Web系企業が元気なワケ
あけましておめでとうございます。いろいろあった2005年も終わり、新しい年2006年が始まりました。本題の前にまず、皆様の今年のご多幸をお祈り申し上げます。
年の初めでもありますので、今回は肩の力を抜いて一緒に楽しんでいただける話にしましょう。テーマは「Web サービス」です。Webサービスは、Web系の技術者の方にとっては今後の糧となる可能性を秘めた重要なテーマですが、今回は「個人でちょっと楽しむには」という視点でWebサービスを解説します。
また、WebサービスというとUDDI、WSDL といった技術系の話から、Webを利用したビジネスサービスの話まで広範にわたりますが、今回は後者に近い話として、さまざまな企業がインターネットで提供しているサービスを利用します。最近、GoogleやAmazonといったWeb系企業が元気ですが、Webサービスは、そうした企業の元気の源になっています。なぜ、Webサービスが元気の源なのでしょうか。また、Webサービスはどこに使われていて、私たちはWebサービスをどう利用できるのでしょうか。今回はその辺りも紹介していきます。
今どきのWeb サービスとは
一般的なWebサイトは、Webブラウザに対してHTML文書を提供しています。ご存知のとおり、普段私たちがWebサイトに対してアクセスした際に受け取っているのはHTML 文書です。このHTML文書は、CSSやスクリプト言語とともに1つの画面を構成し、人間にとって使いやすいインターフェイスを提供しています。
時代は進み、Webサイトに対するニーズも徐々に変化を見せつつあります。その変化の1つが「利用者の多様化」です。Webサイトが提供しているサービスをプログラムからも使いたい、というニーズが利用者から出てきたのです。そこで注目されたのがWebサービスです。
HTMLで作成した画面は人間にとって理解しやすいものですが、コンピュータにとっても理解しやすいというわけではありません。HTMLは人間にとって分かりやすい画面を提供するための規格で、データを論理的な構造を持って伝達するためのものではないからです。プログラムでHTML文書を参照しても、必要としている情報を簡単に見分けることはできません。
そこで、Webサイトはプログラムからの利用に対するインターフェイスとしてHTML 文書ではなくXML文書を返すWebサービスのAPI(注1)を公開し始めました(図1)。WebサービスのAPIが公開されることで、プログラムから容易にWebサイトが提供するサービスを利用できるようになったわけです。今では、WebサービスAPIを利用したさまざまなプログラムが公開されており、Web サービスAPIを公開したWebサイトの中には、サービス利用者数を大きく伸ばした例も多数あります。前述のGoogleやAmazonなどは、Webサービスをうまく利用することでサービス利用者数を伸ばした典型的な成功例です。
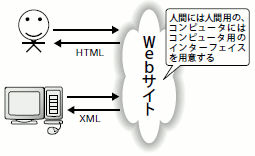
図1 Webサービスはコンピュータ用のインターフェイス
WebサービスAPI公開を呼び水としてサービス利用者数の拡大を目指し、Webサイトは続々とWebサービスAPIの公開を始めています。特に、サービス利用者の増加が直接メリットにつながるWebサイトでは、その傾向が顕著です。現在では、GoogleやYahoo!などの検索エンジン、Amazonなどの小売業、del.icio.us、Bulkfeedsなどブログ系サービスなど数多くのWebサイトが、WebサービスAPIを公開しています。
Webサービスの意味
さて、WebサービスAPIが公開されるということにはどのような意味があるのでしょうか。
現在、Javaなどによる業務アプリケーション開発の現場ではフレームワークやライブラリの利用が進んでいます。さまざまな機能を提供するフレームワーク、ライブラリが多数公開され、また企業単位、プロジェクト単位でも独自のフレームワークやライブラリが整備されています。その結果、開発作業は一昔前と比べて格段に効率が高まりました。フレームワーク/ライブラリを適切に用いると、コードの再利用が進み、開発効率やコードのメンテナンス性が向上するためです。コードの再利用による恩恵を得るための機構がフレームワークやライブラリだとも言えるでしょう。
一方、Webサービスはフレームワーク、ライブラリよりも大きな粒度でプログラムを再利用する機構だと言えます。具体的には、「サービスやコンテンツの再利用」を実現します。Amazonを例に取って考えてみましょう。Amazonは膨大な商品情報というコンテンツを持っており、加えてそれらのコンテンツに対するサービス(検索、ショッピングカートなど)も持っています(図2)。同等のサービス、コンテンツを自力で用意するのは非常に大変ですが、AmazonのWebサービスAPIを利用することで、Amazonが提供するサービスやコンテンツを取り込んだアプリケーションなどを簡単に構築できます(図3)。
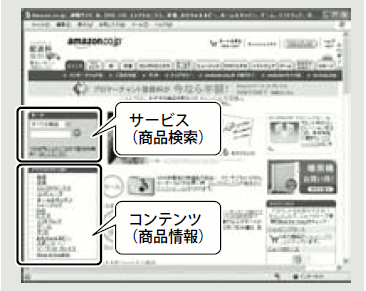
図2 Amazonのコンテンツとサービス
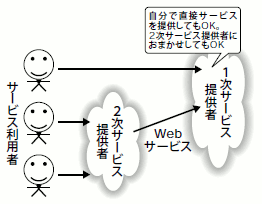
図3 1次サービス提供者と2次サービス提供者を結ぶWebサービス
こうしたWebサービスAPIは、サービス提供者が自らの利益のために公開しているものですので、当然、最終的な利益はサービス提供者に入る仕組みになっています。しかし、これらのAPIが上手に活用されることで、サービス提供者とWebサービスAPIの利用者がうまくWin-Winの関係を作っていくことは可能です。
また、WebサービスAPIを利用するちょっとしたプログラムを作ることは、非常に簡単で楽しいものです。利益云々はとりあえず置いておいて、勉強がてらにWebサービスAPIで遊んでみるのも悪くありません。WebサービスAPIは非常に簡単です。HTTPとXMLに関する少しの知識と多少のプログラミング経験があれば、誰でも利用できます。
すでに多くのWebサービスが利用可能に
では、WebサービスAPIを利用することで何を実現できるのでしょうか。
複数のサービスをまとめることで付加価値を高めたり、目的に特化したユーザーインターフェイスを提供したりと、WebサービスAPIはさまざまな用途で利用できます。WebサービスAPIの役割は、コンテンツ(検索結果や商品)を、ある程度の制約があるにせよ、自由に利用できるようにすることですから、WebサービスAPIを利用することでたいていのことは実現できてしまいます。複数のWebサービスを連携させることで、利用できるコンテンツの幅や量も飛躍的に広がりますから、まさしく「何でもあり」といった感じです。WebサービスAPIの利用はアイデア勝負であり、使いようによっては非常に面白いことができる技術と言えるでしょう。
すでに、多くのWebサービスAPIが実際に利用されています。例えば、ブログで商品を紹介する際の商品情報表示で利用されたり、地図情報表示で利用されたりしています。また、複数のWebサービスをまたいで検索できる複合検索サイトなどでも、WebサービスAPIが利用されています。これらはサービスの2次提供者だと言えるでしょう。また、中には自分のブログへのエントリ登録の際にWebサービスAPIを利用することで、面倒な作業(エントリ登録、画像登録、更新情報通知サービスの更新)を自動化している人もいます。
現在、Webサービスとして提供されているコンテンツには、検索エンジン系が提供しているWebサイト情報、ブログ情報、画像情報や、小売業系が提供している商品情報、地図情報など、さまざまなものがあります。それらのうち、主だったものを表に示します。挙げたのは有名どころだけですが、ほかにもまだまだたくさんのWebサービスが公開されています。

表 代表的な公開Webサービス
Webサービスを使ってみよう
それでは、実際にWebサービスAPIを使用してみましょう。まずは、Webブラウザから、 http://bulkfeeds.net/app/search2.rdfWeb%20Service へアクセスしてみてください。WebブラウザにXML文書が表示されたと思います。これで、WebサービスAPIを利用してコンテンツを取得できました。「これだけ??」と驚かれた方もいることでしょう。本当にたったこれだけです。簡単に説明しておきましょう。
"http://bulkfeeds.net/"は、Bulkfeedsというブログ専門の検索エンジンを公開しているWebサイトです。まずは"/app/search2.rdf"を呼び出すことで、Bulkfeedsに検索を指示します。検索に使用するクエリは"q=Web%20Service"で示されており、ここでは"Web Service"というキーワードで検索しています(%20は半角スペースを意味しています)。
Bulkfeedsにこのリクエストを送信すると、検索結果をRSS(注2)フォーマットで受け取ることができます。Webブラウザに表示されたのが検索結果のRSS文書です。ここでは、Bulkfeedsから受け取ったRSS文書を単純にWebブラウザに表示させましたが、実際にはプログラムでさまざまに加工して利用します。
なお、多くのWebサービスAPIでは、利用する際にIDを発行してもらわなければなりません。通常は無料でIDを発行してくれる機能がWebサイトに用意されていますので、その機能を利用してIDを取得してください。以降では、使用するWebサービスAPIのIDを取得している前提で話を進めます。紹介するサンプルコードを完全に動作させるには、取得したIDの設定が必要です。
ちなみに、先ほどBulkfeedsをサンプルとして利用したのは、Bulkfeedsの一部の機能がIDを取得していなくても利用できるという嬉しいサービスになっているためです。
Webサービスの呼び出し方法
では次に、Webサービスを呼び出す方法をもう少し詳しく説明します。
Webサービスを呼び出す方法には、大きく分けて「REST(REpresentational State Transfer)」と「SOAP(Simple ObjectAccess Protocol)」があります。どちらもHTTPリクエストをWebサービスに送信して結果をXML文書で受け取るものですので、根本的には何も変わりません。異なるのは、Webサービスへのパラメータの受け渡し方法だけです。RESTは、パラメータを文字列として定義し、HTTPのGETメソッドやPOSTメソッドで送信します。一方、SOAPではパラメータをXMLデータとして定義し、やはりHTTPのGETメソッドやPOSTメソッド(注3)で送信します。SOAPは、RESTの1つのパラメータをXML化したものとほぼ同義となります。
RESTはリクエストが単純なURLとなるので簡単に利用でき、SOAPはパラメータをXML形式で記述するために複雑なリクエストを定義できます。実際には、WebサービスAPI側でRESTとSOAPのどちらに対応しているかが決められていますので、それに従って使い分けます(図4)。
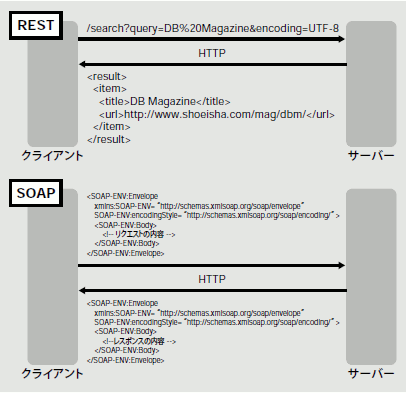
図4 RESTとSOAP
ちなみに、現在はSOAPよりもRESTがよく使われているようです。RESTだとリクエストの際にわざわざXMLデータを組み立てる必要がないため、WebサービスAPIの利用者の受けが良かった、ということのようです。
コラム:Web 2.0とは
「Web 2.0」という言葉をご存知でしょうか。最近話題に上ることが多くなったので、ご存知の方も多いと思います。Web 2.0はティム・オライリー氏らが提唱する概念で、新しいタイプのWebサイトを表わす言葉として利用されています。
オライリー氏のブログによるWeb 2.0の解説によると、Web 2.0に該当するWebサイトには2つの原則があるそうです。1つ目はプラットフォームとしてのWeb、2つ目は「集合知」の利用です。この2つの原則をうまく利用しているWebサイトが、Web 2.0に対応したサイトということになります。
Web 2.0として挙げられているWebサイトには、GoogleやFlickrなどがあります。これらのWebサイトがWebサービスを提供しているというだけでWeb 2.0と呼ばれているわけではありませんが、Webサービスの提供が大きな要因になっていることは明らかです。Webサービスが新しいWebサイトの大きな特徴と考えられているのは間違いありません
現在のWeb 2.0という言葉はビジネス色の強いものとして受け取られており、技術者の中には否定的な見方をする人も少なからずいるようです。Web 2.0が即仕事で役に立つという人は意外と少ないと思いますので、今は情報を集めつつ今後の動向を見守るという感じでしょうか。
注A:米国の出版社、オライリー&アソシエーツ社の社長。
注B:http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.htm (翻訳は、 http://japan.cnet.com/column/web20/story/0,2000054679,20090039,00.htm)
注C:現在のインターネットでは、多くの人々がさまざまな情報を提供し合うことで全体として大きな知識を形成している。ここではその知識のことを集合知と呼んでいる。
注D:個人の写真を登録し、参加者で共有するWebサイト。http://www.flickr.com/
コラム:RDF/RSS/Atomからオントロジ/セマンティックWebへ
Webサービスについて調べていると、よく「RDF」「RSS」「Atom」といった用語を見かけ ます。これらはいったい何なのでしょうか。
RDFはResource Description Frameworkの略で、リソース(ここでは、URIで識別可能であるもの、という意味)に関する情報について記述するためのモデルです。RDFを利用することでさまざまなリソースのメタ情報を記述でき、情報に対する自動処理を効率的に行なえるようになります。
RSSはRDF Site Summary(注)の略で、Webサイトのサマリ情報を記述するためのRDF拡張仕様です。ただし、現在多く利用されているバージョンのRSSは、その後の仕様変更によりRDFの拡張ではなくなっています。
AtomはRSSと同様にWebサイトのサマリ情報を記述するための仕様ですが、RSSとは異なり、元からRDFをベースとはしていません。AtomはRSSの複数バージョンの乱立による混乱や、RDFをベースにしたことに起因する複雑さなどを解消することを目的として策定された仕様です。
さて、前述のようにRDFはリソースのメタ情報を記述するための仕様ですが、これはリソースの自動処理が目的となっています。RSSやAtomは、サイト情報に特化した仕様であるため、サイト情報に関する自動処理で力を発揮しています。しかし、インターネット上にはサイト情報以外の情報も多数存在しており、それらの自動処理はなかなか進んでいません。リソースの自動処理を行なうためには、あらかじめリソースの情報を知らなければならないためです。
これを解決するために「オントロジ」という考え方が導入されました。オントロジは人間が常識として持っている概念を整理したものであり、例えば「生物」「動物」「植物」といったものがオントロジに当たります。
一般的に人間が持っている概念、すなわちオントロジは非常に膨大です。インターネット上で流通しているデータだけに絞ったとしてもその数はかなりのものとなります。これらのオントロジを整理/分類することで、最終的には情報がいったいどういうものであるのか、ほかのどの情報とどういう関係を持っているのかを記述できるようにする研究が現在も続けられています。
その研究の目標として掲げられているのが「セマンティックWeb」です。セマンティックWebでは、すべてのリソースをURIで識別し、さらにRDFを使用することでそれらのメタ情報やリソース間の関係を記述します。その結果、コンピュータが自動的にリソースの内容を判断し処理できるようになると言われています。
WebサービスとセマンティックWebの間にはまだ大きな隔たりがありますが、一昔前と比べると少し前進しているように感じられます。すぐにオントロジやセマンティックWebの知識が必要となることはありませんが、これらについてある程度の知識を得ておくことで、現在のWebの進んでいる方向が多少見渡しやすくなるはずです。
注A:バージョンによってはRich Site SummaryやReallySimple Syndicationが略とされることもあり、非常に紛らわしい。
JavaScriptから使ってみよう
まずは、JavaScriptを利用して「Yahoo!検索Webサービス」を呼び出してみましょう。LIST1がそのサンプルコードです。このサンプルでは、テキストボックスにクエリが入力されると即座に検索処理が実行され、テキストボックスの下部に検索結果が表示されます。キーを押すたびに検索が実行されますので、表示される検索結果はどんどん変わっていきます。いわゆるAjax(注4)的な動きをします(画面1)。
このサンプルには2つのポイントがあります。1つ目は、リクエスト用のURL組み立てです。Yahoo!検索WebサービスではRESTを用いて通信を行ないます。今回はHTTPのGETメソッドを利用しているため、検索用のクエリなどはすべてURLに埋め込まれます。2つ目のポイントは、XMLHttpRequestクラスです。XMLHttpRequestは、HTTP通信とDOM(注5)の機能を兼ね備えたクラスで、Webサービスへのアクセスと取得した結果の解析には、まさにぴったりと言えます。XMLHttpRequestに慣れていないと、このサンプルコードは複雑に見えるかもしれません。しかし、実際に処理している内容は前述のとおり、HTTPリクエストの送出と受け取った結果の解析のみの非常に単純なものです。
なお、今回利用しているXMLHttpRequestクラスは、セキュリティ上の都合で本来HTMLが設置されているのと同一ドメインにしかアクセスできません。ただし、HTMLファイルをローカルマシンに配置している場合、Internet ExplorerなどのWebブラウザでは外部にアクセスすることが可能です。そのため、サンプルはローカルマシンに配置しないと動作しない作りになっています。
LIST1 JavaScriptを利用してYahoo!検索Webサービスを呼び出す
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=UTF-8">
<title>Yahoo検索 Web サービスサンプル </title>
<script type="text/javascript">
<!--
function searchByYahoo() {
/* テキストフィールドに入力された値を使用してリクエスト用のURLを組み立てる。[ID]にはYahoo!検索Webサービス用に取得したIDを入れる */
var keyword = document.myform.query.value;
if(keyword == null || keyword == ""){
return;
}
var request = "http://api.search.yahoo.co.jp/WebSearchService/V1/webSearch?appid=[ID]&query="
+ encodeURI(keyword);
/* XMLHttpRequestにリクエストの情報をセットして送信 */
var httpRequest = new ActiveXObject("Microsoft.XMLHTTP");
/* 検索結果を受け取った後の処理。検索結果のXMLはXMLHttpRequestが解析してくれるので、そこからタイトルとURLを受け取ってHTMLを組み立てる。HTMLは"result"というIDのブロックにセットする */
httpRequest.onreadystatechange = function(){
if (httpRequest.readyState == 4) {
if (httpRequest.status == 200) {
var rootElement = httpRequest.responseXML;
var resultElements = rootElement.getElementsByTagName('Result');
var html = "<br><ul>";
for (var i = 0; i < resultElements.length; i++) {
var resultElement = resultElements[i];
var title = resultElement.getElementsByTagName('Title')[0].firstChild.nodeValue;
var url = resultElement.getElementsByTagName('Url')[0].firstChild.nodeValue;
html += "<li><a href="" + url + "">" + title + "</a></li>";
}
html += "</ul>";
document.getElementById('result').innerHTML = keyword + "<br>" + html;
}
}
}
httpRequest.open("GET", request, true);
httpRequest.setRequestHeader("Content-Type" , "text/xml");
httpRequest.send(null);
}
//-->
</script>
</head>
<body>
Yahoo 検索 Web サービスサンプル <br>
/* 検索用クエリを入力するテキストフィールド */
<form name="myform">
QUERY : <input type="text" name="query" onkeyup="searchByYahoo()">
</form>
/* 検索結果を表示するブロック */
</body>
</html>
※ このサンプルは Internet Explorerでのみ動作可能。 ..
画面1 LIST1を実行したところ
Javaから使ってみよう
では次に、JavaプログラムからYahoo!検索 Webサービスを呼び出してみます。LIST2がサンプルコードになります。このサンプルは、コマンドラインから検索用のクエリを受け取り、Yahoo!検索Webサービスで検索をします。その後、検索結果を標準出力に出力します。入力/出力が異なるだけで、基本的には先ほどのJavaScriptのサンプルとまったく同じ処理内容となっています(画面2)。
このサンプルには3つのポイントがあります。1つ目は、JavaScriptのサンプルと同じくリクエスト用のURL組み立てです。ここでもJavaScriptのサンプル同様に、REST用のURLを作成しています。
2つ目は、java.net.URL(注6)とjava.net.URLConnection(注7)によるWebサービスの呼び出しです。java.net.URLやjava.net.URLConnectionはJ2SE(Java 2 Standard Edition)で標準提供されているクラスですので、J2SE環境下であれば簡単に利用できます。当然ですが、java.net.URLConnectionの代わりにJakarta Commons Net(注8)など外部のライブラリを利用しても問題ありません。
3つ目は、DOMによる検索結果の解析です。JavaではXMLの解析方法は種々ありますが、ここではJAXP(注9)のDOMを利用して解析を行なっています。結果的にXMLが解析できればまったく問題ありませんので、必要に応じてSAX(注10)などのほかの手段を使っても構いません。
LIST2 Javaを利用してYahoo!検索Webサービスを呼び出す
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class YahooWebServiceSample {
public static void main(final String[] args) throws IOException,
ParserConfigurationException, SAXException {
if (args == null || args.length <= 0) {
return;
}
YahooWebServiceSample .search(args[0]);
}
protected static void search(final String keyword) throws IOException,
ParserConfigurationException, SAXException {
/* メソッドの引数として受け取った値を使用してリクエスト用のURLを組み立てる。[ID]にはYahoo!検索Webサービス用に取得したIDを入れる */
String encodedKeyword = URLEncoder.encode(keyword, "UTF-8");
URL request = new URL(
"http://api.search.yahoo.co.jp/WebSearchService/V1/webSearch?appid=[ID]&query="
+ encodedKeyword);
/* URLConnectionを使用してリクエストを送信 */
URLConnection connection = request.openConnection();
InputStream is = null;
try {
is = connection.getInputStream();
/* 検索結果のXMLはDOMを使用して解析する。DOMからタイトルとURLを受け取って標準出力に出力する */
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
Node rootElement = document.getFirstChild();
NodeList children = rootElement.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
if ("Result".equals(child.getNodeName())) {
NodeList grandchildren = child.getChildNodes();
String title = null;
String url = null;
for (int j = 0; j < grandchildren.getLength(); j++) {
Node grandchild = grandchildren.item(j);
if ("Title".equals(grandchild.getNodeName())) {
title = grandchild.getFirstChild().getTextContent();
} else if ("Url".equals(grandchild.getNodeName())) {
url = grandchild.getFirstChild().getTextContent();
}
}
System.out.println("" + title + "-" + url);
}
}
} finally {
if (is != null) {
is.close();
}
}
}
}
画面2 LIST2を実行したところ
2つのWebサービスをミックスして使う
最後にもう1つ、簡単なサンプルアプリケーションをJavaScriptで組んでみました。もうすぐトリノオリンピック開催ということで、トリノオリンピックに関する情報を集約する自分専用ポータルです。
このサンプルでは、Yahoo!検索WebサービスとAmazon Webサービスを利用しています(画面3)。先ほどとまったく同じ要領で単純にJavaScriptを使用してWebサービスを呼び出しているだけなので、作成は非常に簡単ですが、この画面でトリノオリンピックの最新情報をいつもウォッチできてとても便利です(多分)。
画面3 トリノオリンピックに関する情報を集約する「自分専用ポータル」
このサンプルの情報ソースはYahoo!とAmazonだけですので、実際のところ、便利という印象はあまり受けないかもしれませんが、Googleやブログ検索サービスなどをさらに呼び出すことで、どんどん便利にしていくことができます(多分)。定期的に集めたい情報がある場合には、この仕組みが意外と重宝するかもしれません。
おわりに
Webサービスの背景と簡単な使い方をざっと眺めてきました。Webサービスとはいったいどういうものであるかは、概ね理解していただけたのではないかと思います。
既存サービスを利用して2次サービスを提供するWebアプリケーションの開発は、まだ少ないと思います。しかし、Webサービスなどの環境が段々と整ってきていますので、今後は2次サービス提供などWebサービスを利用したシステムの開発も徐々に増えてくることでしょう。
現在のWebサービスは、技術としては非常に新しいものです。そのため、各社各様に仕様を決め、利用者はそれに従うしかないのが現状です。一部OpenSearch(注11)などの標準化に向けた動きも見られますが、現時点ではまだまだと言ったところです。今後はトランザクション管理やセキュリティといった分野でもWebサービスのインターフェイスに関する標準化が進み、Webサービスがさらに使いやすくなってくると思います。とりあえず今はそのときを待ちながら、いろいろなWebサービスを使って楽しんでいることにしましょう。
- 注1:Application Program Interface の略。プログラムが外部のプログラムからの呼び出しを受け付けるインターフェイス。
- 注2:RDF Site Summaryの略。Webサイトのサマリ情報をXMLで記述するためのフォーマット。
- 注3:SOAPは、バージョンによってはPOSTメソッドでなければ通信できません。バージョン1.2からGETメソッドによる通信がサポートされます。そのため、現時点ではPOSTメソッドでないとSOAPを受け付けてくれないWebサービスもあります。
- 注4:JavaScriptの非同期通信機能を利用して、ノーマル の HTMLよりもリッチなインターフェイスを実現する 技術。
- 注5:Document Object Modelの略。XMLを解析する方法の1つ。
- 注6:URLを表わすクラス。J2SEに標準で用意されている。
- 注7:java.net.URLの情報を基に実際に Webサーバーと 通信を行なうクラス。 J2SEに標準で用意されている。
- 注8:Javaのオープンソースソフトウェア開発を行なって いるApache Jakartaプロジェクトが開発しているネット ワーク通信用の汎用ライブラリ。
- 注9:Java API for XML Processingの略。 JavaでXML 文書の読み書きなどの処理を行なう機能。
- 注10:Simple API for XMLの略。DOMと同様にXML を解析する方法の 1つ。
- 注11:http://opensearch.a9.com/
石川智久(いしかわともひさ)
元々はテーブル設計が得意分野だったが、より概念的な方向に興味を持ちはじめ、アナリシスパターン的な世界へ徐々に移行中。一方で、アーキテクトとしてプロジェクトに参加する機会も増え、自分が「アーキテクト」なのか「モデラー」なのか分からなくなっている。中堅SIerを経て、2002年より現職。
高橋英一郎(たかはしえいいちろう)
JavaによるWebアプリケーション開発一筋で生計を立てている。現職では商用J2EE Webアプリケーションフレームワークの開発に従事。いかにして楽にWebアプリケーションを構築するか、日夜頭を悩ませている。
山本啓二(やまもとけいじ)
関東在住の阪神ファン兼コンサルタント。日本シリーズ観戦成績が、3年越しで4連敗となりました。ロッテの強さは本物ですね。でも、来年4勝して5割に戻す予定です。著書に『プログラマの「本懐」』