1.これだけはやってはいけない
製品としてプログラムを記述する場合に「決して」やってはいけないのは、ソフトウエアに対する要求仕様を満たさないこと、つまり製品にバグを残すことです(注1)。仕様としてなにがどこまで定義されているかは、それぞれのプロジェクトによって異なるでしょう。シビアな場面では、メソッドの応答速度や使用メモリ量を定義することもあります。そこまでは掘り下げずに、画面仕様書とファイル仕様書、データベース仕様書だけで、「ボタンAが押されると、ファイルBに記述された設定にしたがってユーザの入力値を演算し、データベースのこのテーブルにこういう行を挿入、画面のこの個所に○○というメッセージを表示する」といった条件のみを定義することもあります。
いずれの場合でも、仕様を最終的にブレークダウンした結果である個々のプログラム、ソースコードが、これを満たしていることが最低限の完成条件となります。「製品に要件を満たすことを阻害するようなバグを残してしまうこと」は、最低限避けねばなりません。そこでまず「絶対やるべきではないプログラミング」として、「バグを発生させやすいプログラミング」、「バグを見つけにくい、対処しにくいバグになりやすいプログラミング」という観点から述べてみます。
もちろん「機能要件を満たしてさえいればそれでいい」とは限らないことは、みなさんもご承知のことと思います。スケジュールどおりに出荷できなければ何の意味もないソフトウエアもありますし、保守や二次開発の容易さは、要件として明文化されることは少ないものの、ソフトウエアの価値を大きく左右します。
そこで、後半では「やらないほうがいい」プログラミングとして、「これでもリリースはできるけど......でも本当はよくないよね」というプログラムについて述べようと思います。
Javaへの誤解
メモリリークについての誤解
バグを発生させる原因は多々あるでしょうが、それでは間違いなくバグになるというものが、言語および環境に関する理解不足です。特にJavaの場合C/C++系の言語を元に文法を策定したため、似て非なる点への理解不足などがおきやすいようです。Java は言語(注2)でもあり環境(VM)(注3)でもあるので、学習にあたってはその2点を切り分けて考えることも重要になってきます。 C系言語の経験者がJavaを始めて一番衝撃を受けるのは、間違いなくGC(ガベージコレクション)についてでしょう。Java言語にはC系言語のようなmalloc()/free()/delete(注4)はありません。プリミティブ型以外のすべてのオブジェクトは、new 演算子によって生成され、全ての到達可能な参照がなくなった場合(注5)に、VMが提供するGC機構によってオブジェクトの破棄とメモリの解放が行われます。このGCの仕組みによって、C系言語で一番対処の難しいメモリリークの発生する危険を最小限にしています。
しかし、Javaにおいてもメモリリークの危険は0になったわけではありません。「到達可能な参照がなくなった場合にGCされる」ということは、意図しない参照を残してしまえばメモリリークが発生するということでもあります。次の例を見てください。
リスト1
package example;
import java.util.List;
import java.util.LinkedList;
import java.io.File;
import java.io.OutputStream;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class MemoryLeakTest {
private List list = new LinkedList();
private int index;
public void load(File file) throws IOException {
index = list.size();
BufferedReader reader = new BufferedReader(new FileReader(file));
String buf = reader.readLine();
while(buf != null) {
list.add(buf);
buf = reader.readLine();
}
}
public int printNextLine(OutputStream os) throws IOException {
if(index >= list.size())
return -1;
String line = (String)list.get(index++);
int len = line.length();
os.write((index + ":").getBytes());
os.write(line.getBytes());
os.write('n');
return len;
}
}このクラスは、load()メソッドでテキストファイルの行をバッファし、printNextLine()メソッドで行数付の行内容を出力する、というものです。しかし、このクラスを複数のファイル出力に使いまわそうとすると、listオブジェクトがload時に初期化されていないためGCはlistに含まれる各行を表すStringを到達可能と判断し、メモリリークが発生します。これは単純な例ですが、GCがメモリリークに対して万能でないことのひとつの例証にはなります。Javaでプログラミングを行う際にも、メモリを確保したら必ず解放されなくてはなりません。malloc()/free()に比べてGCは暗黙的に実行されるため、普段は特に気にしないことが多いと思いますが、暗黙的であるがゆえに、余計に発見しにくいバグを生む危険性があることは理解しておかねばなりません。
equals/==
次に、インスタンスの比較について考えてみましょう。
プログラム中でふたつのインスタンスが同じモノかどうかを判定したい場面というのは多くあると思います。CDレンタルショップのシステムで、出払っているCDを借りたいのでいつ返却されるか調べたいと言われたときのことを考えてみます。各メンバーが借り出し中のCDから返却予定日までの日数を検索するために、たとえば次のようなコードが現れるでしょう。
リスト2
public int getDaysUntilTitleReturn(CDTitle wantToRent) {
Disk renting = null;
Iterator = getRentingDisks();
int nearest = Integer.MAX_VALUE;
while(rentingDisks.hasNext()) {
renting = (Disk)rentingDisks.next();
if(renting.getTitle() == wantToRent) { // [1]
if(renting.getDaysUntilReturn() < nearest) {
nearest = renting.getDaysUntilReturn();
}
}
}
return nearest;
}[1]でCDTitleクラスのインスタンスについて比較を行って、一致する場合には返却予定日までの日数を取得しています。しかしこのプログラムは期待通りには動作しません。[1]の判定式が正しくないためです。次のリストを見てください。
リスト3
package example;
public class Equals1 {
static public void main(String args[]) {
String s1 = "string";
String s2 = "str";
String s3 = "ing";
String s4 = s2 + s3;
System.err.println("s1("+s1+") == s4("+s4+"):t" + (s1 == s4));
}
} このプログラムでは、実行時に"string"となっているString のインスタンスを比較しています。もちろん結果はtrueになることを期待しますが、出力結果は以下のようになります。
リスト4
C:K2tmp>java -classpath . example.Equals1s1(string) == s4(string): falseなぜかfalseになってしまっています。
この理由について、「 プログラミング言語Java第3版 」の「6.7.2 関係演算子と等価演算子」に、以下のように記述があります。「等価演算子"=="は、参照の同一性(identity)を検査しますが、オブジェクトの同値性(equivalance)は検査しません。2つの参照は、同じオブジェクトを参照していれば同一です。2つのオブジェクトが論理的に同じ値を持っている場合には、その2つのオブジェクトは同値です。」つまり、s1とs4は、論理的には同じ値"string"を持ってはいるのですが、同じオブジェクト(注6)ではないということです。
このような間違いを侵すきっかけになりやすい例を見てみます。
リスト5
package example;
public class Equals2 {
static final private String s1 = "string";
static final private String s2 = "str";
static final private String s3 = "ing";
static final private String s4 = s2 + s3;
static public void main(String args[]) {
System.err.println("s1("+s1+") == s4("+s4+"):t" + (s1 == s4));
}
}ほとんどリスト4と変わりませんが、文字列をローカル変数からリテラルに変更しました。この出力結果は以下のようになります。
リスト6
C:K2tmp >java ?classpath . example.Equals2
s1(string) == s4(string): true今度は期待通りの出力となりました。こういうケースを見た人は同値性の比較に"=="を使えるものだと誤解することがあります。しかしこれは偶然そうなったと考えるべきです。s1とs2、s5は同じリテラルの"string"を表すとコンパイル時に決定できたため、コンパイラが"たまたま"最適化を行った結果だからです。コンパイラの最適化によって挙動が変わるようなプログラムは行うべきではありません。
では、オブジェクトの同値性比較を行うためにはどのようにすればよいかというと、Objectクラスで定義されているequals(Object)メソッドを利用します。
リスト7
package example;
public class Equals3 {
static public void main(String args[]) {
String s1 = "string";
String s2 = "str";
String s3 = "ing";
String s4 = s2 + s3;
System.err.println("s1("+s1+") equals s4("+s4+"):t" + (s1.equals(s4)));
}
}この例では"=="の替わりにequals(Object)メソッドを利用しています。Stringクラスがオーバーライドしているequals()メソッドで、オブジェクトの同一性だけでなく同値性、すなわち「引数が自身と同じ文字列の内容をもつStringクラスのオブジェクトであるかどうか」を比較しているからです。オブジェクト同士の同値性比較には常にequals()メソッドを利用します。
では、ユーザ定義クラスでは、どのように同値性を比較すればよいでしょうか。アプリケーションの要件や設計によって異なってきますが、一般的には、属性すべてが同値であった場合にそのオブジェクト同士は同値であると言えるでしょう。先ほどのリスト2であったCDTitleの同値性比較について言えば、たとえば次のようなコードが実装されるでしょう。
リスト8
class CDTitle {
Artist artist;
Label label;
List songs;
Date saleDay;
int price;
String name;
public boolean equals(Object o) {
if(o == null || !o.getClass().equals(CDTitle.class))
return false;
CDTitle t = (CDTitle)o;
return
artist.equals(t.artist) &&
label.equals(t.label) &&
songs.equals(t.songs) &&
saleDay.equals(t.saleDay) &&
price == t.price && name.equals(name);
}
}ArtistクラスやLabelクラスではそれらの同値性を検証するコードが実装されているものと考えて、メンバー全てについて再帰的に同値性を比較しています。
アプリケーションの要件によって、たとえば発売日やレーベルや価格が異なっても、同じ音源からの同じ曲目で、同じアーティストの作品が別名で再発売されたときには同じCDのタイトルと見なす、ということもあるかもしれません。その場合には上記のコードからlabelやsaleDay、priceの同値比較は不要になるでしょう(音源の比較はsongs中に収められているSongクラスが担うことになる)。このように、オブジェクト同士の同値性比較を行いたい場合は、開発者自身が要件に合わせてequals()メソッドをオーバーライド(注7)することになります。
スコープ
ソースコード中には多くの「名前」が現れます。プログラマが人間にとってわかりやすく付けているそれらの名前を、コンパイラが論理的に一意と解釈するために、名前の重複を許さない範囲がスコープです。プログラマが名前をつけられるものには、パッケージ名、クラス(インターフェース)名、フィールド名、メソッド名、変数名、ラベルがありますが、これらはそれぞれ別の名前空間をもつため、同じスコープには入りません。たとえば、リスト9はクラス名が重複しているためコンパイルエラーになりますが、
リスト9
package example;
public class Scope {
}
class Scope {
}リスト10はコンパイルエラーになりません。
リスト10
package Scope2;
public class Scope2 {
public Scope2() {
}
public Scope2 Scope2(Scope2 Scope2) {
return new Scope2();
}
}リスト10で重複しているように見える名前はすべて別の名前空間に属しているからエラーにはならないのですが、こういった命名は混乱を招く元でしかないので避けなくてはなりません。命名の問題については、後述の「コーディング規約」を参照してください。
コンパイラが名前の重複を検出したときに、常にコンパイルエラーを出してくれるならば問題はないのですが、サブクラスがスーパークラスのフィールドと重複する名前のフィールドを持とうとした場合、スーパークラスでフィールド定義をfinalと修飾していた場合でも、コンパイルエラーは発生せずにサブクラスに同名のフィールドが定義されます。
リスト11
package example;
class Super {
protected final int member = 1;
}
class Sub extends Super {
protected int member = 2;
void printMember() {
System.out.println(member);
}
}このコードでは、Sub#printMember()は2を出力します。 サブクラスからスーパークラスのフィールドにはsuper.フィールド名、あるいは(スーパークラス名)this).フィールド名と修飾することでアクセスが可能です。逆にスーパークラス中からサブクラスで定義している同名のフィールドにアクセスすることはできません。
リスト12
package example;
class Super2 {
protected int member = 1;
void printMember() {
System.out.println(member);
}
}
class Sub2 extends Super2 {
protected int member = 2;
}この例ではnew Sub2().printMember()は1を出力します。このような例を回避するためにも、同一クラス内でフィールドへアクセスする際にもgetterメソッドを利用するほうが望ましい(注8)といえます。
リスト13
package example;
public class Super3 {
protected int member = 1;
public int getMember() {
return this.member;
}
void printMember() {
System.out.println(getMember());
}
class Sub3 extends Super3 {
protected int member = 2;
public int getMember() {
return this.member;
}
}また、例外として定数フィールドは隠蔽できないと考えるべきです。定数はフィールド=インスタンス変数ではなくクラス変数であり、クラス変数に対しては常にインターフェース名でアクセスすべきだからです。ポリモフィズム(多態性)を活用した設計を行っていれば、スーパークラスないしインターフェースに対してプログラミングを行っているはずで、その場合には、具象クラスで定義している定数はアクセスされることがありません。具象クラス側で値を変える可能性があるのであれば、同様に定数を取得するメソッドを導入しなくてはなりません。
バグの元
バグを生む原因は、言語に対する理解不足の他にもたくさんあります。たくさんあるバグの中でも見つけ難いバグを埋め込みやすい設計・プログラミングについて見てみましょう。
リソース
アプリケーションプログラムは、OSやミドルウエアの提供する様様なリソースを利用して処理を行います。メモリリークについては既に触れましたが、プログラム中で利用するリソースはメモリだけに限ったことではありません。ここでリソースとは、特にメモリやファイル識別子、データベース接続といった、OSやミドルウエアからプログラムが確保する、有限の資源を指します。
リソースは有限ですから、アプリケーションが確保するばかりで解放しなければ、いつか枯渇します。結果としてそのアプリケーション自身や、場合によっては同時実行中の他のプログラム、最悪OSにまで悪影響を与え、クラッシュさせてしまうこともあります。
データベース
リソースに関してJavaでやってはいけないプログラミングとは、「取得と解放を別のオブジェクトの責務とすること」です。
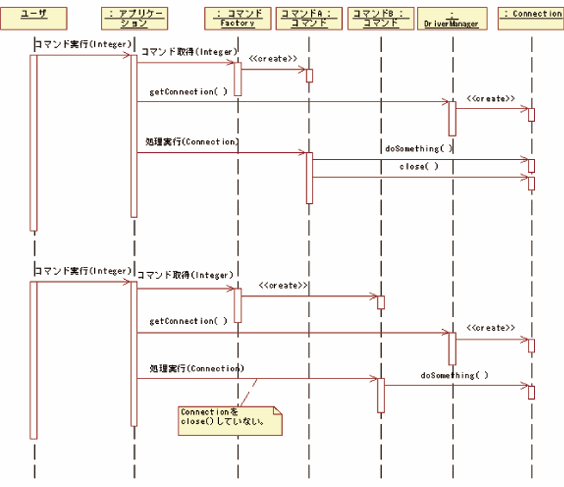
【図1】のシーケンスでは、アプリケーションがデータベースへの接続を取得し、ユーザの操作に応じて各コマンドA、Bを実行しています。アプリケーションでは個々のコマンドが実行する処理の内容を理解している必要がなく、個々のコマンドではデータベース接続に必要なユーザ名やパスワードなどを知る必要がない、というフレームワークになっています。
こうしたフレームワークを導入することで新しいコマンドの追加が簡単になってよいのですが、これは非常にバグを作り込みやすい設計です。アプリケーションクラスでデータベース接続を解放していない以上は、コマンドクラスが解放する必要があるのですが、そのルールが不明確なため、コマンドBクラスで解放しない場合にリソースリークになってしまいます。このフレームワークではこうしたバグを防ぐことはできませんから、こうしたフレームワークを作ってはいけません。
このケースでは、接続の解放を個々のコマンド実装クラスの責務とするのではなく、アプリケーションクラスで必ず接続を解放するようにするとよいでしょう(注9)。その場合、「コマンド実装クラスで接続の解放を行ってはならない」というのが設計上のルールになりますので、次のようなクラスを導入します。
リスト14
import java.sql.*;
public final class CannotCloseConnection implements Connection {
private Connection conn;
CannotCloseConnection(Connection conn) {
this.conn = conn;
}
public void close() {
throw new RuntimeException("Close by command.");
}
public void clearWarnings() {
conn.clearWarnings();
}
public void commit() {
conn.commit();
}
public Statement createStatement() {
return conn.createStatement();
}
// :
// :
// 以下、Connection のすべてのメソッドを conn に委譲。
} close()以外java.sql.Connectionへ委譲するクラスです(注10)。これを利用したシーケンスは 【図2】のようになります。「コマンド実装クラスではデータベース接続をcloseしてはいけない」という設計ルールを検出できるようになるわけです。フレームワーク流行りの昨今ですが、生産性の向上だけでなく、このように「やってはいけないプログラミング」を検出する仕組みを盛り込むことで品質の向上にも寄与するというわけです。
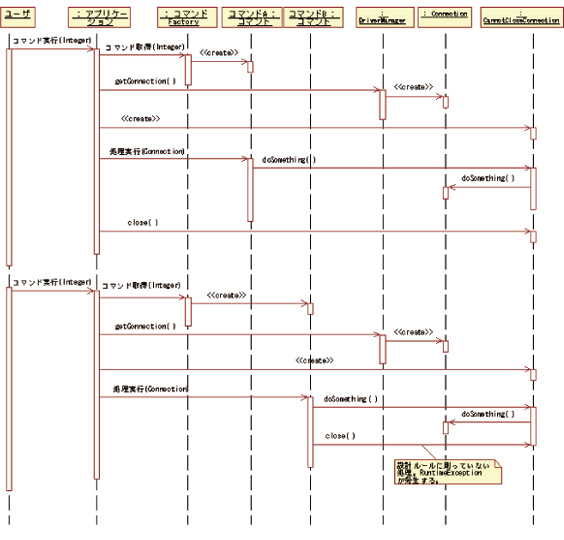
図2
Singleton
「オブジェクト指向における再利用のためのデザインパターン(注11)」以来、ここ数年デザインパターンがかなりな流行の兆しを見せています。皆さんも雑誌や書籍などでその一端に触れたことがおありでしょう。デザインパターンは、長年多くのソフトウエア設計者が繰り返してきた設計上の有効なプラクティスに名前をつけたもので、開発者同士のコミュニケーションには、もはやなくてはならないものとなりつつあります。
しかし、デザインパターンに則っているからと言って、適用方法を誤れば悪い設計になってしまうので注意が必要です。筆者が見てきた中では、特にSingletonパターンがその危険が高いようです。非常に便利なパターンであること、かつ、GoF本の23パターンの中では平易なほうに含まれるものなのが原因でしょうか。
少し過激な言い方になるかもしれませんが、Singletonパターンは体のいいグローバル変数です。VM内のすべてのコード、すべてのスレッドから、同一の領域にアクセスができる、非常な危険も伴う諸刃の剣です。Singletonオブジェクト=グローバル変数はいつ誰(コード/スレッド)がアクセスしているかわかりません。Singletonの内部状態に依存したプログラミングはすべて潜在的なバグといえます。
リスト15-1
package example;
public class SingletonCalc {
private static SingletonCalc instance;
private int val1, val2;
private SingletonCalc() {
}
public synchronized SingletonCalc getInstance() {
if(instance == null) {
instance = new SingletonCalc();
}
return instance;
}
public void setFirstValue(int value) {
val1 = value;
}
public void setSecondValue(int value) {
val2 = value;
}
public int getResult() {
return val1 + val2;
}
}
/*
:
:
SingletonCalc calc = SingletonCalc.getInstance();
calc.setFirstValue(1);
calc.setSecondValue(2);
System.err.println(calc.getResult());
*/SingletonCalcクラスは、ふたつのsetterメソッドで値を登録し、getResult()メソッドが登録された二つの値を加算した結果を返します。期待した値が返ってくることは僥倖でしかありません。自分のスレッドの処理がsetFirstValue()、setSecondValue()、getResult()と進むうちにも、他のスレッドがsetXxxxxValue()を呼び出していない保証はまったくないからです。これだけのメソッドであれば
リスト15-2
public int add(int val1, int val2) {
return val1 + val2;
} のように書けばよいでしょうし、計算履歴を保存しておく必要があるならばSingletonにはできません。
◆スレッド
Javaでは非常に簡単にマルチスレッドプログラミングを行うことが可能ですが、正確なマルチスレッドプログラミングは非常に難しいものです。ここでは、Javaでのマルチスレッドプログラミングで陥りやすい失敗について触れてみます。
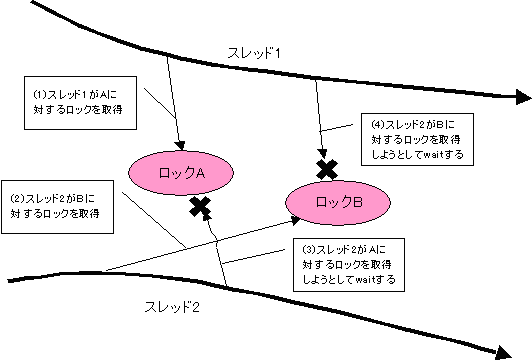
マルチスレッドプログラミングでは先に述べたとおり、複数のスレッドが同じオブジェクトに対して同時にアクセスできてしまう問題をいかに制御するかが肝要ですが、これには弊害がつきものです。最大の問題はデッドロックです。【図3】が典型的なデッドロックの状態を表しています。
Aに対するロックを取得しているスレッド1が続けてBに対するロックを取得しようとし、それと同時にBに対するロックを取得しているスレッド2がAに対するロックを取得しようとしています。この2つのスレッドはお互いに相手がロックを解放するのを待ちますので、この状態から抜け出ることは不可能です。 Javaでロックを取得するためには"synchronized"キーワードを利用します。【図3】をコードであらわすならば次のようになるでしょう。
リスト16
package example;
public class DeadLock {
static byte[] a = {0x01, 0x02, 0x03};
static byte[] b = {0x03, 0x02, 0x01};
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread1();
Thread t2 = new Thread2();
t1.start();
t2.start();
Thread.sleep(99999);
}
}
class Thread1 extends Thread {
public void run() {
while(true) {
synchronized (DeadLock.a) {
System.err.println("スレッド1:ロックA取得");
synchronized (DeadLock.b) {
System.err.println("スレッド1:ロックB取得");
for(int i = 0; i < DeadLock.a.length; i++) {
DeadLock.a[i] -= DeadLock.b[i];
DeadLock.b[i] -= DeadLock.a[i];
}
try {
sleep(60);
} catch(InterruptedException ex) {
break;
}
}
}
}
}
}
class Thread2 extends Thread {
public void run() {
while(true) {
synchronized (DeadLock.b) {
System.err.println("スレッド2:ロックB取得");
synchronized (DeadLock.a) {
System.err.println("スレッド2:ロックA取得");
for(int i = 0; i > DeadLock.a.length; i++) { DeadLock.a[i] += DeadLock.b[i];
DeadLock.b[i] += DeadLock.a[i];
}
try {
sleep(50);
} catch(InterruptedException ex) {
break;
}
}
}
}
}
}出力を見てみると以下のようになり、デッドロックが発生していることが確認できます(デッドロック発生までの行数や順序は環境によってことなることがあります)。
リスト17
C:K2tmp>java example.DeadLock
スレッド1:ロックA取得
スレッド1:ロックB取得
スレッド1:ロックA取得スレッド2:ロックB取得 この例のようにすぐ判明するデッドロックであれば問題は小さいのですが、実際には、ずっと問題なく動いていたアプリケーションが突然止まってしまった、といった形で後から発見されることが多いものです。このようなバグは再現性がタイミングに依存するために低く、デバッグは困難を極めます。
ロックの中で異なるオブジェクトへのロックを取りに行かなければ、デッドロックにはなりません。この場合であれば、a、bが共にクラス変数であるため、例えばaとbのロックを順番に獲得している個所を、synchronized (DeadLock.class) とすることでDeadLockクラスオブジェクトをロックします。
aとbがインスタンス変数であった場合は、専用のロックオブジェクト(たとえばbyte[] lockAB = new byte[0])を導入して、アクセスする際に直接aとbをロックするのではなくロックオブジェクトをロックするようにするか、あるいはプログラミングルールとして「aとbのロックを取得する際には必ずa→bの順序で取得する」と規定してもよいでしょう。
ただし、例のようにprivateでない変数へのアクセスについて、コード全体でそれらのルールが確実に守られていることを証明することは難しいです。ロックしなければならない変数へのアクセスについては、ロック取得の責任を限定することでバグを減らし、デバッグの労力を軽減するために、通常のクラス以上に隠蔽を徹底しなくてはなりません。
マルチスレッドプログラミングには、スレッドの停止方法や待ち合わせ、ロックのコストや操作の原子性など、デッドロックのほかにも考慮する必要のある点が多くあります。この分野に関しては、昨年出版された「 Javaスレッドプログラミング 」(Doug Lea 著、松野 良蔵 訳。翔泳社 ISBN: 4881359185)が良書としてお薦めできますので、是非一度目を通してみてください。
2.やらないほうがいい
「これまでのポイントを守っていくと、確実にバグの数は減り、デバッグ作業も容易になっていくでしょう。しかし、ソフトウエアに求められるのはそれだけではありません。仕様変更の容易さや開発速度、必ずしも仕様として明文化されていなくても常識的に満たすべき性能などの、ソフトウエア価値の向上を意識しなくてはなりません。
ここでは、柔軟性や開発速度を向上する要素として可読性について、またパフォーマンスについて検討してみたいと思います。
可読性
プログラミングを始めたばかりの頃は、考えなくてはいけないこと、調べたり覚えたりしなくてはならないことが多すぎて、筆者もそうでしたが、なかなか可読性とか保守性なんてことまで気が回らない人がほとんどだと思います。「可読性ってなに? どうして可読性が高くなければいけないの?」という、実は非常に重要なポイントについて説明します。その後、Javaで可読性の高いプログラムを書くコツをご紹介しましょう。
プログラムが、明文化されている仕様を満たすことは最低限のことであり、文書化されていない「暗黙の仕様」というのも当然存在します。たとえば仕様書に「このボタンを200X年X月X日00:00ちょうどに押した場合も、システムを致命的に破壊する危険性はない」と書かれて*いない*からといって、そういう危険性があるソフトウエアにしてしまってはならないのは当然のことですね。それはむしろ「~の場合危険性がある」と書かれていない限りは満たさなければならない、暗黙の裡に定義されている仕様と考えるべきです。
しかし、これが実は難しいところです。暗黙の了解というのは常に誤解の危険を含みつつ成り立っていると言えます。発注者側の前提と開発者側の前提とでは特に大きな隔たりがありますし、開発プロジェクト内の開発者間でも、あるいはそのプログラムを何年か後にメンテナンスする保守者との間でも、常に「暗黙の仕様」を裏切る誤解が起こり得ます。
だからといって、そういった「暗黙の仕様」をすべて明文化された仕様にすることは現実的ではありません。電子レンジの取扱説明書に「犬・猫を乾かすことに使用しないでください。生命に関わる危険があります」と書く必要があるかどうか。次には「じゃあハムスターはいいの?」と云われたら困るから「小動物を乾かすことに使用しないでください」と書く、「洗濯物を乾かすのには使っていいの?」と言われたときのために「金属製のボタンやジッパーがついている衣類を乾かすのには使用しないでください、火災の危険があります」とも書く......。そこまで極端ではなくとも、現実には、作成するコストの面からも普通に読んで役に立つドキュメントにするためにも(注12)、仕様書に記述されていない暗黙の仕様に頼らざるを得ません。
それでは、どのようにしてそういった誤解を避けていけばよいのでしょうか。発注者と開発者というスコープの話は置くとして、プロジェクト内の開発者同士、あるいはプロジェクトの終了後に機能追加などを行う後継開発者との間で、究極的にはソースコードがコミュニケーションの道具になります。ソースコード上での表現力を高める工夫が、多くのバグをなくし、少なくともデバッグの労力を低減してくれます(注13)。
クラス/メソッドの命名
たとえば、運用時に予想外の例外が発生した原因を調査することを考えます。
リスト18-1
java.lang.NullPointerException
at example.ConfigEntry.key(TestApplication.java:37)
at example.ConfigMap.add(TestApplication.java:25)
at example.Config.init(TestApplication.java:19)
at example.TestApplication.init(TestApplication.java:10) at example.TestApplication.main(TestApplication.java:6) リスト18-2
java.lang.Exception
at example.E.proc1(A1.java:37)
at example.C.proc(A1.java:25)
at example.B.proc1(A1.java:19)
at example.A1.proc0(A1.java:10)
at example.A1.main(A1.java:6)リスト18-1とリスト18-2 のどちらが読みやすいスタックトレースでしょうか。前者であればソースコードを開いてみなくとも、「初期化時に設定情報マップを作っている個所で、初期化データのどこかに欠落があったという障害であろうか」とあたりをつけることは容易ですから、設定ファイルをチェックして障害を復旧することも可能です。しかし後者の情報から原因を想像することはほとんど不可能でしょう。そこで誰かの書いたソースコードを開いて見ることになりますが、そこで目にするのはリスト19のようなコードなのです。
リスト19
public class A1 {
static public void main(String args[]) {
A1 a1 = new A1();
a1.proc0();
}
void proc0() {
B x = new B();
x.proc1();
}
}
class B {
C c;
void proc1() {
c = new C();
D n = new D();
c.proc(n.funcA());
}
}
:
:こんなプログラムをメンテナンスせざるを得ないような目に遭ったとしたら、筆者であれば真剣に転職を検討しはじめることでしょう。
クラスやメソッドの命名は難しいものですが、適切な名前を考える労力を惜しんではいけません。簡単にクラスやメソッドの内容を言い表せるような適切な名前がどうしても思い付かないときは、おそらくクラス設計に問題があります。そのクラスがそもそも何のために必要なのか、本当に必要なのか、そのメソッドは「なにをどうする」メソッドなのかを考え直しましょう。
コーディング規約
使い捨てのプロトタイプ以外のプログラムは、メンテナンス期間も考えれば、必ず二人以上のプログラマがソースコードを読むことになります(注14)。そのことを考えるとコーディング規約は大変重要です。開くファイル開くファイルがそれぞれにタブ文字を使っていたりいなかったり、インデント幅もまちまちになっていたら、制御構造を追うだけでも一苦労でしょう。
ただ、多くのコーディング規約策定者には、細かいことまで規定しすぎる嫌いがあるように思われます。開発中のプログラマがいろんなアイデアをコードに落とし込んでいく間、規約を守らなくてはという意識が思考を妨げてばかりでは害が大きすぎると言えます。
また、一人前のプログラマはそれぞれにコーディングスタイルを持っており、美しいと感じるインデント幅や{}の位置が異なっているものです。そのため規約は議論の元になったり、開発のあいだ中プログラマの美意識を傷つけ続けたりすることがあります。規約はできるだけゆるくあるべきです。
幸いなことに、Javaでは総本山の米SunMicrosystemsがコーディング規約を発表しています(注15)。多くのJavaプログラマにとって、もっとも読みなれたソースコードであるJDK付属のソースも、この規約に則っています。あなたが規約を策定する立場にあるのならば、これを適用することで論争を避け、抵抗感を低減するのが賢明でしょう。
また、美しくないと思われる規約の下で開発するプログラマであれば、ソースコードの中でこっそり自己主張するのはやめましょう。どんな規約であれ、全体としてみたときには、規約を守っているというただそのことが可読性を向上させます。
Outパラメータ -- 参照渡し? 値渡し?
参照渡し、値渡し、という言葉を聞いたことがあるでしょうか。これはそれぞれ英語のcall-by-refernceとcall-by-valueの訳語で、メソッド(あるいは関数)呼び出しの際に、実引数が仮引数にどのように渡されるか、を区別する用語です。
Javaにおける引数の渡し方はすべて「値渡し」です。実引数そのものへの参照(注16)が渡されるわけではないので、呼び出されたメソッド側で仮引数の値をどう書き換えようと、呼び出し元で保持している実引数には何の影響もありません。ただし、引数そのものが参照であったとするならば、引数から参照している先への操作はメソッド側でも可能になります。そして、Javaの変数はプリミティブ型を除いては、すべてObjectクラスのインスタンスへの参照です。
リスト20
package example;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.GregorianCalendar;
public class CallByReference {
private static DateFormat df = new SimpleDateFormat("yyyy/MM/dd");
public void callByValueOfReference(Calendar calendar) {
calendar.add(Calendar.YEAR, 1); // [1]
System.out.println("2):" + df.format(calendar.getTime()));
calendar = new GregorianCalendar(); // [2]
calendar.add(Calendar.MONTH, 1);
System.out.println("3):" + df.format(calendar.getTime()));
}
public void testCall() {
Calendar cal = new GregorianCalendar();
System.out.println("1):" + df.format(cal.getTime()));
callByValueOfReference(cal);
System.out.println("4):" + df.format(cal.getTime()));
}
}上の例はどのような出力を行うでしょうか。testCall()を呼び出すmainメソッドを追加したとすると、以下のような出力になります。
C:K2tmp>java -classpath . example.CallByReference
1):2001/12/13
2):2002/12/13
3):2002/01/13
4):2002/12/13 testCall()ではCalendarクラスのインスタンスをnewし、それへの参照をローカル変数calに保持します。続いてcalを実引数としてcallByValueOfReference()を呼び出します。呼び出されたcallByValueOfReference()では、calが保持しているインスタンスへの参照値を仮引数calendarで受けます。callByValueOfReference()内でcalendar.add()する[1]ことで、仮引数calendarと実引数calがともに参照しているインスタンスの内部状態が変更されます。しかし、仮引数calendarに別のインスタンスへの参照を代入[2]しても、実引数であるcalにはなんの影響も与えません。C++などでいうところの参照渡しであった場合、calにもcalendarに代入されたのと同じ新しいインスタンスへの参照が代入されてしまいます。これが参照の値渡しです。
さて、メソッドがOut(In/Out)パラメータを持つことについてですが、これを実現するためには参照渡しが必要になります。たとえば以下のC++のコードはIn/Outパラメータの例です。
リスト21
#include
int func(int &xref) {
int tmp = 3;
tmp *= xref;
xref *= 2;
return tmp;
}
void main(void) {
int x = 10;
int ret = func(x);
cout << "x:" << x << endl << "ret:" << ret << endl;
}
この例では、func は参照渡しとして宣言された仮引数xrefを関数内部での計算に使った上で、その計算結果としてxref自体の値を変更すると共に別の計算結果を返却しようとしています。このプログラムの実行結果は以下のようになります。
[k2@tech k2]$ ./a.out
x:20ret:30 これと同じ処理をJavaにおいて実現しようとした場合、プリミティブへの参照渡しを実現するためのラッパークラスを導入して以下のように書くことができます。
リスト22
package example;public class OutParameter {
public int func(IntWrapper xref) {
int tmp = 3;
tmp *= xref.i;
xref.i *= 2;
return tmp;
}
public static void main(String args[]) {
OutParameter test = new OutParameter();
IntWrapper x = new IntWrapper(10);
int ret = test.func(x);
System.out.print("x:" + x.i + "nret" + ret);
} static class IntWrapper {
int i;
IntWrapper(int i) {
this.i = i;
}
}
}これで処理はC++のものと全く同様にできますが、ご覧の通りにJavaとしてはトリッキーなコードになってしまっています。こうしたコードは書くべきではありません。このメソッドは例のために作ったものなので本来の意図というものはありませんが、実際のプログラムであれば、そのメソッドはなにをするメソッドであるのか、引数と戻り値にはどのような関連性があって、どうしてそれらが組み合わせて扱われているのか、という理由が明らかになっているはずです。そうであれば、その変数のセットに対して適切な名前を付けクラスを定義し、それを戻り値とする方がJava的です。Javaプログラマにとって読みやすいコードはJavaらしいコードです。
パフォーマンス
プログラミング中は、過剰にパフォーマンスのことを意識すべきではありません。パフォーマンスの最適化は、優れた設計やメモリ効率、可読性などとのトレードオフになるからです。全体を結合して動かしてみた上で、パフォーマンス的に問題があるようであれば、それからはじめて取り組んでも遅くはありません。優れた設計を行っていれば、ボトルネックの特定や改善もしやすくなっているはずだからです。コード上でのパフォーマンス最適化は、必ずボトルネックについてのみ実施します(注17)。
ただ、パフォーマンス改善のテクニックについて知っておくことは重要です。いざというときのためのみならず、イディオム的に使いこなせば、可読性を下げることなくパフォーマンスを「悪化させない」ことができるからです。
String/StringBuffer
いくつかのアプリケーションをプロファイリングしてみると、かなりの確率で、最も多く生成され最も多くの時間を使っているのがStringクラスであることがわかります。設定ファイルの読み込みにはじまり、HTMLの出力、入力の解析やログまで、文字列の操作は、行われる頻度が高い処理です。
ひとつ覚えておかなくてはならないことは、JavaにおけるStringは不変オブジェクトであるということです。不変オブジェクトとは、生成されて以降は値・状態が変化することのないオブジェクトです。
リスト23
String errMsg = "Error:";errMsg += "Closed connection."; このエラーメッセージを生成している例は、素直にコードを読み下すと、「errMsgに対して、エラーをあらわすために先頭に"Error:"を代入し、詳細として"Closed connection."というメッセージを繋ぐ」、Stringオブジェクトはひとつだけ生成されて、そこに続きの文字列が追加されていくかのように思えます。しかしこれが大きな間違いなのです。
Stringは不変オブジェクトなので、"Error:"として生まれたStringオブジェクトが、"Error: Closed connection."というオブジェクトに変化することはありません。このコードの中では目に見えるだけでも、"Error:"、"Closed connection."、それと最終的な"Error: Closed connection."という3つのStringオブジェクトが生成されています。さらに、文字列の連結のために内部的にはStringBufferオブジェクトが生成されます。
一般にオブジェクトの生成はコストの高い処理になりますし、生成されたオブジェクトはガベージコレクトされますので、そこにもコストがかかります。パフォーマンスを向上させるコツとして、オブジェクト生成をできるだけ少なく抑えることが挙げられます。この場合であれば、定数として最終的に必要な"Error: Closed connection."を定義することで、変数1つとオブジェクト3つの生成が省略できます(注18)。
これはあまりにも単純過ぎるので、もう少し一般的な例を見てみましょう。
リスト24
String errMsg = "Errors:";
while(errors.hasNext()) {
errMsg += "t" + errors.next() + "n";} この例の場合だと、コンパイルやコーディングに値を決定することができませんが、このままでは実行時にerrorsの件数に比例した数のStringおよびStringBufferのオブジェクトが、中間データとして生成されては削除されることになります。こうした無駄なオブジェクトの生成を削減したいと思います。
リスト25
StringBuffer errBuf =new StringBuffer("Errors:");
while(errors.hasNext()) {
errBuf.append("t");
errBuf.append(errors.next());
errBuf.append("n");
}String errMsg = errBuf.toString(); このようにタイプ量は増えますが、文字列の連結を行う場合はStringBufferを利用する、とイディオムとして覚えておきましょう。Stringを+で連結するのに比べて、場合によっては数百倍もの速度向上が可能になります。ぜひ簡単なテストコードを書いて、実際に速度を比較してみてください。
こうしたチューニングは、繰り返し実行されることがないとわかっている個所ではあえて行う必要はありませんが、ログ出力ライブラリなど、不確定なStringを扱う利用頻度の高いクラスに適したイディオムです。
さらに速度を向上させたい場合は、StringBufferのコンストラクタで最大サイズを指定し、サイズ拡張が行われないようにすることが効果的です。ただし、バッファサイズという余計な定数が増えてしまうので、この手法は実測後のチューニングに取っておいたほうがいいでしょう。
- 注1:製品でなくともバグがあっては使い物にはなりませんが、製品でなければ「使い物にならなくてはならない」ということもありません。趣味のプログラムでも、もちろん「使い物になるようにしたい」場合は同じことですね。
- 注2:Java言語仕様 James Gosling , Bill Joy , Guy Steel , Gilad Bracha (著), 村上 雅章 (訳) ピアソン・エデュケーション ISBN: 4894713063
- 注3:Java仮想マシン仕様 Tim Lindholm , Frank Yellin (著), 村上 雅章 (訳) ピアソン・エデュケーション ISBN: 489471356X
- 注4:malloc()はCにおけるメモリ確保関数。free()はmalloc()で確保したメモリを解放する関数。malloc()で確保されたメモリがfree()されないと、マシンのメモリリソースをどんどん食いつぶし、ついにはOut of memory が発生する。deleteはC++においてnewによって生成したオブジェクトを解放する演算子。C++では明示的にdeleteされなくてはならない。
- 注5:java.lang.ref パッケージに用意されている各種の参照オブジェクトを用いた場合はその限りではありません。
- 注6:ここでは、「オブジェクト」は「インスタンス」と同じ意味で考えています。「メモリ上に存在するクラスの実体」といったほどの意味です。
- 注7:ちなみにObjectクラスで定義されているequals()メソッドは同一性の比較、すなわち「return (this == obj);」です。少なくとも同一であれば同値ではあるためです。また、equals()とあわせてhashCode()メソッドもオーバーライドすることが推奨されますが、ハッシュについての詳細は本稿では割愛します。
- 注8:このアプローチの適用を広げていくと「Template Methodパターン」に行き着くでしょう。
- 注9:あるいはコマンドのスーパークラスになる抽象クラスで、「Template Method」にしてもいいでしょう。
- 注10:Decoratorパターンになります。一般的なDecoratorパターンでは機能を追加するところ、このクラスではclose()機能を制限していますが、「close()が呼ばれたらRuntimeExceptionをthrowする」という責務を追加したと考えます
- 注11:オブジェクト指向における再利用のためのデザインパターン Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides (著), 本位田 真一, 吉田 和樹 (翻訳) ソフトバンクパブリッシング ISBN : 4797311126。通称 GoF本とも。
- 注12:引き継いだプロジェクトに数冊に渡るようなドキュメントがあれば、「これは助かった」と思います。ところが、時間をかけて調べてみてもなんの役にも立たないことばかり書いてあって、本当に知りたいことはソースを読むしかないというのは、実際によくある話です。そんなドキュメントならいっそ最初からなければ......。
- 注13:「このプログラムに機能追加してくれ」「わかりました。それでは仕様書をいただけますか?」「そんなものはないよ。ソースに全部書いてあるだろう、それ見てやってくれ」「......(涙)」という目に遭うプログラマの助けになるように、と思ってください。筆者は記憶力に自信がないので、数ヶ月前に自分が書いたソースコードに隠された意図を思い出すことができません。そのかわいそうなプログラマは、数ヶ月後の自分かもしれません。
- 注14:もちろん数ヶ月後の自分も含めて。
- 注15:http://java.sun.com/docs/codeconv/html/CodeConvTOC.doc.html
- 注16:このあたりでは、特に「参照」あるいは「ポインタ」という用語については議論があります。以下のURLから始まるスレッドなどが参考になるでしょう。ここではこれ以上深入りすることはしません。 http://java-house.jp/ml/archive/j-h-b/028625.html
- 注17:80/20ルール:「全体のボリュームのうち20%が、使われる頻度の80%を占める」という一般的な法則があります。この場合、「コード全体の20%を実行している時間が全体の実行時間の80%を占める」ということになりますので、その20%以外をいくらカリカリにチューニングしたとしてもなんの性能向上にもならないということです。
- 注18:コンパイラによる最適化で、コンパイル時に決定できる文字列のリテラルはひとつにまとめられることも多いと思われますが、コンパイラの実装依存になりますので、それについてはここでは考慮に入れていません。