近年、大規模で複雑なWEBシステムはアプリケーションサーバを使用して構築するのが常識となりつつある。J2EEの生産性の高さや、アプリケーションサーバの高速性など、CGI + Perlを利用した従来の WEBシステムと比べて、アプリケーションサーバを使用することのメリットは非常に大きい。
アプリケーションサーバを使用して、WEBシステムを開発したが、いざ運用を始めようという段階になって思ったように性能がでないであるとか、運用開始後、順調にアクセス数が増えてきてパフォーマンスが厳しくなってきたというような経験をした読者も多いと思う。
本稿では、実際に筆者が行っている方法をベースにWEBシステムのパフォーマンスチューニングの方法を解説していく。
WEBシステムのパフォーマンスチューニング理論編
理論編では、筆者がWEBシステムのパフォーマンスをチューニングする際に行っている方法をベースにチューニングの方法を解説する。実際のチューニングの方法はシステムによりまちまちであり、システムのアーキテクチャによりチューニングの方法も大きく変わるのであるが、ここではアプリケーションサーバを使用してWEBシステムであれば、多くのシステムに適用できるであろうことを中心に解説する。
パフォーマンスが向上に結びつきそうなことを、いろいろ実施してみたのだが思うように性能が向上しないという話をよく聞く。そのようなケースでは、ボトルネックが何処にあるのかを見誤り、あるいはボトルネックが何処にあるのかを見極めずにチューニングを行い思うような性能が得られていないことが多いのではないかと想像する。ボトルネックに対してチューニングを施して、はじめてチューニングは高い効果を得られるるのであり、やみくもにチューニングのテクニックを適合しても、大抵は思うような性能の向上など得られない。
筆者は、ボトルネックを見つけることこそがチューニングの中心であり、ボトルネックが特定されればチューニング作業は半分は終了したようなものと考える。以下、どのようにしてボトルネックを見つけるのか、そしてそのボトルネックに対してどのように対処するのかと行った観点で解説をしていく。
本特集の執筆に当たっては、WEBサーバにApache, アプリケーションサーバにBEAのWebLogic, DBサーバにはOracleを使用することを想定している。しかし、これから解説することは、基本的にプロダクトに依存しないので、Apache, WebLogic, Oracle以外のプロダクトを使用している読者にも十分役立つはずである。
チューニングのサイクル
チューニングは、ボトルネックを見つけだし、何故そこがボトルネックになっているかを推定し、ボトルネックを解消するための対処を施し、その効果を確認するというサイクルを繰り返すことによって行わなければいけない。
図4は筆者が考えるチューニングのプロセスを図式化したものである。
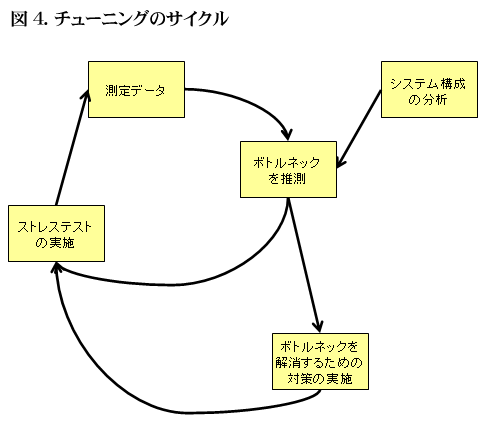
図4
チューニング作業の中心となるのは、ボトルネックがどこにあるかを推測することである。この推測の為のベースとなるのが、測定データとシステム構成の分析となる。測定データには負荷テストを実施したときの結果であったり、実際にシステムを運用したときに取得したデータであったりする。システム構成の分析は、アプリケーションプログラムのアーキテクチャや、ネットワークの構成を考えてボトルネックになりそうな箇所を予想することである。
測定結果から、ボトルネックが明確に分かることも多いが、ボトルネックの原因の候補が幾つか上がる場合や、ボトルネックの候補は見つかったが本当にボトルネックであるかを確信が持てないということも多いだろう。
ボトルネックが明確に分からない場合は、どうすればボトルネックを見つけだせるかと視点から考える。アプリケーションのアーキテクチャを詳細に検討することによって、ボトルネックを特定することもあるし、本当にそこがボトルネックになっているかを確認するためのテストを実施することもある。
システムのどこにボトルネックがあるかが見つかれば、それに応じた対策を行う。
ボトルネックとなる箇所によって、取るべき対策のパターンがある。次項でボトルネックになりやすい箇所とその対策のパターンを示すので参考にしてほしい。
どこがボトルネックになるか
図1は、筆者が想定するWEBシステムの例である。システムは複数のWEBサーバ、アプリケーションサーバとDBサーバから構成され、ルータ、ファイヤーウォール、SSLアクセラレータ、ロードバランサー等のネットワーク機器を解してインターネット/イントラネットに接続している。ユーザは、PC上のブラウザから、インターネット/イントラネットを介してシステムにアクセスする。これらの機器のすべてがボトルネックになりうる。これから、それぞれの機器について、どこがボトルネックになりやすいのかを見ていく。
図1はかなり大規模な例であるが、例えば図2のような小規模な構成でも基本的な考え方はほとんど変わらない。
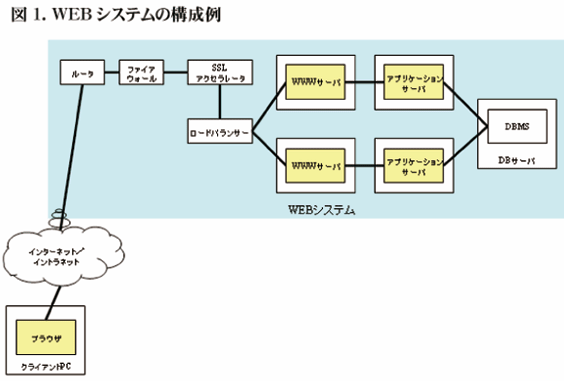
図1
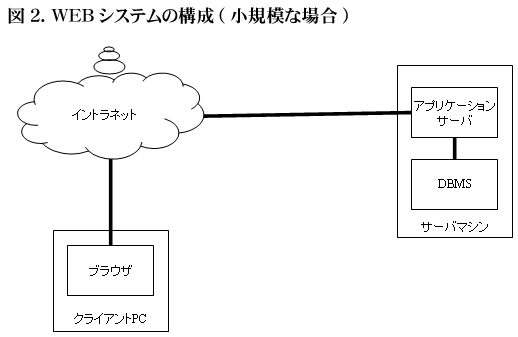
図2
インターネットとの接続回線
サーバ側の能力がいくら高くても、対インターネットとの接続回線の容量以上の性能はだすことはできない。専用線のコストが高いため、回線速度がボトルネックになっているシステムも多いだろう。
WEBサーバ
アプリケーションサーバを使用する場合は、WEBサーバ側には、htmlファイルや画像ファイルなどの静的なコンテンツのみを置き、動的なコンテンツの作成はアプリケーションサーバに任せるのがセオリーである。静的なコンテンツのみをおくのであれば、現在のWEBサーバは10MbpsのLANの帯域を簡単に使い切ってしまうくらいの能力がある。
WEBサーバには、静的なコンテンツのみを置くようにし、後に述べるSSLの問題がないのであれば、よほど大規模なシステムでない限り、WEBサーバがボトルネックにはならない。
SSLを使わないHTTPによるリクエストであれば、WEBサーバはローエンドのPCサーバを使用したときでさえ、少なくとも毎秒100程度のリクエストを処理できる能力がある。
相当に大きなシステムでなければ毎秒100もアクセスはないであろうし、インターネットとの接続回線が毎秒100ものアクセスに耐えられるほどの容量を持たないのが普通(注1)なので、通常は、WEBサーバがボトルネックにはならない。
SSL
SSLを使ったHTTPSによる通信は、SSLを使わないHTTPによる通信と比べて非常に大きな負荷をWEBサーバに与える。場合によっては、WEBサーバは1CPUあたり数件のSSLのリクエストしか処理できない。SSLによるアクセスが毎秒1以上あるのであれば、WEBサーバがどの程度SSLのアクセスを処理できるのかを測定の上、必要な処置をとる必要がある。
SSLの性能は、サーバのCPUや、WEBサーバの実装によってかなり異なる。どの程度SSLの性能が出るのかは、実際にシステムの運用時に使用するプラットホームと同じ環境で測定してみて欲しい。測定の結果、SSLを使用しても十分な性能があることが分かるかもしれないし、対策が必要になることもある。
SSL通信がボトルネックになる場合、対策は2通り考えられる。WEBサーバの台数を増やす方向と、SSLアクセラレータを導入することである。SSLアクセラレータを使用すると、SSLに関する処理は、すべてSSLアクセラレータが受け持つことになる。ブラウザ側から見ると、SSLを使って通信を行っているのだが、WEBサーバがわから見ると、SSLを使わずに、HTTPで通信をしていることになる(図3)。SSLアクセラレータを導入すれば、SSLアクセラレータのキャパシティが問題になるような非常に大規模なサイトを除いて、SSLが性能のボトルネックとなることはないと考えて良い。
ルータ、ファイヤーウォール
ルータやファイヤーウォールの能力は意外と見落としがちである。ルータや、ファイヤーウォールに100MbpsのLANが接続できるからといって、100Mbpsのデータを転送できると考えてはいけない。数Mbps程度の性能しかでないことも多い。
数Mbps程度の能力があれば、たいていのシステムでは問題ないだろうが、データの転送量が数Mbpsを超えるような大規模なシステムでは、ルータ、ファイヤーウォールの能力がボトルネックとなる可能性がある。
ルーティングや、フィルタリングの設定が増えれば、それに応じてルータ、ファイアウールの性能は低下する。また、WEBシステムは多くのクライアントが比較的小さなデータのやり取りを頻繁に行い、ソケットのセッションの生成を頻繁に行うという性質があるため、FTPを使って大きなファイルを転送するような場合と比べて、転送速度が低下するという性質がある。
ルータ、ファイヤーウォールがどの程度の能力があるかは、負荷テストをして実測して欲しい。なお、スィッチングハブや、Layer 3 SwitchはLANの帯域に比べて十分な性能を持つのが普通なので、基本的にボトルネックになることはないと考えてよい。
アプリケーションサーバ
多くのシステムでは、アプリケーションサーバと次に述べるDBサーバがボトルネックになる。動的にコンテンツを作成する役割をアプリケーションサーバが引き受けるため、多くのロジックがアプリケーションサーバに集中する。この結果、アプリケーションサーバのCPUがボトルネックとなることが多い。
また、アプリケーションサーバのCPU使用率は余裕があり、ディスクI/Oもそれほどないにも関わらず、アプリケーションサーバがボトルネックになってしまうことも多い。このような状況では、アプリケーションサーバのコンフィグレーションパラメータを適当に変更することで大きく性能が向上するこが期待できる。理論編の後半ではアプリケーションサーバの性質とチューニングの方法について詳しくみていく。
DBサーバ
DBサーバはアプリケーションサーバと並んでボトルネックになることが多い。検索をメインにデータベースを使用し、検索の内容がそれほど複雑ではない場合は、DBサーバがボトルネックになることは少ない。
逆に、複雑な検索を行う場合や、大量の更新処理が必要な場合は、データベースがボトルネックになる。この様な場合は、SQL文の見直しや本格的なデータベースのチューニングが必要になる。
DBサーバにはそれほど負荷がかかる処理をしていないにも関わらず、DBサーバがボトルネックになる場合も多い。これは、コネクションプール(コネクションプールについては後で詳しく説明する)を使用していないなど、DBサーバの使い方が適切でないことが原因であることが多い。
クライアントの性能について
サーバ側に問題がなくても、クライアント側の問題で思うように性能が出ないこともある。
クライアントPCとブラウザ
デザインに凝ったページや、大きなTableがあるページを表示する場合など、WEBシステム側ではなく、クライアントPCやブラウザがボトルネックになる可能性もある。特にデザインに凝ったページを作成したときや、大きなTableを使用する場合に注意が必要である。ブラウザによって画面表示に要する時間はかなり異なる。あるブラウザでは、1秒で表示できるWebページを、別のWebブラウザで表示させると5秒かかるといったことが珍しくない。また、エンドユーザは、システムの開発、検証に用いたマシンよりかなりスペックが劣ったマシンを使用しているかもしれないことを考慮しなければならない。
メジャーなブラウザについて、少し古めのPCでもストレスなく使用可能なページをデザインしなければいけない。
クライアントPCが使用している回線
エンドユーザが、アナログのモデムや携帯電話を介してシステムにアクセスする場合、クライアント側のネットワークの容量がボトルネックになる。ここがボトルネックになる場合は、コンテンツの大きさを小さくすることが最大のポイントとなる。画像ファイルの大きさを小さくする、画像の圧縮率を上げる、htmlの冗長な記述を削るといった対策が考えられる。
開発時はLAN経由でアクセスするため、クライアント側の回線が細い場合のことを見落としがちである。コンテンツの転送に要する時間は、コンテンツの大きさ÷回線速度で容易に算出できる。エンドユーザの使用する回線の容量と、許容できる転送時間から、コンテンツの大きさの上限が決まるので、これを目安に不必要にサイズが多きいコンテンツは作らないようにして欲しい。
ボトルネックの見つけ方
ここでは、実際にどのようにしてボトルネックを見つけていくのかを解説する。まずは機器単位(ネットワーク機器やサーバマシン)で、性能を測定しどこがボトルネックになっているかを見極め、次のその機器のなにがボトルネックになっているかを見極めてゆく。
クライアントPCとブラウザ
WEBシステムの性能は二つの指標、「スループット」と「レスポンスタイム」で評価する。
- スループット=単位時間あたりにシステムが処理できる処理数
- レスポンスタイム=ひとつの処理に要する時間
スループットは1秒あたりどれだけブラウザにレスポンスをかえすことができるかをあらわし、レスポンスタイムはブラウザからリクエストを受けてからレスポンスの送信が終わるまでの時間をあらわす。
システムの負荷とスループットレスポンスタイムの間には図5-1のような関係がある。クライアントの数が増えると、それに比例してブラウザからのリクエスト数が増える。ある一定の値までは、レスポンスタイムはほとんど変わらず、スループットはクライアントの数に比例する(図のAの領域)。この領域ではシステムの性能に余裕がある。
ブラウザからのリクエスト数が増えて、ある臨界点を超えると、ブラウザからのリクエストが増えてもスループットは増加せず、レスポンスタイムが増加するようになる(図のBの領域)。この領域では、システムの性能限界点に達している。
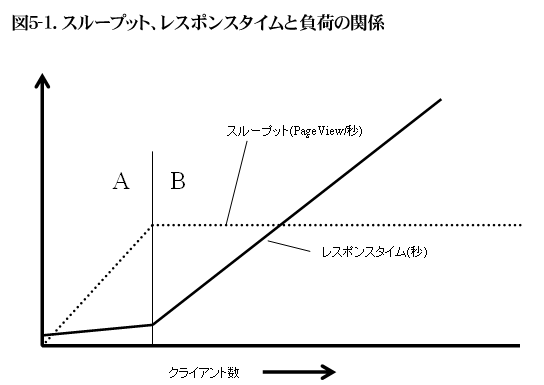
図5-1
レスポンスタイムとスループットはしばしば混同して用いられる。システムの性能が向上すると、図5-2のよう臨界点が矢印の方向に移動し、にスループットが向上、レスポンスタイムともに向上することから、スループットの増加 = レスポンスタイムの向上と捕らえてしまうことによる。スループットの増加 = レスポンスタイムの向上という関係はBの領域でしか成り立たないことに注意してほしい。
レスポンスタイムの向上を目指してチューニングを行う場合は、問題がAの領域で起きているのか、Bの領域にあるのかが重要である。図Aの領域でのレスポンスタイムが問題ならば、一つ一つのリクエストに対するレスポンスタイムを向上させるチューニングが必要であり、図Bの領域でのレスポンスタイムが問題なのであれば、システムの性能限界をあげるチューニングが必要となる。
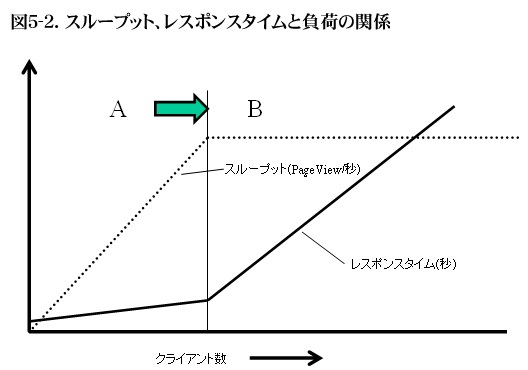
図5-2
図5-1、図5-2は理想的なシステムを想定しているが、実際のシステムの性能を測定してみると、図5-3のような形のグラフが得られることが多い。Aの領域では、クライアントの数に比例してスループットが向上するところは同じだが、臨界点に近づくに従ってスループットの向上が頭打ちになる。また、Bの領域では、スループットがクライアントの数によらず一定なのが理想なのだが、クライアントの数が増えるに従って、スループットが低下し、ついには処理が全く行えない状態になる。このようなシステムは負荷が過大にかかった状態に非常に弱い。
システムがしばしば、Bの領域で稼働するのならば、できるだけ図5-1に近いかたちで動作するようにチューニングをしなければいけない。
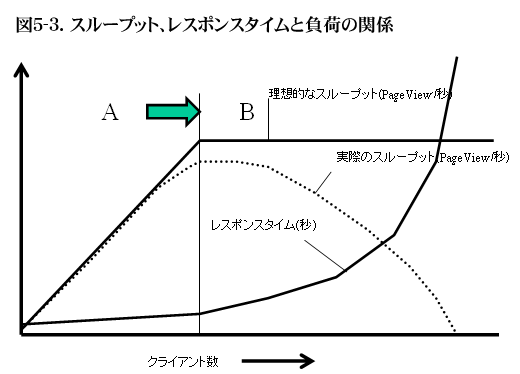
図5-3
WEBサーバ単体の性能の測定
まずはWEBサーバ単体の性能を測定する。図6のようにテスト用のクライアントとWEBサーバのみで試験を行う。ルータや、ファイヤーウォール等のネットワーク機器はテスト用クライアントとサーバの間に入れてはいけない。テスト用クライアントとサーバはクロスケーブルで接続するか、同一のハブに接続する。
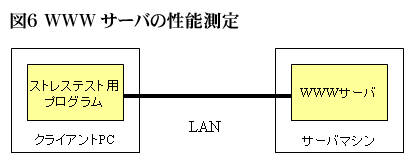
図6
WEBサーバには、htmlファイルや、イメージファイル等の静的なコンテンツを置き、テスト用クライアントからこれらのファイルに次々とHTTPのリクエストを出させたときの性能を測定する。テスト用のクライアントには、フリーソフトではJakrtaプロジェクトのJMeter、市販製品ではMercury Interactive社のLoadRunner等の負荷テストツールが使用できる。
テストツールは、コンフィグレーションに一台のPCで複数クライアントからのアクセスをエミュレートすることが可能なので、クライアント数を増加させていったときに、平均レスポンスタイムとスループットを測定し、測定結果から、図5のようなグラフを作成する。また、測定作業時に、クライアントPCと、サーバのCPU利用率、メモリ使用量と、LANのトラフィックの測定も行う。
CPU利用率の測定には、OSがWindow NT/2000であれば、パフォーマンスモニタを、OSがLinuxやUnixの場合は、sar, vmstatコマンドを使用するのが良いだろう。メモリ利用率は、物理メモリの利用率で判断を行う。仮想記憶を使用すれば物理メモリ以上のメモリを使用することも可能なのだが、ページングが頻発し大幅にパフォーマンスが劣化してしまうので、物理メモリに余裕がある状態で運用するのが基本である。物理メモリの利用率をみるのではなく、ページングがどの程度起きているかで、メモリが足りているかを判断しても良い。
LANのトラフィックの測定にはLANアナライザを使用する。ネットワーク系のボトルネックを判断するため、LANアナライザがあると便利である。LANアナライザが用意できない場合は、UNIXのsarコマンドや、WINDOWSのパフォーマンスモニタを使用してLANのトラフィックを測定する。
作成したグラフをみると、クライアント数が少ない間はスループットがクライアント数に比例し、クライアント数が増えるとスループットが頭打ちになるはずである。スループットが頭打ちになったときのスループット値、WEBサーバのCPU使用率、メモリ使用率、LANのトラフィックから、ボトルネックになる箇所と、WEBサーバの性能を判断する。
一通りのデータがそろったら図7のチャートに従って測定データを評価する。
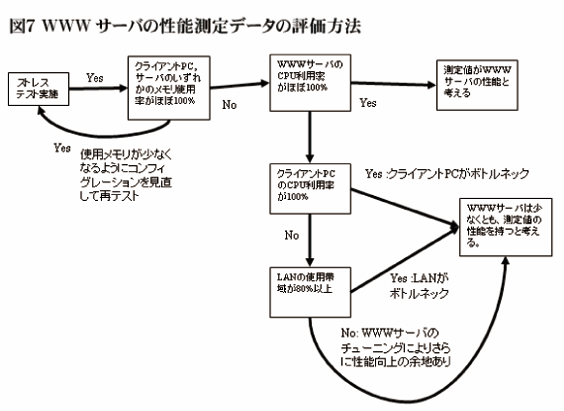
図7
まず、クライアントPCのメモリが不足した場合は、正しいデータ取得できていないので、より多くのメモリを積んだマシンを用意するなどして測定をやりなおす。
また、サーバ側のメモリが不足する場合は、ページングが頻発しWEBサーバは本来の性能が発揮できていないはずなので、より少ないメモリで動作するようにコンフィグレーションを変えて測定をやり直す。WEBサーバに限らず、メモリ不足は大幅なパフォーマンス劣化を引き起こすため、常にメモリに余裕がある状態を保つことは重要である。
次に、WEBサーバのCPU利用率をみる、WEBサーバのCPU利用率がほぼ100%であれば、スループットの測定値がWEBサーバの性能値であると判断する。WEBサーバのCPU利用率に余裕があり、クライアントPCのCPU利用率がほぼ100%になっているならば、クライアントPCの能力不足で、正しい測定が出来ていない。より高性能なクライアントPCを用意して性能を測定してもよいのだが、とりあえずは、WEBサーバは少なくとも測定値の性能を持つと考えて、再測定は行わない。
大抵のシステムでは、アプリケーションサーバかDBサーバがボトルネックになるため、アプリケーションサーバ/DBサーバの性能と比較してWEBサーバがボトルネックにならないことが確認できれば、正確なWEBサーバの性能を測定する必要はない。
また、インターネットに接続するシステムの場合、対インターネットの回線がボトルネックになることも考えられる。測定時のLANトラフィックが、対インターネットの回線容量より大きければ、対インターネットの回線がボトルネックとなるため、WEBサーバは十分な能力をもつと判断する。
WEBサーバ、クライアントPCのCPU利用率、およびLANのトラフィックすべてに余裕がある場合は、WEBサーバのオプションパラメータやOSカーネルパラメータのチューニングによりさらに性能が向上する余地があることを示している。ただし、WEBサーバの性能がボトルネックにならない限り、WEBサーバのチューニングは行わず、WEBサーバは少なくとも測定値の性能を持つと判断する。
SSL使用時のWEBサーバの性能測定
システムがHTTPSを使用し、SSLアクセラレータを使用しないのであれば、SSL使用時のWEBサーバの性能を測定する。HTTPではなくHTTPSを使用することを除けば、測定の方法は SSLを使用しないときのWEBサーバの性能の測定方法と変わらない。
SSLを使用すると猛烈にCPUリソースを消費するため、クライアントPC、サーバのどちらかのCPU利用率が100%になり、そこでスループットが頭打ちになるはずである。サーバのCPU利用率が100%であれば、それがWEBサーバのSSL使用時の性能と考える。クライアントPCのCPU利用率が100%になってしまった場合は、その時のサーバのCPU利用率からサーバの性能を見積もる。たとえば、クライアントPCのCPU利用率が100%の時、サーバのCPU利用率が33%ならば、SSL使用時のサーバの能力は測定値の3倍程度であると考える。
SSLアクセラレータを使用する場合は、クライアントPCのCPUリソースがボトルネックになり、SSL使用時のスループットの見積もりは難しい。とりあえずは、SSLアクセラレータの性能が十分高いと仮定し、SSL使用時でもSSLを使用しないときと同程度の性能が得られると考える。
ネットワーク機器を含めた性能の測定
つぎに、ルータやファイヤーウォールを実運用時と同じ構成に配置し、WEBサーバ単体での性能測定と同様の手順で性能の測定を行う。WEBサーバ単体での測定とほぼ同じ結果が得られれば、ネットワーク機器がボトルネックにはないと判断できる。また、WEBサーバ単体での測定値より低いスループットしか得られないのならば、ネットワーク機器がボトルネックになっていると考えられる。
この段階では、どのネットワーク機器がボトルネックになっているかを調べることはせず、性能値を記録することにとどめ、ネットワーク機器がシステム全体のボトルネックになっていると考えられる状況になったとき改めて、どのネットワーク機器がボトルネックになっているかを調べ対処する。
実践編
では、理論編で「チューニングの進め方」を学んだところで、実践編では文字通りそれらを「実践」してみることにしよう。ここではサンプルアプリケーションを実際にチューニングしてみる。チューニングを行っていく中で、システムのチューニングサイクルにおける具体的なポイントについて触れていきたい。
題材として、簡単な掲示板アプリケーションを取り上げる。このサンプルの稼動に必要なアプリケーション等は本誌付属のCDに収録されている。
サンプルアプリケーション説明
システム構成
今回チューニングを行ったシステムの構成を図11に示す。アプリケーションサーバにはBEAシステムズのWebLogic Server6.1、データベースには、WebLogic Serverに付属のcloudscapeデータベースの評価版を使用した。
図11からわかるように、チューニング対象のシステムは、シンプルで典型的なWEBシステムの構成である。負荷テストツールであるApache JMeterからHTTPリクエストをWEBサーバ兼アプリケーションサーバであるWebLogic Serverに送り、JDBCを介して、Cloudscapeデータベースを参照/更新し、レスポンスをクライアントに返す。
一般的な大規模サイトでは、クライアントとアプリケーションサーバ間にApacheなどのWEBサーバを設置する3層構成をとる場合が多い。負荷を分散させるとともに、静的コンテンツ等をWEBサーバに配置することにより、パフォーマンスの向上をはかるのである。今回は、WEBサーバ機能をWebLogic Serverサーバに兼任させたシンプルな構成をとる。
クライアントと、サーバは必ず別マシンにする構成をとることが重要である。JMeterが使用するリソースがサーバの性能を低下させることにより、アプリケーションの性能特性を正確に把握できなくなる為だ。
見落としがちであるが、負荷クライアントが使用するリソースは意外と大きいのだ。負荷テスト中は、サーバ側だけでなく、クライアント側のリソースの使用状況をチェックするのを忘れてはいけない。
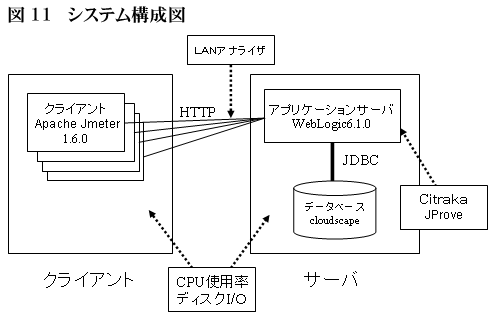
図11
アプリケーションの仕組み
サンプルアプリケーションは、WEB上のどこにでもあるような簡易掲示板である。1点通常の掲示板とは異なるのは、アップデート用のボタンが複数あるという点である。これらのボタンは、それぞれ返ってくる結果は同じであっても途中の処理が異なるのだ。それぞれにおける処理の詳細は後述する。
クラス図とシステム構成を組み合わせたアプリケーションの構成図を図12に示す。典型的なMVCモデルを取ったWEBアプリケーションである。処理フローは以下の通りだ。
- ブラウザからのオペレーションを受けた掲示板のJSPはリクエストをコントローラにあたるサーブレットであるHttpHandlerServletに渡す。
- HttpHandlerServletでは、JSPで選択された処理に対応するロジックを呼び出す。それぞれのロジックは、AbstractCommandという抽象クラスを継承している。このクラスには各処理に共通する処理が記述されたテンプレートメソッドを持つ。それぞれのロジックに特化した処理のみがAbstractCommandのサブクラスに記述されている。
- 掲示板JSPから受け取った、リクエスト(掲示板に投稿された書き込み)はバリューオブジェクトであるBbsを介してデータベースに格納される。参照/更新ともに、実際のデータベースアクセスはEntityMgrが行うことになる。
- クライアントへのレスポンスは、再びBbsオブジェクトを返して、掲示板Jspへと返され一連の処理は終了する。
AbstractCommandを継承した3つのサブクラスコマンド間における、処理の違いについて説明する。3つのコマンドは、顕著なパフォーマンスネックが引き起こされるようなロジックが故意に組み込まれている。3つのコマンドはそれぞれ以下の特徴がある。
- AllViewCommand
- 30件のデータを1回のSQL問い合わせで一括して取得する。
- OnceGetViewCommand
- 30件のデータを30回のSQL問い合わせで一件ずつそれぞれ取得するが、データベースコネクションの取得は一度だけでそのコネクションを一連の処理の中で使いまわす。
- EachGetViewCommand
- 30件のデータを30回のSQL問い合わせで、一軒ずつそれぞれ取得し、かつデータベースコネクションもそのつど取得する。
それぞれのコマンドには、掲示板への過去の投稿を取得する参照系の処理の他に、共通の処理として記事を投稿する更新系の処理が組み込まれている。
次章以降で、この単純な掲示板アプリケーションに負荷をかけ、解析を行いWebシステムのチューニングを行っていくことにする。実際のサンプルアプリケーションの構築方法はコラムを参照していただきたい。
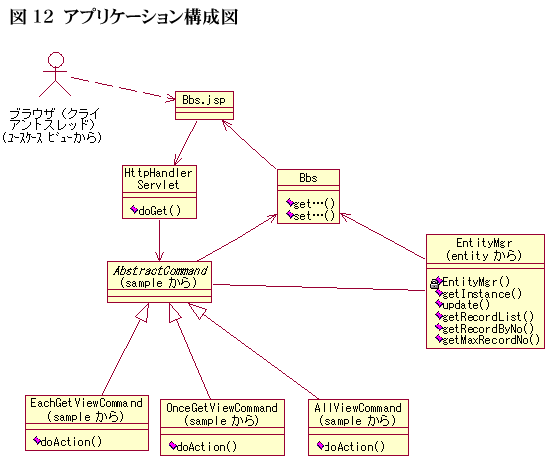
図12
テストツール
今回、サンプルアプリケーションシステムのチューニングを行うために以下のツールやコマンドを用いる。
- 負荷テストツール :Apache JMeter 1.6.0
- アプリケーションプロファイラ:Sitraka JProve Profiler
- Lan Analyzer
- netstatコマンド
- JVMのThread dump
Apache Jmeter
JMeterはJakartaプロジェクトにより提供される負荷テスト用のフリーのツールである。WEBシステムに負荷をかけるための各種設定が可能であるが、LoadRunnerなどの商用の負荷ツールと比較すると、各設定はシンプルであるといえる。しかし、オープンソースの100% pure Javaアプリケーションであるため、必要に応じてカスタマイズをすることが可能である。今回の記事の中では、JMeterの基本機能のみを使ってアプリケーションに負荷をかける。
今回は、現時点でのJMeterの最新版である1.6.0というバージョンを使用した。前バージョン(1.5.0)と比較すると、アーキテクチャが大幅に変更されユーザビリティが大幅に向上している。オペレーション中における設定時と実行時の境界がなくなった。これにより、1つの実行画面で設定とテストの両方の操作が行える。また、それに伴って複数のテスト間における設定の共有などが可能となった。
基本的に設定するのは以下の4点である。
- Thread Group
- Timer
- Controller
- Listener
図13がJMeterの基本操作画面である。
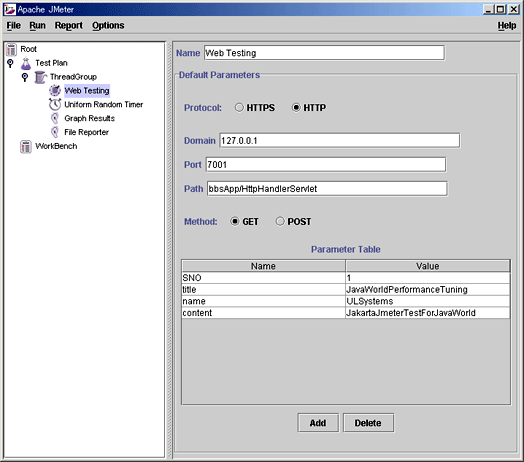
図13
Thread Group
Thread Groupには、並行に実行されるスレッド数を定義する。1つのスレッドは1つのブラウザなどのクライアントをエミュレートしたものと考えてよい。
1個のスレッドを100回シーケンシャルに実行することと、100個のスレッドを並行に動かすことは全く意味合いが異なることに注意しなければならない。1つのスレッドを1秒間に100回処理することが出来ても、100個のスレッドを1秒間にそれぞれ1回ずつ処理できるとは限らないのである。
Timer
Timerの設定画面では、テストクライアントとなるThread Groupに、テストを実行する際のアクセスのインターバルを設定する。インターバル間隔の設定は3種類のタイマーの中から選択する。
- Constant Timer
- 設定された一定の間隔でスレッドを実行する
- Uniform Random Timer
- 一定時間内にランダムな間隔で設定されたスレッドを実行する
- Gaussian Random Timer
- ガウス分布に基づいた分散した間隔で一定時間内に設定されたスレッドを実行する
設定されたインターバル内でスレッドにレスポンスが帰ってこない場合には、次の処理は実行されないということに注意が必要である。実際に並行に動くスレッドの個数はあくまでも、Thread Groupで設定した個数であるため、レスポンスタイムより短く、Delayを設定するのは無意味である。
Controller
実際にシステムにリクエストを送る対象・プロトコル・パラメータを設定する。WEBアプリケーションの負荷テストには、「Web Testing」を選択する。実際には、プロトコル(HTTP,HTTPS)、リクエストパス、ポート、メソッド(GET or POST)、リクエストパラメータなどを設定することになる。
今回のサンプルアプリケーションでは、HTTP上でGETメソッドにいくつかのリクエストパラメータを乗せてリクエストを送るだけの単純なコンフィグレーションでテストを行えるが、JMeterの機能としては、HTTPS・ベーシック認証・Cookieのコントロールをテストに組み込むことも可能である。また、本稿では割愛するが、対象Web Testingのほかに、JDBCやFTPの負荷テストの為のコンフィグレーションも選択可能である。
Listener
実行したテストの結果の出力を設定する。実行されたスレッドのレスポンスをグラフ化したり、返ってくるレスポンスの内容をテキストに打ち出したりすることが出来る。
負荷テストの結果は、ファイルへ結果を出力するFile Reporterや、グラフで視覚的に結果を表示するGraph Resultsを利用して取得するのが有効な場合が多いと思われるが、必要に応じて使い分ければよいであろう。
JMeterでは、コンフィグレーションを、Controller、Timerなどの個別の設定、あるいはThread Group全体の設定をファイルに保存しておくことが出来る。本サンプルで使用したコンフィグレーションファイルは、サンプルアプリケーションとともに収録しておく。
プロファイラ(JProbe Profiler)
JProve ProfilerはSitraka software のアプリケーションプロファイルツールである。アプリケーション実行中のある特定期間のサンプリングを行い、スナップショットを取得し、アプリケーションの内部での実行状態を解析する。
アプリケーション中におけるメモリリークやボトルネックの解析を行うことが出来る。解析したプロファイル情報をグラフィカルなインターフェイスで分析が可能だ。メソッド単位の呼び出し回数・処理時間の統計情報の取得が可能で、ソースコードとのマッピングも可能な強力なツールである。
LANアナライザ
ネットワークのトラフィックの計測にLANアナライザを使用する。代表的なものに、Snifferなどが挙げられる。しかし、ネットワークネックが生じるほどにスループットが出ている場合には、アプリケーションとしてはほとんど問題ない場合が多い。多くの場合は、ネットワークネックに到達する前に、CPUやメモリ、あるいはディスクI/Oネックとなる。
今回は、LANアナライザはネットワークがボトルネックになっていないことを確認するためだけに使用した。しかし、LANアナライザは、CPUもメモリも使用率が上がらないのにスループットが出ないなど、予期せぬ状況が発生した場合に全体のネットワークを再チェックする際などに重宝、システムする場合が多い。実際、ロードバランサーなどのネットワーク機器自体がボトルネックになっている場合も多いのである。
netstatコマンド
netstatはソケットの状態を標準出力に表示するという基本的なOSコマンドである。基本的なコマンドではあるが、Listenしているポートがきちんとコネクションを確立し、Establishの状態になっているかを確認することはシステムの状態をチェックする上で重要なポイントである。
例えば過負荷状態で、ポートがListen状態であるのに、コネクションが確立しない場合などには、OSレベルでのリソース(例えば、Accept_backlogなど)が不足している可能性があるなどの判断材料にもなりうる。また、Establish状態のコネクションの数からサーバに対する負荷のかかり具合を推測することが可能である。
スレッドダンプ
JVMのスレッドダンプは、各スレッドのスタックトレースを表示するものである。この情報からアプリケーションの状態について重要な情報を得られることが多い。VMのスレッドダンプを出力する方法はOSにより異なる。また、アプリケーションサーバ固有のスレッドダンプ出力処理機能を持つものもある。(WebLogic Serverにもアプリケーションサーバ固有のスレッドダンプ機能があるが、まだきちんと機能しないようだ)。
JVMのスレッドダンプは以下示すコマンドを、アプリケーション実行中に実行することにより簡単に取得することが出来るので試していただきたい。スレッドダンプ取得方法の代表的なものを示す。
- Windows NT
- コンソールで [control]+[break] を押す
- UNIX
- kill -3(QUIT) をJVMに送る
実際にはOSのディストリビューションなどにより異なることもあるので注意が必要である。
アプリケーションサーバのコンフィグレーションチューニングやOSレベルでのチューニングを一通り行っても、パフォーマンスがあがらない場合などでは、ロジックに問題がある場合が多い。不必要なsynchronized処理、デッドロックになる処理が組み込まれている場合などがそれに当たる。こういった問題は、前項に紹介したJProveなどのデバッグツールによっても原因の究明を行うことは可能であるが、まず、JVMのスタックとレースを取得することにより、原因の究明・問題の解決が出来ることも多い。JVMのスレッドダンプを出力し、処理が止まっている個所を特定するのである。
CPU・メモリの使用率に関して
CPUとメモリの使用率はWindowsのパフォーマンスメータを用いて確認した。本来、メモリ・CPUの使用率は不可テストの際に正確に記録しておくべきものである。しかし、今回はCPUに関しては、おおよそのCPU使用率を把握し、CPUの使用率が100%に達していないかどうかを監視する程度の計測に、メモリに関しては、メモリの使用率とともに、ページングが頻繁に起こることがないかをチェックする程度に簡略化した。
測定
では、実際に掲示板アプリケーションにJMeterで負荷をかけて、データを取得してみることにする。
まず、負荷クライアント数に対する、レスポンスタイム(Sec)とスループット(PaveView/Sec)の関係を取得してみる。それぞれの測定では、スレッド数と、アプリケーションサーバとデータベース間のJDBCコネクションプール数を変化させてデータを取得する。
変化させるファクタに実行スレッド数とJDBCコネクションプール数を選択した理由は、アプリケーションのロジックによるチューニングを除けば、アプリケーションサーバにとってとしては最も「ボトルネックになりやすい」ポイントであるからだ。しかし、逆にいえば、「最もボトルネックになりやすいポイント」は「最もチューニングの効くポイント」になりうるのである。
一般的に、アプリケーションサーバで、最もパフォーマンスに効くコンフィグレーションパラメータは、
- 実行スレッド数
- コネクションプール数
の2点である。
スレッド数
スレッド数は、アプリケーションサーバ内で実際にリクエストの処理に割り当てられ、並行に処理を出来るスレッドの数をあらわす。アプリケーションはこの「スレッド」が割り当てられることにより、処理を行うことが出来るのである。したがって、スレッド数の最適化、スレッドが並行に動けるようなチューニングは、必然的にパフォーマンスに大きな影響を与える。
コネクションプール数
コネクションプールはアプリケーションからデータベースへの接続を高速化する仕組みであり、今日では標準的な技術となっている。
詳細は理論編で述べられているのでそちらを参照いただきたい。詳細は割愛するが、簡単に言うと、コストのかかるコネクション取得処理を、必要になったときに、その都度取得するのではなく、あらかじめ何本かプールしておいて、その中からコネクションを必要とするスレッドに割り当てる、という技術である。
チューニングで扱うパラメータの「コネクションプール数」とは、アプリケーションから使用するために、あらかじめデータベースサーバとの間にプールしておくコネクションの数を指す。コネクションプールの機能は、WebLogic Serverのようにアプリケーションサーバに付属の機能を使うか、JDBC2.0オプションパックであるjavax.sqlパッケージを使うことにより実現できる。今回はWebLogic Serverのコネクションプール機能を使用した。
実行スレッド・コネクションプールという2つのパラメータの他に、WebLogic Serverに特化したパラメータとして、Native I/Oの使用・不使用の設定がある。アプリケーションサーバアプリケーションサーバ依存の設定ではあるが、非常に効くパラメータである。WebLogic Serverを使用する方は覚えておいておくとよいパラメータのひとつだ。詳細については、コラムを参照いただきたい。
ここに挙げた実行スレッド数・コネクションプール数・Native I/Oは、いずれも、WebLogic Serverの設定ファイルであるconfiig.xml直接書き換えるか、WebLogic Serverのコンソール画面からGUIでコンフィグレーションを行うことにより、設定を変更することが出来る。
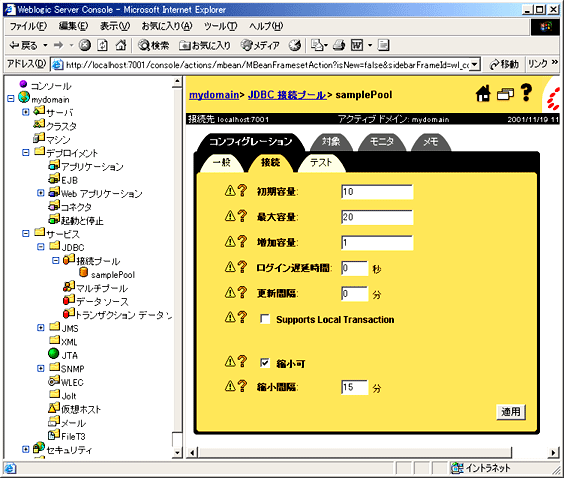
図14にconfig.xmlの例を示す。config.xmlを直接書き換えることにより設定を行う場合は、設定パラメータのMaxCapacityがコネクションプールの最大値、ThreadCountが実行スレッドの最大値、NativeIOEnabledがNative I/OのON・OFFにあたる。
WebLogic Server6.xでは、config.xmlで設定するほとんど全てのパラメータを、GUIから設定することが出来る。図14がWebLogic Serverコンソール画面のJDBCコネクションプール設定画面である。WebLogic Server自体はたいていの場合、デフォルトの設定で起動することが出来るので一度立ち上げて、設定コンソール画面から細かいコンフィグレーションを行うのも一つの手である。
図14 config.xmlの例
<!--コネクションプールの設定-->
<JDBCConnectionPool
CapacityIncrement="1"
DriverName="COM.cloudscape.core.JDBCDriver"
InitialCapacity="5"
MaxCapacity="20"
: JDBCコネクションの最大値
Name="samplePool"
Properties="user=none;server=none"
TestConnectionsOnRelease="false"
URL="jdbc:cloudscape:samplePool"/>
<!--実行スレッドの設定--></p>
<ExecuteQueue Name="default"
ThreadCount="5"
:並行に実行できるスレッド数
ThreadPriority="5"/>
<Server
ListenPort="7001"
NativeIOEnabled="true"
:NativeI/Oの有効化
ThreadPoolPercentSocketReaders="33" />図15 WebLogic Serverコンソール画面(JDBC)
コラム
Native I/O
Native I/Oの使用・不使用は、スレッドに関する設定の重要なファクタである。Native I/Oとは、簡単に言うと各OSプラットフォーム用に最適化されたソケットのコントローラである。
JVMのNative I/Oを使用していない場合には、設定したスレッド数のいくつかは、アプリケーションサーバ自体に使用される。実行スレッドのうちに、ソケットからメッセージを読み込む実行スレッドの割合を設定するパラメータがPercentSocketReaderである。基本的にはこのパラメータを増やすことにより、サーバの処理能力は上がるが、このパラメータの最適値は、OSやアプリケーションに依存するため、一概には言えない。
しかし、現在のJVMではほとんどの場合、Native I/Oを使用するほうが、パフォーマンス的によい場合が多い。筆者の経験では、Native I/Oを使用することにより、パフォーマンスが1.5倍強向上するケースもあった。また、Native I/Oを使用することによるバグなどの弊害は最近のJVMではほとんど聞かなくなった。Native I/Oの使用をONにし、PercentSocketReaderの設定を行わない設定をお勧めする(WindowsではデフォルトでNative I/OがONの設定になっている)。今回の測定もNative I/OをONにした状態で行った。
実際に測定する際の注意点であるが、負荷をかけてはじめてから2~3分後から測定を開始するようにする。WEBシステムでは、システムの初期稼動時には安定したパフォーマンスが得られないことが多いためだ。これは、JSPのコンパイルや、初回実行されるときに一度だけロードされるクラスのインスタンス化などに起因することが多い。
では実際の測定結果を見てみよう。
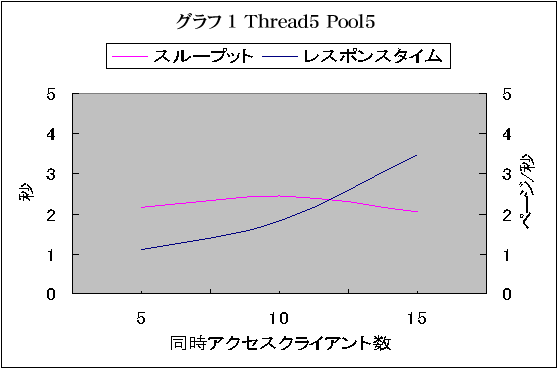
グラフ1
(実行スレッド:5 コネクション:5)
システムの性能に余裕がある場合には、同時アクセススレッド数に比例して、スループットは線形的に増加し、レスポンスタイムは変化しない。2倍のアクセスがあれば、2倍の秒間ページ閲覧数が得られるのが理想的なのである。
しかし、グラフ1を見るとクライアントスレッドが5から10に変化した時に、スループットは10%程度の伸びしかみせていない。また、レスポンスタイムは、クライアント数に比例してほぼ倍近い値になってしまっている。
このときのCPU使用率は60パーセント程度であった。このことから、WEBシステムは、システムのリソース的には余裕があるのだが、設定スレッド数が少ないため、十分なパフォーマンスを発揮できていない状態であると予想できる。
また、同時アクセスクライアント数が15になったときに、パフォーマンスがやや低下傾向にある。これは、アプリケーションが過負荷時にスムーズに動くことが出来ないためと考えられる。この場合だと、まだまだチューニングの余地が残っているといえる。
グラフ1
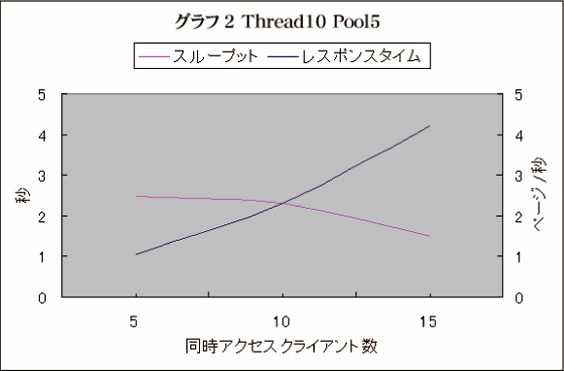
グラフ2
グラフ1の結果より、実行スレッド数が少ないためパフォーマンスが出ないのであろうと推測し、実行スレッドのみを10に増加した時のシステムの挙動を示した図がグラフ2だ。レスポンスタイムは特に変化がないが、スループットは逆にやや落ちている。
これは、実行スレッド数が5のときよりも多くのリクエストをアプリケーションサーバが同時に処理することは出来るのだが、結局DBサーバのコネクション取得でボトルネックが生じているために、全体のパフォーマンスがあがっていないのである。処理速度自体は上がらない一方で、実行スレッドを増やしたことにより、システムのリソースを消費しているために、結果としてグラフ1の実行スレッドが5のときよりもパフォーマンスがやや悪くなっていると予想される。
このときのCPU使用率も60~70%であった。スレッド数が5の時と同様に、アプリケーションサーバの処理能力がネックになって、システムのリソースを活用しきれていないのである。
グラフ1からグラフ2へのチューニング結果は、非常に単純なパターンではあるが、全体のバランスを考えずに、一部をチューニングしたために、結果としてシステム全体のパフォーマンスを落としている一つの例であるといえる。一箇所をチューニングしたらそこが引き金になって、他のボトルネックを生じるというのはよくあるパターンだ。局所的にチューニングをしながらも、常にシステム全体のパフォーマンスを把握することが大切である。
グラフ2
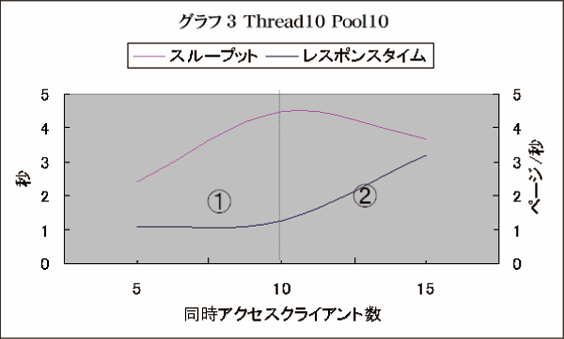
グラフ3
グラフ2に対して、コネクションプール数を実行スレッドと同じ10に設定し、システムに負荷をかけたときの挙動を示したものがグラフ3である。
クライアントスレッド数を5に設定したときと、10に設定したときでほとんどレスポンスタイムに変化はない(1)の領域)。一方スループットの方は、リクエストの数に対してリニアに増加している。これは、同時にリクエストを出してくるクライアントの数が5~10の状況であれば、サーバの処理能力にまだ余裕があるということを示している。実際、クライアントスレッド数が5の時、サーバのCPU使用率は60~70%であった。
このまま、同時アクセスクライアント数が、50あるいは100になっても、レスポンスタイムは遅くならず、スループットが伸びつづけてくれれば、すばらしいシステムであるが、データベースの更新・参照を行うといった処理のあるアプリケーションではそうはいかない。
更に負荷をかけて、クライアントスレッドが10を超えたあたりでCPUの使用率がほぼ100%になった。同時アクセスクライアントが15になると、スループットは下降をはじめ、レスポンスタイムは遅くなっている様子が見て取れる。このときCPU使用率は100%が続いていた。この掲示板システムは、同時アクセススレッド数が10を超えたあたりが、システムの性能限界点であると予想できる。
グラフ3はWebシステムに負荷をかけたときの典型的な挙動である。理論編の図5−1のグラフに近いことがわかるだろう。ある閾値までは、レスポンスタイムが一定で、スループットは線形的に増加する。しかし、一度閾値を超えると後は一方的にシステムのパフォーマンスは落ちて行くのである。
アプリケーションにCPU使用率が100%になるまで負荷をかけ、システムの性能特性を測定し、スレッド数とコネクションプール数のパラメータに、おおよその最適値を見出すことが出来たらチューニングは次の段階に進む。レスポンスタイムの曲線をより下方向に、スループットの曲線をより上方向に、レスポンスタイム・スループットの値が悪化し始める閾値のポイントをより、右方向(クライアントスレッドが多い方向)に持っていけるように、アプリケーション的、あるいはOSのパラメータなどのリソース的に、チューニングを更に次の段階へと進めていくのだ。
次の段階で、アプリケーションレベル、あるいはOSレベルでチューニングを行った後は、再びスレッド数、コネクションプール数の最適値をチェックする必要がある。この後に行われたチューニングによって、最も高いパフォーマンスの得られる設定値は、更に変化していることは十分に考えられる。理論編にも述べたが、チューニングとはこういったスパイラルな最適化の繰り返しなのでる。
グラフ3
では、スレッド数とコネクションプール数は多ければ多いほどよいのであろうか?答えは「NO」だ。
実行スレッドの設定値を過剰に設定しても、実際に並行に処理できるスレッドの数は、アプリケーションサーバが稼動するマシンの能力に依存するからである。過剰なスレッド数の設定はメモリなどのリソースを必要以上に消費し、結果として、パフォーマンスの低下をもたらす。コネクションプールの最大数の設定についても同様のことが言える。コネクションプールの保持もまた多くのリソースを消費するのである。一般的に、
実行スレッド数=コネクションプールの最大数+α
という設定がよいパフォーマンスをもたらす場合が多い。実行スレッド数とコネクションプール数は1対1でマッピングされるといった意味合いのものではない。しかし、アプリケーションロジックからデータベースコネクションまでが全くシームレスに処理されるような理想的環境であれば、コネクションプール数は実行スレッド数と同じ数必要になるからである。
では、その絶対値はいくつにすればよいのだろうか。筆者の経験上、100ページビュー/秒あるような大規模なサイトでも、実行スレッド・コネクションプールの設定数は多くて40程度だ。中規模程度のサイトでは設定数20前後で最もよいパフォーマンスが得られることが多い。これらは、あくまで目安の値であり、それぞれのアプリケーションに大きく依存する。例えば、外部のソケットを呼び出してしばらくレスポンスを待つような処理が含まれるような場合には、実行スレッドはコネクションプールに対して多く必要になるかもしれないのである。
アプリケーションサーバによってはコネクションプールの数を動的に変化させることが出来る。「立ち上げ時に5本、負荷がかかってきたら最大10本までコネクションプールを作る。」といった設定が可能だ。これにより、低負荷時に無駄にリソースを消費することを防げるのである。WebLogic Serverもそのような機能をもっている。しかし、システムを実際に運用する上では、
最小のコネクションプール数=最大のコネクションプール数
としておくべきである。コネクションプール数を動的に増加させること自体に多くのリソースが費やされるのである。最悪のケースでは、システムが過負荷状態の場合に、コネクションプールの作成自体が不可能になる場合がありうる。この設定は、これらのリスクを避け、安定したパフォーマンスを出すためにとる対策である。
JVMのスタックトレース
グラフ1と同じ条件のシステムに負荷をかけてパフォーマンスを測定し、レスポンスタイムが遅くなり、CPU使用率が100%になる辺りでスレッドダンプを取得してみた。
[Control]+[Break]を押下して取得したスレッドダンプからアプリケーションの実行状態を表す典型的なスタックトレースを図16に示す。
図16
(1)"ExecuteThread: '3' for queue: 'default'" daemon prio=5 tid=0x8b3cc28 nid=0x6f4
runnable [0x972f000..0x972fdbc]
at c8e.k.n.next(Unknown Source)
at weblogic.jdbc.pool.ResultSet.next(ResultSet.java:180)
at jw.sample.entity.EntityMgr.getMaxRecordNo(EntityMgr.java:123)
at jw.sample.entity.EntityMgr.getRecordList(EntityMgr.java:61)
at jw.sample.AllViewCommand.doAction(AllViewCommand.java:23)
at jw.sample.AbstractCommand.execute(AbstractCommand.java:63)
at jw.sample.HttpHandlerServlet.doGet(HttpHandlerServlet.java:27)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:740)
at weblogic.servlet.internal.ServletStubImpl.invokeServlet(ServletStubImpl.java:263)
at weblogic.servlet.internal.WebAppServletContext.invokeServlet(WebAppServletContext.java:2390)
at weblogic.servlet.internal.ServletRequestImpl.execute(ServletRequestImpl.java:1959)
at weblogic.kernel.ExecuteThread.execute(ExecuteThread.java:137)
at weblogic.kernel.ExecuteThread.run(ExecuteThread.java:120)
(2)"ExecuteThread: '0' for queue: 'default'" daemon prio=5 tid=0x8ad37f0 nid=0x700
waiting on monitor [0x966f000..0x966fdbc]
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:420)
at weblogic.kernel.ExecuteThread.waitForRequest(ExecuteThread.java:94)
at weblogic.kernel.ExecuteThread.run(ExecuteThread.java:118)図中(1)が実行されているスレッドのある瞬間のスタックトレースである。このスレッドは実際に稼動しているスレッドである。スタックトレースを追ってみると、HttpHandlerServletを呼び出し、実際にロジックが実装されているCommadを経由して、EntityMgrを介して、データベースに問い合わせを行い、検索結果をjava.sql.ResultSetで受けているところであることがわかる。実際には、その先のJDBCドライバーの内部クラスで処理が止まっているようだ。
参考に挙げるが、図中(2)に示されるスレッドは何もタスクがなく、実行待ちの状態になっていることを示している。こういったスレッドが多い場合には並行に実行されるようにチューニングしてやる必要がある。
アプリケーションのチューニング
前項までで、アプリケーションサーバアプリケーションサーバのパラメータチューニングがひとまず終わった。このシステムでは実行スレッド数、コネクションプール数がそれぞれ10の状態で同時アクセスクライアント数が10を超えると、アプリケーションサーバのCPUネックになるということがわかった。更なるチューニングを行うために、アプリケーション自体のロジック的なネックの究明と解析に入ろう。
JProveによるプロファイルの取得方法
ここでは、WebLogic Server上のアプリケーションのJProveによる簡単なプロファイリング方法を紹介する。JProveにはここに紹介する以外のたくさんの機能があるが、それらについては、マニュアルなどを参照いただきたい。
1. JProve上でWebLogic Serverを動かすためのパラメータ設定
プロファイルを行う対象アプリケーションの設定は、JProve Launch Padで行う。サーバサイドデバッグ用の設定画面がある(図17)ので、ここでWebLogic Server6.1を選択する。JProveの基本的な機能を使ってプロファイルを行うための設定としては、この設定画面で、WebLogic Serverを起動するときのJVMの引数と、アプリケーションが使うサーバ側クラスパスを設定するだけである。
JProveでは大きく分けて2つのプロファイル情報が得られる。パフォーマンス情報とヒープ情報だ。システム過負荷時に、ボトルネックになっているロジックを探し出すには、パフォーマンス情報を取得するとよい。
図17
2. スナップショットの取得
Launch Padで各種設定を行ったら、実行ボタンをクリックしてみる。JProve上でWebLogic Serverが立ち上がり、サーバ起動時のメモリヒープのサマリーグラフが現れれば正常に起動している。
JProve側ではパフォーマンス記録を開始し、ブラウザなどからプロファイル対象のアプリケーションを稼動する。任意のポイントでシステムのスナップショットを取ることが出来る。このスナップショットから、アプリケーション実行時のシステムの状態を解析するのである。
取得したスナップショットを選択したら、[メニュー]→[ツール]から「コールグラフ」を選択してみよう。システムの各スレッドが実行したメソッド、更にそのメソッドから呼び出されたメソッド・・・といった様に、メソッド同志の呼び出し関係が表されたグラフが表示される(図18)。グラフ中で色赤くなっているメソッドが測定中に負荷の高かったメソッドである。「負荷の高い」という基準は、設定により、呼び出し回数やオブジェクト数や実行時間などさまざまに変化させることが出来る。
グラフ中で赤くなっているメソッドの一つをさらにダブルクリックしてみると、図19のような画面が現れる。この画面は選択されたメソッドの先で呼ばれた処理についての統計だ。選択されたメソッドからさらに呼ばれたメソッドにおけるCPU使用時間や呼び出し回数の情報が得られるのである。実際にソースを追いかけて、メソッドのコールツリーをたどっていく必要はないのだ。必要であれば、統計情報の画面から、実際のソースコードへとクリック一つで飛べる機能も持っている。
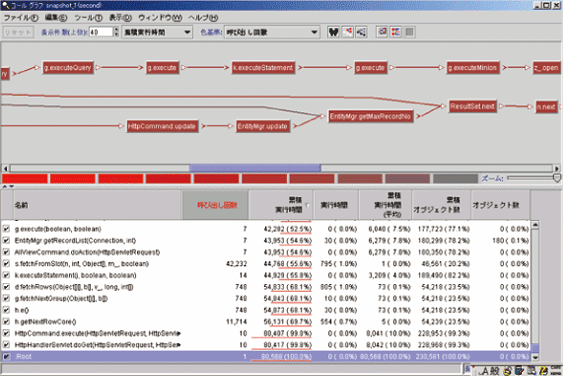
図18
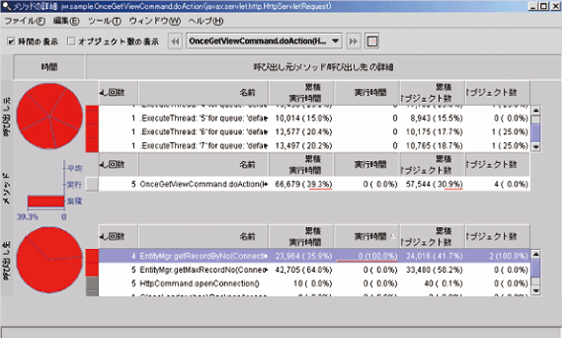
図19
3. データの解析
では、スナップショットの簡単な取得方法がわかったところで、掲示板アプリケーションの過負荷時のスナップショットを実際に取得して解析してみることにしよう。
負荷をかけてしばらくパフォーマンス記録を取得し、2~3分たったところでスナップショットを取得する。取得したスナップショットのコールグラフを開くと、最も処理に時間のかかったメソッドが赤で表示されるので、アプリケーション中のボトルネックが一目瞭然である(あるいは、画面下のメソッドリストで、実行時間ソートし、そちらで重い処理を見つける)。
さらに、チェックしたいクラスをダブルクリックすると、そのクラスから呼ばれたメソッドの実行時間や呼び出された回数の統計が取得できる。実際にやってみると非常に簡単で、かつ目的の情報に最短でたどり着ける事がわかるだろう。
スナップショットの解析
EachGetViewCommand実行時のスナップショットからパフォーマンスデータのコールグラフを表示してみる。このコマンドは、30件のデータを取得するために30回のSQL問い合わせを行い、その都度コネクションプールからコネクションを取得する処理を行うという処理が実装されている。
コールグラフでEachGetViewCommandのタブをダブルクリックして表れた統計を見てみると、コネクションを実際にコネクションプールから取得するjava.sql.Driver..connect()にほとんどの実行時間(72%)がとられていることがわかった。コネクションプール機能を使用していたとしても、相対的に見れば重たいコネクションの取得処理を、データベースを参照するたびに行っているためである。
さらに、データの取得も1件ずつ複数回行われるため、EntityMgrからのgetメソッドが冗長に呼ばれている(26%)。それらが重なって、大きなパフォーマンスロスを生じ、結果として、トータルの実行時間が極端に大きくなっている。
同様にOnceGetViewCommand実行時のパフォーマンス情報を取得してみた。このコマンドは、データの取得方法はEachGetViewCommandと同様に、合計30回のSQL問い合わせを行うのであるが、コネクションの取得が最適化されていて、一度取得したコネクションを一連の処理の間持ち回り使いまわすのである。そのため、java.sql.Driver.connect() メソッドにかかる処理時間は軽減されている。しかし、冗長なデータベースへの問い合わせ処理により、そのメソッドの実行回数が非常に多くなり、全体の処理時間が増加し、パフォーマンスに悪影響を与えていることがわかった。
OnceGetViewCommandでのCPU時間の9割以上が、実際のメインの処理であるデータベースレコードを取得するメソッドに使われていた。しかしデータベースからデータを取得するロジックがよくないために、スループットはそれほどあがらないのである。
そこで、データの取得方法を最適化したものが、AllViewCommandである。このコマンドでは、1回のSQL問い合わせで全てのデータを一度に取得する。コネクションプールからのコネクションの取得方法はOnceGetViewCommandと同様である。
このコマンドに負荷をかけた際の、スナップショットからコールグラフを見てみると、AllViewCommand使用時の大半のCPU使用時間は、新規に実装されたデータベースから複数のレコードを取得するメソッドに費やされているのであるが、呼び出し回数は当然他の2つのコマンドと比較して少なくなっている。それに伴い、全体の処理スピードがあがり、スループットが上がっているのである。
ここで例に挙げた、アプリケーションのロジックのチューニング内容自体に、大きな意味はない。なぜなら、これらのアプリケーションのロジックによる性能の劣化は、顕著な例を示すために故意に組み込んだものであり、実際にこのような単純なパターンはなかなかないものだ。
JProveのようなプロファイルツールを使うことによる大きなメリットは、アプリケーションのソースを追うことなく、時間のかかる処理、メモリリークなどを比較的簡単に発見できるという点である。さらには、全く仕様を知らないようなシステム、あるいは自分が全く開発に携わっていないようなシステムであっても、チューニングが容易だということだ。システムリリース直前に、アプリケーションのどこかにロジック的なミスがありそうな兆候を見つけたときに、巨大化したアプリケーションの中から、1点のロジックミスを見つける作業がいかに大変な作業であるかを、身をもって知っている読者も多いことだろう。
システムのパフォーマンスはボトルネックとなっている部分に大きく左右される。パフォーマンスを低下させるアプリケーションロジックは、その原因をつきとめられれば8割は解決したようなものである。Javaのプロファイリングツールは、その原因究明の大きな手助けになりうる場合が多いのだ。
パフォーマンスとのトレードオフ
パフォーマンスを挙げるために、システムの、あるファクタの性能や機能との間にトレードオフが起こるというのはよくあることだ。トレードオフの起こる対象はさまざまである。あるときは、汎用性であったり、あるときは移植性であったり、コードの美しさであったりする。
今回のサンプルアプリケーションでも、作成中にパフォーマンスと移植性とのトレードオフが生じた。サンプルアプリケーションは当初、データベースからコネクションを取得する際にDataSourceを使い、JNDIツリーから、使用するデータベースプールをルックアップして探し出す作りにしていた。しかし、実際に負荷をかけてみると、性能が全く出なかった。そこでJProveでスナップショットを取ってみると、多くのCPU時間が、JNDIツリーのルックアップ処理にかかっている事がわかった。
データベースコネクションプールをJNDIツリーに登録し、アプリケーション側では、それをLookupするという作りにするメリットは、JNDIを介することによって、アプリケーションを環境に依存しない作りに出来ることにある。つまり、コネクションプールのURIや使用するJDBC Driverをカプセル化し、それを使うアプリケーション側では意識することなく、コーディングが出来るようになるというメリットが得られるのである。
しかし、今回の様にデータベースを一度参照更新するだけのアプリケーションでは、そのコストが全体の処理の中に占める割合が大きかったため、DataSourceを使うことによる移植性等のメリットを捨て、パフォーマンスを上げるということを選択した。
このように、移植性や汎用性など、何らかのファクタとトレードオフにシステムのボトルネックとなっている部分をチューニングすることにより、パフォーマンスを優先するというのも一つの選択肢なのである。このような場面は意外と多い。筆者の経験では、あるEJBの処理が余りに重いため、その処理のみコEJBのもつコンポーネント性を犠牲にして、ストアドプロシジャーを使ったというシステムがあった。
問題が起きたときや、システムの要件が変わったときに適切に対応が出来るように、常に現在システムが出せるパフォーマンスの値や、アプリケーションのどこにネックがあるかをきちんと把握していることが大事なのである。そうすることによって、必要なときに適切な対策が取れるのだ。
最後に
実践編で、非常に小規模ではあるが実際にシステムのチューニングをしてみて、「チューニングはどのように行われていくの?」というところの全体像がなんとなくつかめただろうか?どれも一つ一つを取ってみると、それほど敷居の高いことではなく、どれも実践できそうなものであったことだろう。
チューニングで大切なことは
- 測定→究明→対策のスパイラルな繰り返し
- 正しい測定をすること
- システム全体の性能特性を把握する
であると筆者は考える。正しいチューニングを行えば、システムは確実に早くなるはずだ。
サンプルプログラムの動かし方
サンプルアプリケーションのディレクトリ構成等は、サンプルディレクトリ直下のreadme.txtを参照いただきたい。サンプルアプリケーションを構築するには以下の作業が必要だ。
データベースの作成
データベースはWebLogic Server評価版に付属のCloudscapeの評価版を使用するのが最も手軽である。今回の記事の中でもこのcloudscapeデータベースを使用した。もちろんOracleなど他のデータベースを使用することも可能だ。
Cloudscapeのデータベースインスタンスと表を作成するには、テーブルを作るSQL文を記述した定義ファイルを、コマンドラインユーティリティによって起動する。この際、Cloudscapeに関連するいくつかのjarファイルをクラスパスに通さなければならない。環境設定のために、サンプルアプリケーション直下のsetEnv.cmdを編集し、以下の2行を設定する。
- JAVA_HOME:jdkのインストールディレクトリ
- WL_HOME:WebLogic Serverのインストールディレクトリ
WebLogic Serverがデフォルトインストール状態であれば、
JAVA_HOME=c:beajdk131
WL_HOME=c:beawlserver6.1
となる。この2つのパラメータをセットし、コマンドラインからsetEnv.cmdを実行することにより、環境変数がセットされる。環境変数がセットされたら、データベースの作成に移る。コマンドラインから以下のコマンドを入力する。
WebLogic Serverがデフォルトインストール状態であれば、
$ java utils.Schema pool-url;create=true
COM.cloudscape.core.JDBCDriver [定義ファイル]
するとデータベースが作成される。サンプルアプリケーションを動かすためのテーブルを作る定義ファイルは、dataディレクトリの下のsample.ddlである。
WEBアプリケーションの作成
アプリケーションのコンパイルとWEBアプリケーションの作成を行う。サンプルアプリケーションのbinディレクトリに配置されているbuild.batを動かすと、
- 環境変数の設定
- アプリケーションのコンパイル
- web.xml,weblogic.xmlの生成
- アプリケーションアーカイブの作成
- WebLogicドメインのアプリケーションディレクトリへアーカイブの配置
が、行われる。WebLogic Serverがデフォルトインストール状態である場合には、問題なくbbsApp.warというファイル名のウェブアプリケーションが作成されるはずである。それぞれの処理で行った、処理の詳細はbuild.batの中身を参照いただきたい。
サーバのコンフィグレーション
アプリケーションサーバのコンフィグレーションは、起動するWebLogicドメインのホームディレクトリ(デフォルトではc:beawlserver6.1configmydomain)直下のconfig.xmlに記述する。WebLogic Server自体は、デフォルトのconfig.xmlのままで起動が可能であるが、サンプルアプリケーションを動かすためには、
- コネクションプールの作成
- WEBアプリケーションのデプロイ
の設定を追加する必要がある。サンプルアプリケーション用のコンフィグレーションファイルが、config.xmlとして収録されている。この中から必要な部分を抜粋してマージするか、あるいは、丸ごと置き換えることで、設定が完了する。
また、これらの設定は、WebLogic Server起動後のconsole画面からも設定が可能だ。コンソール画面は
http://hostname:7001/console でアクセス可能だ。"Hostname"の部分にはWebLogic Serverが起動しているマシンのIPアドレスあるいはホスト名をいれればよい。
WebLogic Serverの起動
デフォルトのインストール状態でも、起動するWebLogicドメインのstartWebLogic.cmdを実行することにより、WebLogic Serverを起動することが可能だ。しかし、cloudscapeデータベースを使うためには、クラスパスとデータベースホームディレクトリの設定が必要になる。こちらも、サンプルアプリケーションのbinディレクトリのstartWebLogic.cmdを使用する、それらが設定された状態でサーバを起動することができるので、利用していただきたい。
WebLogic Serverが起動したら、早速アクセスしてみよう。http://hostname:7001/bbsApp/bbs
で掲示板の画面が現れたら成功だ。
JMeterで負荷をかけ、サーバのパラメータを最適化し、スレッドダンプやProfilerといったツールを用いてシステムの性能特性を測定し、解析を行いシステムをチューニングを実際にしてみよう。今回記事の中で扱ったいかのアプリケーションは付属のCD-ROMに収録されている。
- WebLogic Server6.1
- Apache JMeter 1.6.0
- Sitraka JProve 3.0
- 注1:アクセスあたり10Kbyteのデータが流れるとして、毎秒100のアクセスに対応するには、8MBPSの回線が必要。