデータを登録する前にサービスを起動する必要がある。起動するにはWindowsのメニューから「eXist Database Startup」を選択する。停止するには同様に「Shutdown Database」を選択する。サーバの状態はブラウザからhttp://localhost:8080/exist/statusにアクセスすることで確認できる。
データベースにアクセスするために、WebブラウザとClient ShellというSwingベースのGUIツールの二つの手段が使えるが、どちらもほぼ同様の機能を提供している。ブラウザの場合はhttp://localhost:8080/exist/xadmin.xspからログインする。Client ShellはWindowsのメニューから起動する。初期設定ではパスワードが設定されていないのでIDをadmin、パスワードを空白としてログインする
- 値インデックスは、指定された値を持つ要素を特定する。元々XMLデータでは、値はテキストのみであるが、スキーマを定義することのできるデータベースの場合、数値などの型を持った値として扱うことができる。
- 構造インデックスは、指定された構造(パス)のある位置を特定する。この変形として、構造と値を一緒にしたインデックスを持つものもある。
- 全文検索インデックスは、全文検索を可能にするためのもので、文を単語に区切り、その単語のある位置を特定することを可能にする。日本語の文から単語を切り出す処理は、形態素解析と呼ばれる。
(5)XMLデータの更新
格納されているXMLデータの一部を更新する。リスト4にeXistで更新のために用いる更新言語の例を示す。この例では、新しい映画の情報としてMatrixの情報を追加している。XMLデータをどの単位で更新できるかは重要な特徴になる。値だけしか修正できないもの、要素の追加ができるものなど様々である。また、更新時に排他制御のためにどの範囲のロックがかかるのかも重要である。
ネイティブXMLデータベースでは、これらの基本的なデータ操作以外にも、トランザクションやユーザ認証などデータベースの利用に必須の機能、開発や運用のためのツールや環境を提供している。また、プログラムからの呼出しのためのAPIも提供している。これらネイティブXMLデータベースを特徴づける項目についてまとめたものを表※1に示す。
製品選定のためのプロセス
データベースの選定の作業は、要件定義が終了し、基本設計を行うタイミングで行われる。製品の候補を選定する前後で行う要件の明確化とプロトタイピングがとりわけ重要である。
選定前の要件の明確化
選定の前に十分検討しなければならないのは、XMLデータをネイティブに管理・検索する必然性が本当にあるのかという点である。構造が複雑なためリレーションへのマッピングが困難になる、あるいは、入力も出力も複雑なXMLデータであるといった案件であれば、その必然性は高いと言える。
次にXMLデータベースを全体システムの中に位置づける。ユーザの要求を満たすためにどのような構造を持つXMLデータを蓄積しそれをどのように検索するのかを明確にすることが重要である。特に注意したいことは、RDBとの併用を行うかどうかという点である。一般に、ネイティブXMLデータベースは、頻繁な更新はあまり得意ではない。たとえ主要なデータがXMLであったとしても、こうした機能も必要ということであれば、それをRDBに任せてしまえるのか、ネイティブXMLデータベースだけで対応しなければならないのか、立場を明確にしておく必要がある。
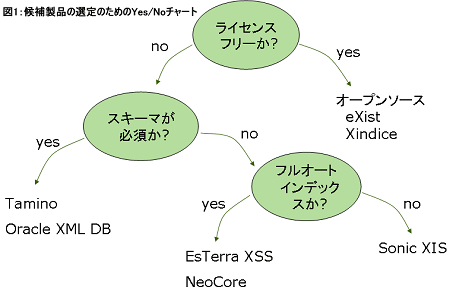
図1:候補製品の選定のためのYes/Noチャート
パフォーマンス要件の明確化も必要だ。このときに注意することは、XMLデータを検索した後の処理時間を忘れないことである。XMLデータの処理は一度パースする必要があるため、オーバーヘッドが大きい。この点を見越してパフォーマンス要件を設定する必要がある。
候補の選定
製品の候補を選定する際の意志決定の主要な要因は図※4に示すようになる。
ライセンスフリーか?
作成したプログラムを無償で配布する必要がある場合などには、ライセンスフリーの製品が必要になる。オープンソースで提供されているネイティブXMLデータベースはいくつかある。本稿で紹介しているeXistやApache Xindiceなどがその代表格である。ただし、どうしても無償でないといけない場合を除いてライセンスフリーのストレージを選択するのはお勧めしない。ソースが公開されているとはいえ、システムの中核に品質維持の体制が保証されないデータベースを使うリスクは避けるべきだろう。例えば、Xindiceなどは雑誌などに取り上げられたため注目されているが、現在開発が滞っておりJ2EE 1.4.xの環境ではコンパイルすら通らない。
スキーマが必須か?
データベースを構築するためにXML Schemaの指定が必須であるかどうかでデータベースの提供できる価値が大きく変わる。どちらが適しているかは要件次第であるが、XMLに求めるものが階層構造による複雑さへの対応だけなのか、自己記述性による柔軟性の実現も必要なのかで変わる。XMLで表現するデータの構造がRDBで扱うには複雑だけれども、バリエーションは少なく、変化もない場合には、スキーマを必要とする製品を利用できる。Tamino、Oracle XMLDBがこれに該当する。
XMLデータの構造が複雑な上、柔軟な変更の必要もある場合には、スキーマを必須としないウェルフォームドXML対応した製品を利用するべきである。Sonic XIS、EsTerra XSS、NeoCore XMSがこれに該当する。柔軟な構造を生かすことで、あらかじめ想定できない構造やあるいはバリエーションが多い構造に対応できる。
一般にウェルフォームド対応の製品のほうが利用するための敷居が低いが、データベース中のXMLデータが想定されている処理に必要な構造を持つことをスキーマ以外の方法で保証する必要はある。多くの場合、XMLデータはプログラムによって生成されるので、設計時に気をつければよい。なお、ウェルフォームドXML対応の製品でも投入時にスキーマの妥当性検証を行う機能を持つものがあるが、データの更新時の妥当性検証まではしてくれない。これだと登録時に妥当性検証を別のプログラムで行うのと大して変わりがない。
リスト5:映画の賞に関する情報を表すXMLデータ
<Awards>
<Academy>
<Nominee>Best Art Direction</Nominee>
<Nominee>Best Film Editing</Nominee>
<winer>Best Visual Effects</winer>
</Academy>
</Awards>
フルオートインデックス機能
ネイティブXMLデータベースは、高速化のためにはインデックスを設定する必要があり、この設計が利用の難しさを増大させていた。インデックスは高速化の切り札であるが、ではすべてに設定すればよいかというと、逆にインデックスの探索と更新がネックになってくる。多くの場合、インデックスを設定しすぎると更新の時間がかかるというトレードオフがある。フルオートインデックス機能は、自動でインデックスの設定を行ってくれる機能であり、チューニングに関わる設計者の負担を軽減する効果がある。EsTerra XSSとNeoCore XMSがこれに該当する。
プロトタイピング
プロトタイピングによる性能評価は、ネイティブXMLデータベースを選定する際に省略できないステップである。蓄積するXMLデータの構造、検索や更新に使うスクリプトなどはいずれもパフォーマンスに大きく関わるので可能な限り実際に使用するものを用意する。また、データの規模によってパフォーマンスが急に変化することもあるため、十分な規模のデータを準備してベンチマークを行いたい。パフォーマンス要件を満たせない場合には、チューニングが必要になる。検索式、インデックス、データ構造の変更を行うことでパフォーマンス要件を満たすかどうかを見てゆく。チューニングの結果、XMLとしてあまりにも歪な構造、あるいはネイティブXMLデータベースである必然性のない構造になってしまわないように気をつけなければならない。
各製品の特徴
次に、代表的なネイティブXMLデータベース製品の特徴と実際に試用した使用感を示す。
Tamino
独Software AG社により開発された老舗のネイティブXMLデータベースである。国内では(株)ビーコンITが販売している。試用したバージョンは4.1.1である。
特徴
開発元のSoftware AGは30年以上にわたって、ADABUSという階層型データベースを開発・販売しており、そこで培われた技術をXMLに応用した製品である。なお、現在のバージョンは、ADABUS上に構築されたものではないとのことである。
階層型データベース (図※5)
Taminoはスキーマを前提とする製品で、コレクションと呼ばれるXMLデータをまとめる単位ごとにスキーマを設定できる。1つのデータベースには複数のコレクションが定義でき、各コレクションは複数のスキーマを束ねたスキーマグループを持つ。各スキーマにはルート要素を表すDocTypeが定義されそれに対応したXMLデータを格納するためのインスタンスグループが作られる。インスタンスグループ内のXMLデータは、構造を持ち、圧縮して格納される。
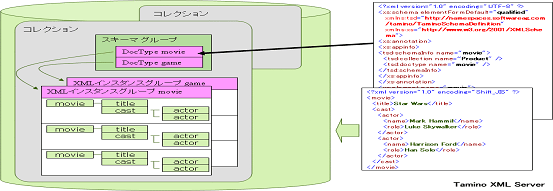
図5
Taminoスキーマ
コレクションに設定するスキーマは、Taminoスキーマと呼ばれ、XML Schemaのサブセットとして、固有の拡張を行ったものである。スキーマの変更は、構造の制約を追加する方向であれば、データの再ロードを行うことなく行える。Taminoスキーマは製品に付属する「Tamino Schema Editor」で作成することができる。DTD、XML Schemaがある場合は、それらをTaminoスキーマへ変換することもできる。
インデックスによる高速化
高速化はTaminoスキーマに対してインデックスを設定することで行う。構造、値、全文検索インデックスのいずれもあり、値インデックスは型もみることができる。
RDBとの連携
オプションであるTamino X-Nodeを利用することで、RDBに格納されているデータとの連携ができる。TaminoスキーマにRDBのテーブルとの関係を指定することで、RDBのテーブルをXML構造にマッピングすることができる。これにより、企業内で分散しているデータを、ひとつのデータベースとして扱うことが可能になる。これをSingle Server Viewと呼んでいる。
TConnection tcon = TConnectionFactory.getInstance()
.newConnection ("http://localhost/tamino/mydb") ;
Java API
データベースへのアクセス手段として、HTTPを使用しWebサーバを経由するものと、TCP/IPの独自プロトコルを使用しWebサーバを経由しないWebサーバレスアクセスの2種類を提供している。後者のほうがHTTP通信時のオーバーヘッドがなくなるため性能が向上する。リスト6は、Webサーバレス アクセスによる検索の例である。11行目がWebサーバレス アクセスの指定である。HTTPを使用する場合には、
TConnection tcon = TConnectionFactory.getInstance()
.newConnection ("http://localhost/tamino/mydb") ;
に変更する。
リスト6:JavaAPI
1: import com.softwareag.tamino.db.api.accessor.*;
2: import com.softwareag.tamino.db.api.connection.*;
3: import com.softwareag.tamino.db.api.objectModel.*;
4: import com.softwareag.tamino.db.api.objectModel.dom.*;
5: import com.softwareag.tamino.db.api.response.*;
6:
7: public class TaminoQuery {
8:
9: public static void main(String[] args) {
10: try {
11: TConnection tcon = TConnectionFactory.getInstance().newConnection
("wsl:///tamino/mydb") ;
12: TXMLObjectAccessor tacc = tcon.newXMLObjectAccessor (
13: TAccessLocation.newInstance("movie"),
14: TDOMObjectModel.getInstance() ) ;
15:
16: TLocalTransaction tloc = tcon.useLocalTransactionMode() ;
17: TQuery query = TQuery.newInstance ("/movie[title ='Star Wars']") ;
18:
19: TResponse tresp = tacc.query (query,5);
20:
21: int totalCount = 0 ;
22: TXMLObjectIterator ti = tresp.getXMLObjectIterator() ;
23: while (ti.hasNext()) {
24: totalCount++;
25: ti.next().writeTo(System.out,"Shift_JIS");
26: System.out.println("");
27: }
28: tloc.commit();
29: tcon.close ();
30: } catch(Exception e) {
31: e.printStackTrace() ;
32: }
33: }
34: }
使用感・コメント
試用した範囲では安定して動作し、開発ツールも充実しており使いやすい。XMLスキーマが前提であるため開発の敷居は高いが、開発支援のツールによって軽減されている。アーキテクチャの見直しや最適化によって以前のバージョンに比べて性能が大幅に向上しているとのことである。
ウェルフォームドXMLも扱うことが可能であるが、インデックスを設定することができないので検索時性能は期待できない。試用版では、使用期限以外に容量制限が設定されており、20Mバイトを超えるデータベースを作成することができないのでパフォーマンスについてはコメントできない。
リスト7:JavaAPI
1: import java.sql.Connection;
2: import java.sql.DriverManager;
3: import java.sql.ResultSet;
4: import java.sql.Statement;
5: import oracle.jdbc.driver.OracleResultSet;
6: import oracle.xdb.XMLType;
7:
8: public class OracleQuery {
9:
10: public static void main(String[] args) {
11: String qry ="select x.movie.extract('/movie') from MOVIE_XML x "
12: + "where x.movie.existsNode('/movie/title[text() = "Star Wars"]') = 1";
13: try {
14: Class.forName ("oracle.jdbc.driver.OracleDriver");
15: Connection conn = DriverManager.getConnection ("jdbc:oracle:oci8:@HS","scott", "tiger");
16: Statement s = conn.createStatement();
17: ResultSet rset = s.executeQuery(qry);
18: OracleResultSet orset = (OracleResultSet) rset;
19: while(orset.next()){
20: XMLType xt = XMLType.createXML(orset.getOPAQUE(1));
21: System.out.println(xt.getStringVal());
22: }
23: } catch (Exception e) {
24: e.printStackTrace();
25: }
26: }
27: }
Oracle XML DB
Oracle 9iは、米国Oracle社の主力データベース製品である。Oracle 9i Release 2 以降のバージョンでネイティブXMLデータベースとしての機能が登場した。試用したバージョンは9.2.0.3である。
特徴
XML DBと呼ばれるRDBとは異なるメカニズムで動作するXMLデータ用のストレージが提供されている。このストレージは、オブジェクトリレーショナルデータベース機能をベースにネイティブXMLデータベースを実現している。
複数のXMLデータ格納手段
RDBが扱うリレーションは二次元の表(テーブル)に見立てることができるが、Oracleでは、この表の各マス目(セル)の中でオブジェクトを扱うためにユーザ定義型という機能を提供している。この機能を使えば、セルの中に階層構造を持たせたり、セルから他のテーブルを参照してテーブルのネストを作ったりすることで、ユーザは任意のオブジェクトを定義することができる。このメカニズムを利用してXMLデータに特化したXMLTypeというデータ型とそれを利用する関数群を提供したのがXML DBである。
XMLTypeでは非構造化ストレージと構造化ストレージの二種類での扱いが可能だ。非構造化ストレージはセルの中にXMLのテキスト(CLOB)を格納するもので、スキーマの必要のないウェルフォームドXMLを扱うことができる。もうひとつが構造化ストレージで、XMLType型のセルにXML Schemaを指定することで、セルの中に構造を持ったXMLデータを格納することができる。この他に、XMLデータをRDBのテーブルにマッピングするためのOracle XML Developer's Kitも提供しているので、ユーザはデータの特性に応じてXMLデータを扱うための3種類の方法を選択することができる。
SQLに統合化されたXMLストレージ (図※6)
XMLTypeはSQLで扱えるデータ型であるため、PL/SQL、JDBC、各種のビューの機能から、他のデータ型と同様に扱われる。XMLの構造を扱うためのXPath検索、XSLT変換などの関数が用意されている。構造に基づく検索はSQL からXPath式を用いた関数を呼び出すことによって実行される。XPathの問い合わせは、内部的にネストされたオブジェクトに直接アクセスする形式に変換されて実行される。この最適化の手法はクエリ・リライトと呼ばれている。また、通常のリレーションに対するSQLでの検索結果からXMLを生成する関数群も用意されている。
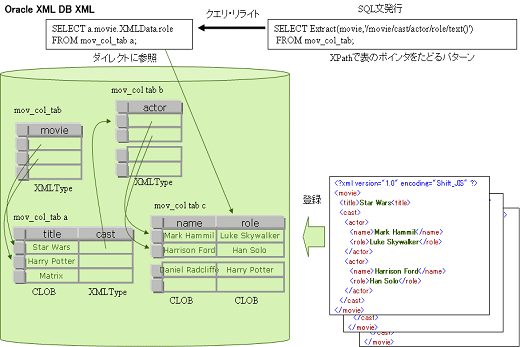
図6
インデックス
XMLTypeのデータには、関数インデックスとテキストインデックス(Oracle Textインデックス)が用意されている。関数インデックスは関数の実行結果をインデックスとして用いるもので、例えばXPathで検索を行う関数に関数インデックスを設定することで、構造インデックスと同等のインデックス指定が行える。なお、関数インデックスは、一度実行しないと有効にならないことに注意が必要である。
ビューの利用
XMLTypeのデータと通常のリレーションを透過的に扱うためにビュー機能が提供されている。XMLTypeビューは、リレーションをXMLTypeのデータとしてアクセスすることを可能にする。逆にリレーショナル・ビューは、XMLType型のデータをリレーションとしてアクセス可能にする。
Java API
JDBCドライバのTypeII(OCI)を使用することになる。リスト7は、JDBCを使用した、XMLType操作の例である。6行目で、XMLTypeのクラスをインポートしている。プログラミングは通常のJDBCを使用した場合と差がないところに注目していただきたい。
リスト8:JavaAPI
1: import com.exln.dxe.Session;
2: import com.exln.dxe.XMLStore;
3: import com.exln.dxe.XPath;
4: import com.exln.dxe.XlnTransaction;
5: import com.exln.dxe.engine.XlnLocalSessionFactory;
6: import com.exln.dxe.filesystem.XlnInputStream;
7:
8: public class XISQuery {
9:
10: public static void main(String[] args) {
11: try {
12: Session s = XlnLocalSessionFactory.getSession();
13: XlnTransaction txn = s.getTransaction();
14: txn.begin(XlnTransaction.TXN_READ);
15: XMLStore theStore = s.getXMLStore("Test");
16: XPath x = s.createXPath("/movies/movie[title ='Star Wars']");
17: int status = x.execute("Test:/dir1/movies.xml");
18: XlnInputStream xis = x.exportResults();
19: String result = xis.getStringContents("UTF-8");
20: System.out.println(result);
21: txn.commit();
22:
23: } catch ( Exception e ) {
24: e.printStackTrace();
25: }
26: }
27: }
使用感・コメント
RDBとネイティブXMLデータベースの一台二役で、XMLデータを格納するために適切な方法を選択できるという点が最大のメリットである。ある程度の規模のシステムの場合には、ネイティブXMLデータベースとRDBを併用するのが効果的なことが多いので、コスト面でも魅力である。ライブラリが統合化され、お互いの機能を透過的に参照するビューの機能を提供されているため二種類のシステムの連携に気を使う必要もない。
試用した印象では、さすがにマッピングのアプローチよりもパフォーマンスは高く、ネイティブアプローチの優位性が証明されたといって良いだろう。ただ、格納方式が選択でき、かつそれぞれが異なる原理で動作しており、内部的にも最適化が行われているため、どのような設計にすれば最適なパフォーマンスを得られるのかの判断は難しい。実際、短い試用期間では、ありきたりのインデックス設定以上のことはできず、十分なパフォーマンスを引き出せるところまでの確認には至らなかった。Oracleという冠はついているが、これまでのRDBの利用ノウハウとは全く異なる特性を持つことをよく理解した上で、選定時のプロトタイピングは十分に行う必要があるだろう。
Sonic XIS
米国プログレスソフト社のビジネスユニットであるソニックソフトウェア社により開発、販売されている老舗のネイティブXMLデータベースである。試用したバージョンは3.1.2である。
特徴
オブジェクト指向データベースであるObjectStore(プログレスソフト社)をデータベースのコアにして、XML処理エンジンやAPI、XML関連標準の統合開発環境を搭載した製品である。
DOMデータベース
Sonic XISは、ウェルフォームドXMLを、XML操作の標準インタフェースであるDOM(Document Object Model) オブジェクトの形式で格納する。XMLの処理は、最初にパースしてDOMオブジェクトの構造を構築するという負荷の大きい前処理が必要になるが、この処理の負担を軽減することができる。
メモリデータベース (図※7)
高速化の原理はメモリーへのキャッシュによる。データベースに格納されたDOMオブジェクトへのアクセスが行われると、クライアントプロセスのアドレス空間にキャッシュされる。この機構はキャッシュフォワードアーキテクチャと呼ばれる米国特許技術である。以降のアクセス時は、メモリー上のキャッシュが使用され、他のクライアントプロセスが更新や削除を行わないかぎり、データベースへのアクセスは行われない。更新や削除が行われた場合は、データベースへのアクセスが発生するがDOM全体ではなく変更部分のデータによりキャッシュの更新を行う。
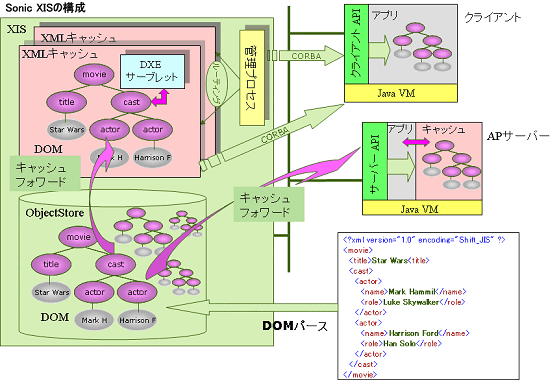
図7
分散XMLキャッシュ
キャッシュフォワードのメカニズムは、管理プロセスと、DOMオブジェクトをキャッシュするXMLキャッシュと呼ばれるプロセスによって実現される。このXMLキャッシュは、同一マシン上で複数配置することとは勿論のこと、異なるマシン上へも配置が可能だ。これにより大量のアクセスを複数のXMLキャッシュに振り分け、負荷分散が可能となる。同一マシン上で分散XMLキャッシュの設定した場合は、クライアントからのアクセスに対して、自動的に振り分け(ルーティング)が行われる。この振り分けを行うプロセスが管理プロセスである。
Java API
大きく2種類に分かれる。1つはDXEクライアントAPIと呼ばれ、XMLキャッシュとの通信にはCORBAを使用している。このAPIでは、トランザクション制御は行えない。もう1つはサーバサイドAPIで、これはXMLキャッシュ上で動作するDXEサーブレット内から使用される場合とXMLキャッシュを使用せずに直接、自分のプロセスへDOMオブジェクトをキャッシュする場合に使用される。DXEサーブレットとは、いわゆるhttpサーブレットではなく、サーブレットAPIに準拠した処理モジュールで、XMLキャッシュプロセスをコンテナとして実行される。サーバサイドAPIは、トランザクション制御を行いたいような場合に利用するが、独自のTCP/IP通信が使用されるため、CORBA通信時のオーバーヘッドがなくなりDXEクライアントAPIより良い性能が得られるというメリットもある。リスト8にサーバAPIを使用した例を示す。
この他に、Javaプログラムから、XMLドキュメントをJavaオブジェクトとして操作可能にするデータバインディングをベースとする手段も提供されている。XMLSchame対応のオープンソースのデータバインディングのライブラリであるCastorをベースにした「DXE Java-XML Data Binding framework」が製品に付属している。これを用いることでDOMの操作を知らなくても、プログラミングが可能になる。
使用感・コメント
メモリスピードでの高速アクセスができ、データへのアクセスごとにDOMパースが不要という点は高く評価できる。ただし、十分なパフォーマンスを得るためにはサーバサイドAPIを使用することが必須である。開発を支援するツールも充実しおり、特に、XML関連標準を統一したビューで開発するためのIDE(統合開発環境)であるStylus Studioは、単品でも販売されており完成度が高い。
大規模データを扱う場合は、慎重な設計が必要である。XMLキャッシュを複数配置することを前提とした設計が必要であり、XMLキャッシュを1つで大規模データを扱うような設計にしてはならない。XISのアーキテクチャは、クライアントのアドレス空間にデータをキャッシュする方式であり、32bitプロセスでは、アドレス空間は4Gバイトとなる。このアドレス空間は、OSやプログラムコード、シェアードライブラリ等でも使用されるので、データキャッシュに使用できるサイズは、4Gバイトより小さくなる。従って、大規模データを扱う場合、XMLキャッシュを複数配置する必要が生じる。このアーキテクチャを良く理解して設計する必要がある。
EsTerra XSS
EsTerra XSS (XML Storage Server)は、国内ベンダーである(株)メディアフュージョンによって開発された、日本発のネイティブXMLデータベースである。試用したバージョンは1.1である。
特徴
EsTerraは、同社により2001年に発売されたYggdrasillの後継機種である。Yggdrasillは、フルオートインデックスによる設計の簡便さと、メモリー上にデータを配置することにより実現される高速検索を特徴とするネイティブXMLデータベースであった。EsTerra XSSは、同製品の市場での経験から、スケーラビリティとトランザクション機能を強化するために、アーキテクチャから大きく見直しされた製品で、異なる特性を持つデータベースである。
Yggdrasillとのアーキテクチャの違い
EsTerraでは、Yggdrasillとは異なり、ハードディスク上のデータを検索するアーキテクチャを採っている。これによって、システムのメモリサイズに依存することなく、テラバイト級のデータベースを扱うことが可能になった。また、Yggdrasillでは、メモリーとディスクの2元管理を行っていたため、複雑なトランザクション制御の必要があったが、EsTerraでは、データの管理をディスク上で一元化するようにしてトランザクション機構の見通しを良くし機能の改善を行った。例えば、更新時にYggdrasillでは、ドキュメント単位での排他制御が行われていたが、EsTerraでは、ノード単位でロック、更新、アクセス制御を行うことができる。
格納方式 (図※8)
XMLデータを格納するためには、まずリポジトリと呼ばれるXMLデータ用にアロケートされた領域を作成する。リポジトリ中にさらにディレクトリと呼ばれる論理的な格納域を設け、その中にXMLデータを構造化し格納する。リポジトリは一つのファイルとして作成され、ブロックと呼ばれる最小の単位ごとにアロケーションされる。ユーザがリポジトリを作成する際にブロック数、ハッシュビットの数を指定することができる。リポジトリはキャッシュすることができ、キャッシュについてもページ数やキャッシュの単位となるセグメントのサイズなどを規定することができる。
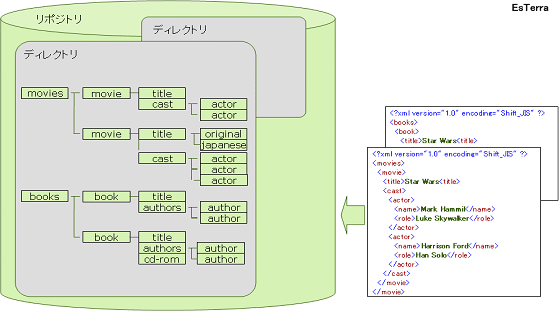
図8
インデックスカスタマイズ
EsTerraでは、デフォルトではフルオートインデックス、つまりすべての構造インデックスを作成する。ただしすべての構造にインデックスを作成するとサイズが大きくなる上、更新パフォーマンスも低下するので、選択的にインデックスを作成する手段も提供している。より高度なインデックスのカスタマイズによるチューニングも可能な設計がなされているが、この場合はベンダーのエンジニアの協力が必要である。
RELAX NG
XMLドキュメントを格納する際のバリデーションに、RELAX NGを用いることもできる。RELAX NGは、XML Schemaと同様にXML向けに設計されたスキーマ言語の一つであり、OASISの標準として勧告されている。RELAX NGは、複雑で仕様の見通し悪いと批判されているXML Schemaの欠点を克服するために、機能は絞り込んだシンプルな言語として設計されたスキーマである。
Java API
リスト9に使用例を示す。APIを多言語に対応させたためか、Javaの言語仕様を生かせてはいない。例外クラスは一つも定義されておらず、各メソッド実行の結果はbooleanで戻ってくる。このため、各メソッドの戻り値でエラーの判定をする必要があり、例外処理が不自然になる。なお、リスト中のサンプルでは、コードの可視性が悪くなるので、エラー判定は行っていない。
リスト9:JavaAPI
1: import jp.co.mediafusion.ClientModule.EsTerraRepository;
2:
3: public class EsTerraQuery {
4:
5: public static void main(String[] args) {
6: try {
7: boolean ret;
8: EsTerraRepository Server = new EsTerraRepository("localhost",8290);
9: ret = Server.Login("admin","admin","C:EsTerraDBrepository");
10: ret = Server.OpenTransaction("");
11: ret = Server.OpenDirectory("dir1");
12: ret = Server.SelectDocument("movies.xml");
13: ret = Server.QueryDocument("/movies/movie[title ='Star Wars']");
14: long count = Server.Count();
15: for ( int ii = 0;ii< count; ii++ ){
16: System.out.println(Server.GetXml(false));
17: ret = Server.Next();
18: }
19: ret = Server.CloseTransaction();
20: ret = Server.Logout();
21: } catch (Exception e){
22: e.printStackTrace();
23: }
24: }
25: }
使用感・コメント
日本で設計から開発まで行われている製品であるという点は大きなメリットである。最初からマルチバイト文字への対応が最初から考えられている点は安心できる。グローバル企業の場合、日本語への対応がどうしても遅れがちな傾向がある。
試用版では、使用期限以外に容量制限が設定されており、10Mバイトを超えるデータベースを作成することができなかった。そのため、性能についてはコメントできない。いずれにしても登場して間がないため、市場での事例がまだ多くないことを勘案して開発を進めるのが良い。ベンダーと密に連携し、基本機能についてもプロトタイピングの段階で十分な検証をしておきたい。
NeoCore XMS
NeoCore XMSは、米国NCホールディングスによって開発された、新興のネイティブXMLデータベースである。国内では三井物産(株)が販売している。試用したバージョンは2.9である。
特徴
USP(米国特許)取得技術である、DPP (Digital Pattern Processing)と呼ばれる独自のインデックス検索技術を用いたネイティブXMLデータベースである
フルオートインデックス (図※9)
NeoCore XMSではXMLデータを読み込むと、インデックスファイルを中心とする複数のファイルに分解されて格納される。データベースは、構造と値インデックスを格納するインデックスファイル、XML構造を復元するためのマップファイル、値を管理する辞書ファイル、重複情報を扱う重複ファイルといった、ファイルから構成される。インデックスはすべての要素について定義され、インデックスの作成を制御するための手段はない。
各ファイルはデータベースの作成時に、領域のサイズを決めるパラメーターを設定して用意される。データの登録によって、用意された領域が消費されてゆくが、全体の大きさは変わらない。データの登録によって格納する領域が一杯になると、領域を拡大するためのコマンドを実行する必要がある。
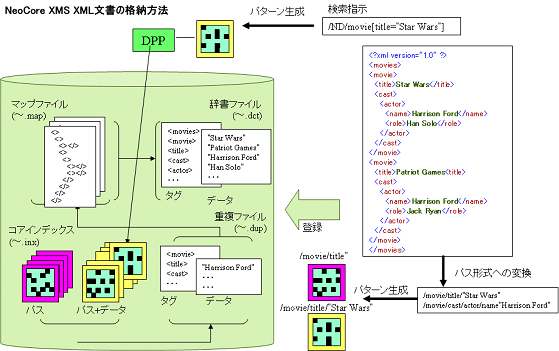
図9
DPP
インデックスの検索のために、DPPと呼ばれる技術が用いられる。DPPはそれ自体はXMLと関係のない、連想メモリーを用いたパターン認識技術のひとつである。与えられたパターンと一致するパターンを高速に取り出すことができる。ベンダーによれば、指定されたパターンを取り出すために要する時間は、平均で1.5メモリーサイクルであり、この値はデータのサイズに依存しないとのことである。つまり、どんなに沢山のパターンがあったとしてもほぼ同じ(極めて短い)時間で取り出すことができるのだ。
DPPの連想メモリーで探索の対象とするパターンは、64ビットの固定長のパターンで、アイコンと呼ばれる。どんな長さのデータもこのアイコンに変換することができる。異なるデータが同一のアイコンに変換される可能性は、18×1018分の1(64ビット)になる。このDPP技術を用いることによって高速検索可能でかつコンパクトなインデックスメカニズムが実現されている。
具体的には、XMLデータの階層構造は、その末端に位置する各データと、そのデータまでの絶対パス(要素の階層構造)を組み合わせることで、「パス+データ」の列として各データを表現するパス形式に変換することができる。このうちのパスの文字列と、パス+データの文字列のそれぞれがDPPのアイコンに変換される。検索式から同様にして生成されるアイコンと、インデックスのアイコンのマッチングによって、インデックス検索が行われる。
Java API
通信にはHTTPを使用してDBへアクセスする。リスト10に、使用例を示す。8行目から10行目の各メソッドのリターン値にはサーバからの応答メッセージが返され、検索時(9行目)には検索結果が返される。データベースには異なる構造を持ったXMLデータを格納することができ、これらは共通のルート要素として
リスト10:JavaAPI
1: import com.neocore.httpclient.SessionManagedNeoConnection;
2: public class NeoCoreQuery {
3:
4: public static void main(String[] args) {
5: try {
6: SessionManagedNeoConnection con = new SessionManagedNeoConnection("localhost", 7700);
7: String sid = con.login("Administrator", "admin");
8: System.out.println(con.startTransaction());
9: System.out.println(con.queryXML("/ND/movies/movie[title ='Star Wars']"));
10: System.out.println(con.commitTransaction());
11: } catch (Exception e ) {
12: e.printStackTrace();
13: }
14: }
15: }
使用感・コメント
インデックスの設計が不要で、ウェルフォームドXMLを高速に検索できるという特性は魅力である。データ投入には苦労したが、一旦投入できてしまえば安定した検索性能を示す。本誌7月号にて検索性能が1GB規模までリニアであることを紹介したが、さらにこの特性は少なくとも50GBまで変わらないことがわかっている。運用中に格納されているXMLの構造と異なる構造をもつXMLが登録されても自動的にインデックスが作成されるので、利用者は、どの項目にインデックスを設定すれがよいかは考える必要はなく、インデックスが使用されるような検索を考えるだけで済む。
強力なエンジン単体の提供という印象であり、開発ツールなどの整備がまだ十分ではない。データ投入についても、100MBを超えたころから設定が難しくなった。データ投入の際に、ストレージを構成する複数のファイルのどれかが一杯になるため、試行錯誤をしながらファイルサイズを決めてゆく必要がある。データの構造によってどのファイルがあふれるのかが予測できないため、適切な設定を行うのが難しくなるのだ。次のバージョンでは自動拡張機能によってこの問題は解消されるとのことなので期待したい。
eXist
eXistはPure Javaで作られたオープンソースのネイティブXMLデータベースである。試用したバージョンは0.92である
特徴
フルオートインデックス機能を持つウェルフォームドXML対応のオープンソースのデータベースである。
フルオートインデックス
eXistでは階層構造のコレクションを作成して、コレクション内に複数の異なる構造を持つウェルフォームドXMLデータを格納する。データを投入するとデフォルトで自動的に値インデックスと構造インデックスを作成する。インデックスはコレクションごとに行なわれるため、1つのコレクションが大きくなりすぎたり、XMLの構造が異なるものを同じコレクションに含めたりすると性能が劣化する性質をもつ。
大量のデータを投入するにはコレクションを分けたり、VMの起動パラメーターやデータベースのプロパティを調整したりする必要がある。チューニングするにはフルオートインデックスから除外する要素を指定する。管理コンソールでインデックスのバッファの使用状況やヒット率を参照して、値の調整の参考にすることができる。
3種類の実行時アーキテクチャ
eXistはクライアント/サーバ、APデプロイ、スタンドアローンの3種類の実行時アーキテクチャで動作させることができる。デフォルトの動作であるクライアント/サーバモデルは、サーバを起動して、クライアントからAPIを通してアクセスする方法である。サーバは同梱されているJettyというサーブレットエンジンの上で動作する。APデプロイモデルは、warファイルをデプロイすることでアプリケーションサーバ上の1つのアプリケーションとして動作させる方法である。アプリケーションサーバとしてApache Cocoon上で動作させることもできる。スタンドアローンモデルは、クライアントアプリケーションの中に埋め込んで同じVM上で動作させる方法である。
XPathの拡張
検索方式としてXPathに対応しているが、インデックスを有効に利用できる操作や関数を追加して高速に検索ができるようにしている。拡張された操作ではコレクションをまたがる検索や正規表現にも対応しており、XPath準拠とはいうものの、拡張されたものを使った場合にのみ高い性能が出るので使い方には注意が必要である。
Java API
eXistにはXML:DB APIとXML-RPCおよびSOAP APIの3種類のAPIが用意されており、このうちJava APIはXML:DB APIをベースにしたものである。XML:DB APIに認証認可機能、ネストしたクエリー、結果のソートなどの機能が追加されている。リスト11に検索する例を示す。
リスト11:JavaAPI
1:import org.xmldb.api.base.*;
2:import org.xmldb.api.modules.*;
3:import org.xmldb.api.*;
4:
5: public class eXistQuery {
6:
7: public static void main(String[] args) {
8: try {
9: String driver = "exist.xmldb.DatabaseImpl";
10: Class cl = Class.forName(driver);
11: Database database = (Database)cl.newInstance();
12: DatabaseManager.registerDatabase(database);
13:
14: Collection col =
15: DatabaseManager.getCollection("xmldb:exist://localhost:8080/exist/xmlrpc/db/data");
16: XPathQueryService service =
17: (XPathQueryService) col.getService("XPathQueryService", "1.0");
18: service.setProperty("pretty", "true");
19: service.setProperty( "encoding", "UTF-8" );
20:
21: ResourceSet rs = service.query("/movies/movie[title='Star Wars']");
22: ResourceIterator i = rs.getIterator();
23: while(i.hasMoreResources()) {
24: Resource r = i.nextResource();
25: System.out.println((String)r.getContent());
26: }
27: rs.close();
28: col.close();
29: } catch(Exception e) {
30: e.printStackTrace() ;
31: }
32: }
33: }
使用感・コメント
インストールは簡単で、構成もシンプルで分かりやすい。WindowsのメニューやGUIツール、Webブラウザでの管理コンソールなどが用意され、操作性も悪くないので初心者にも使いやすい。XMLデータベースがどんなものか、触ってみたいという場合にはお勧めできる。Apacheなど他のオープンソースのプロジェクトのライブラリやサーバとの相性がよい。また、XML-RPC、XML:DB API、WebDAVなどの標準も積極的に取り入れている点も評価できる。
オープンソースということで日本語の対応が気になるところだが、Shift_JISのXMLの登録には問題がなかった。XPathにおいては、値に日本語が含まれる場合は問題ないが、ノード名に日本語が含まれる場合は例外が発生する。現在のバージョンではノード名は英語名で定義したほうがよい。現在、まだベータバージョンであり、オープンソースのため十分なサポートが期待できないという点には注意が必要である。また、大規模なデータベースを構築する際には様々なチューニングが必要になりそうだ。普通の企業や機関が実際に利用する信頼性の高いシステムの構築には、商用のデータベースの利用をお勧めしたい。
チューニングのヒント
ネイティブXMLデータベースの検索性能を向上させる際に基本となる手法をいくつか紹介する
(1)適切なXMLドキュメント単位
製品毎に適切なXMLドキュメントの単位は異なる。これまで例として用いてきた
(2)インデックスの使用
インデックスを使用するにあたって注意が必要なことは、インデックスが効く検索式を記述しなければ意味がないという点である。例えば以下のような階層構造の位置を特定しないXPath式の場合、構造インデックスは効かない。指定位置以下のノードを走査することになり構造インデックスが使用されないのだ。
また、必ずしも、検索項目に対し全てインデックスを設定すれば速くなるとは限らない。各製品の検索式を解釈実行するクエリプロセッサの最適化ルールに依存する。したがって、導入にあたっては、実際に行われそうな検索パターン(and条件やor条件、大小比較検索)を複数用意し、インデックスの設定を変えてみて、評価をしておくことが望ましい。検索にインデックスが使用されるかどうかを確認できる製品もあるので、それを利用しながらインデックスの設計を行うとよいだろう。
(3)結果セットのサイズを制御する
検索結果がDOMオブジェクトになるようなAPIを使用した場合、検索結果のサイズを小さくすることは効果が大きい。サーバはクライアントへ検索結果を、DOMオブジェクト(バイナリデータ)として送るわけではなく、テキストデータで送信し、クライアントで受信したテキストデータをDOMオブジェクトへパースするからだ。
例えば、特定の俳優の出演映画を検索したい場合、/movies/movie[cast/actor/name="Harrison Ford"]というXPath式を使うと映画タイトルだけでなく、映画情報のすべてを返す。代わりに/movies/movie[cast/actor/name="Harrison Ford"]/titleとすればtitle要素だけを返すのでパース対象がずっと小さくなる。また、結果セットを小さくできるようなXMLのドキュメント構造にするという検討も必要だ。例えば、一覧表示に使用する構造と詳細情報表示に使用する構造を持つようにするなどである。
パフォーマンスの目安
チューニングの目標となるパフォーマンスはどのように考えればよいのだろうか。パフォーマンスはデータの構造や検索方法に大きく依存するので客観的な目標を与えることは難しい。本誌8月号で、NeoCoreのパフォーマンス測定に、XMarkというベンチマークサイトのデータを利用したが、あくまでそこで想定したデータ構造での結果に過ぎない。XQueryもXPathも書き方次第でパフォーマンスは大きく変わる。
精密な議論はともかくおよその感覚が知りたいという方のために、以下におおまかな目安を示しておく。検索によってXMLデータを取得する単位としては、小さいものでも本稿で使った程度のXMLデータになり、500バイト程度のテキストデータとなる。ごく普通のPC環境で、この程度のデータ1件の検索を、数10ミリ秒で行えるというあたりが、現在のネイティブXMLデータベースの目標性能と考えればよいだろう。もちろんマシンスペック次第ではさらに性能を高めることも可能である。
おわりに
本稿では、ネイティブXMLデータベースの普及を妨げる最大の要因として、利用ノウハウの流通がなされていないことを指摘し、その解決の一助となる情報の提供を目指した。
すべてのベンダーが該当するわけではもちろんないが、一部のベンダーの情報提供の仕方は、こうしたノウハウの流通を妨げていることを指摘しておきたい。一見して日本人のエンジニアがチェックしていないとわかる、直訳で意味不明のマニュアルは、現場に多大な迷惑をかけていることを認識されたい。デモは記述通りに操作すれば動く状態にしてから提供して欲しいものだ。試用版に容量制限を加えるのもやめて頂きたい。小さなサイズのXMLデータしか投入することができなければベンチマークをしても意味がない。
今、再びネイティブXMLデータベースに注目が集まり、XMLを用いた新しいソリューションが生まれる気運が高まっている。前回の轍を踏まないよう、ベンダーとユーザが共に協力し、利用のためのノウハウを囲い込むことなく積極的に流通させることで、この分野全体の発展・拡大を進めてゆけることを期待したい。
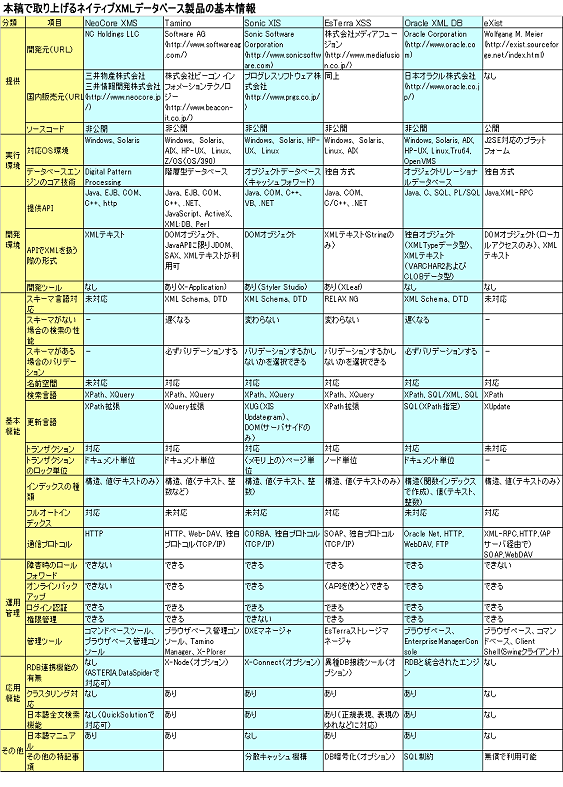
表:本稿で取り上げたネイティブXMLデータベース製品の基本情報